Meta 的 Llama 3.2:AI 迎来视觉新纪元
Meta 在 Connect 大会上发布了 Llama 3.2,这款强大的语言模型不仅能理解文字,更能“看懂”图像,标志着 AI 迈向多模态理解的新里程碑。
Llama 3.2 提供了不同尺寸的模型,包括 110 亿和 900 亿参数的视觉模型,以及更轻量级的纯文本模型,可轻松部署在移动设备和边缘设备上。
Meta CEO 马克·扎克伯格在开场演讲中强调:“这是我们首个开源的多模态模型,将为需要视觉理解的应用打开无限可能。”
Llama 3.2 延续了其前代的优势,拥有 128,000 个 token 的上下文长度,这意味着用户可以输入大量文本,甚至可以达到数百页教科书的规模。更大的参数量也意味着模型将更加准确,能够处理更复杂的任务。
Meta 首次发布了 Llama 堆栈的官方发行版,开发者可以在各种环境中使用这些模型,包括本地部署、设备端、云端和单节点部署。
扎克伯格表示:“开源将成为——事实上已经成为——最具成本效益、可定制、可信赖和高性能的选择。我们已经到达了行业拐点,开源正逐渐成为行业标准,可以称之为 AI 领域的 Linux。”

Llama 3.2 的发布距离 Llama 3.1 仅仅两个多月,Meta 表示该模型的增长速度已经达到了 10 倍。
扎克伯格强调:“Llama 正在快速发展,不断解锁新的能力。”
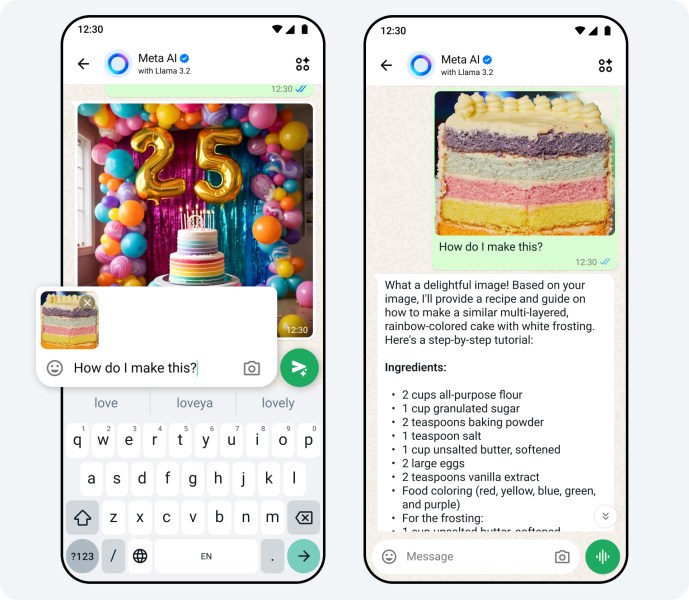
Llama 3.2 的两个最大模型(110 亿和 900 亿参数)支持图像用例,能够理解图表和图形,为图像添加标题,并根据自然语言描述识别图像中的物体。例如,用户可以询问公司在哪个月份的销售额最高,模型可以根据提供的图表进行推理并给出答案。更大的模型还可以从图像中提取细节,生成图像描述。
与此同时,轻量级模型可以帮助开发者在私密环境中构建个性化的代理应用程序,例如总结最近的消息或发送会议邀请。
Meta 表示,Llama 3.2 在图像识别和其他视觉理解任务方面与 Anthropic 的 Claude 3 Haiku 和 OpenAI 的 GPT4o-mini 相当。此外,它在指令遵循、摘要、工具使用和提示重写等方面优于 Gemma 和 Phi 3.5-mini。
Llama 3.2 模型可以在 llama.com 和 Hugging Face 上下载,以及 Meta 的合作伙伴平台。
Meta 还宣布扩展其商业 AI,企业可以使用 WhatsApp 和 Messenger 上的点击式消息广告,并构建能够回答常见问题、讨论产品细节和完成购买的代理。
Meta 声称,超过 100 万广告主使用其生成式 AI 工具,上个月有 1500 万个广告使用这些工具创建。Meta 报告称,与未使用生成式 AI 的广告活动相比,使用 Meta 生成式 AI 的广告活动平均点击率提高了 11%,转化率提高了 7.6%。
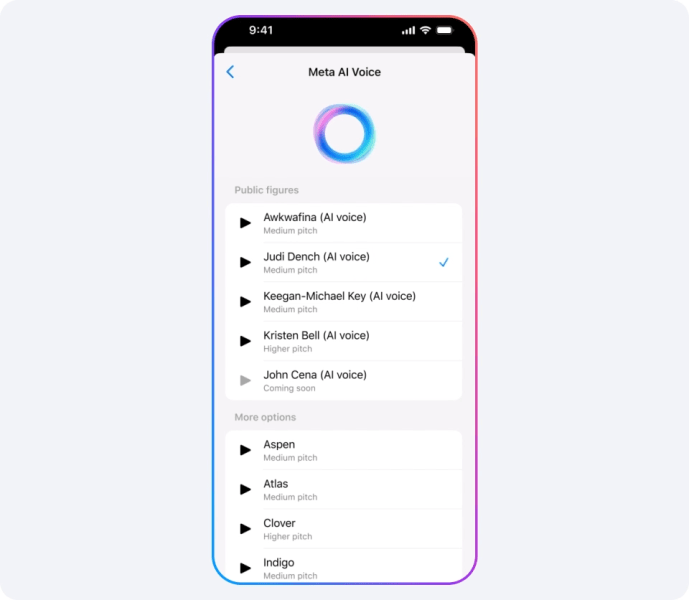
最后,对于消费者而言,Meta AI 现在有了“声音”——或者更确切地说,是多种声音。新的 Llama 3.2 支持 Meta AI 中的多模态功能,最值得注意的是,它能够用名人声音进行回复,包括 Dame Judi Dench、John Cena、Keegan Michael Key、Kristen Bell 和 Awkwafina。
扎克伯格在主题演讲中表示:“我认为,声音将成为比文本更自然的人机交互方式,它更出色。”
该模型将在 WhatsApp、Messenger、Facebook 和 Instagram 上以名人声音回复语音或文本命令。Meta AI 还能够回复聊天中分享的照片,添加、删除或更改图像,以及添加新的背景。Meta 表示,他们还在探索 Meta AI 的新翻译、视频配音和唇形同步工具。
扎克伯格自豪地表示,Meta AI 有望成为世界上使用最广泛的助手——“它可能已经做到了。”