

订阅我们的每日和每周新闻简报,获取有关行业领先人工智能报道的最新更新和独家内容。了解更多
为大型语言模型 (LLM) 注入超越其训练数据的知识,是企业应用领域的重要课题。
将领域和客户特定的知识融入 LLM 的最常见方法是使用检索增强生成 (RAG)。然而,在许多情况下,简单的 RAG 技术并不足以满足需求。
构建有效的基于数据增强的 LLM 应用需要仔细考虑多个因素。在最近的一篇论文中,微软的研究人员提出了一种框架,用于根据所需外部数据的类型和推理的复杂性对不同类型的 RAG 任务进行分类。
研究人员写道:“基于数据增强的 LLM 应用并非一劳永逸的解决方案。现实世界的需求,尤其是在专业领域,非常复杂,它们与给定数据的关系以及所需的推理难度可能存在很大差异。”
为了应对这种复杂性,研究人员提出了基于所需外部数据类型和生成准确且相关响应所涉及的认知处理的四级用户查询分类:
– 明确事实:需要从数据中检索明确陈述的事实的查询。
– 隐含事实:需要推断数据中未明确陈述的信息的查询,通常涉及基本推理或常识。
– 可解释的理由:需要理解和应用外部资源中明确提供的特定领域理由或规则的查询。
– 隐藏的理由:需要发现和利用数据中未明确描述的特定领域推理方法或策略的查询。
每级查询都提出了独特的挑战,需要特定的解决方案来有效地解决它们。
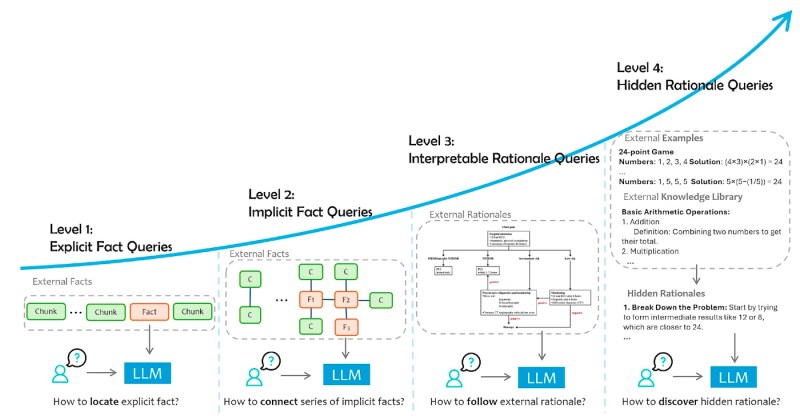 基于数据增强的 LLM 应用的类别
基于数据增强的 LLM 应用的类别
明确事实查询是最简单的类型,专注于从提供的数据中检索直接陈述的事实信息。研究人员写道:“这一级别的定义特征是对特定外部数据片段的明确和直接依赖。”
解决这些查询最常见的方法是使用基本的 RAG,其中 LLM 从知识库中检索相关信息并使用它来生成响应。
然而,即使是明确事实查询,RAG 管道在每个阶段都面临着若干挑战。例如,在索引阶段,RAG 系统创建可稍后作为上下文检索的数据块存储,它可能需要处理大型非结构化数据集,其中可能包含多模态元素,如图像和表格。这可以通过多模态文档解析和多模态嵌入模型来解决,这些模型可以将文本和非文本元素的语义上下文映射到共享的嵌入空间中。
在信息检索阶段,系统必须确保检索到的数据与用户的查询相关。在这里,开发人员可以使用提高查询与文档存储对齐的技术。例如,LLM 可以为用户的查询生成合成答案。答案本身可能不准确,但它们的嵌入可以用来检索包含相关信息的文档。
在答案生成阶段,模型必须确定检索到的信息是否足以回答问题,并在给定上下文与其自身内部知识之间找到合适的平衡。专门的微调技术可以帮助 LLM 学习忽略从知识库中检索到的不相关信息。检索器和响应生成器的联合训练也可以带来更一致的性能。
隐含事实查询要求 LLM 不仅简单地检索明确陈述的信息,还需要进行一定程度的推理或推论来回答问题。研究人员写道:“这一级别的查询需要从集合中的多个文档中收集和处理信息。”
例如,用户可能会问“公司 X 在上个季度销售了多少产品?”或“公司 X 和公司 Y 的策略之间主要区别是什么?”回答这些问题需要结合知识库中多个来源的信息。这有时被称为“多跳问答”。
隐含事实查询带来了额外的挑战,包括需要协调多个上下文检索以及有效地整合推理和检索能力。
这些查询需要高级 RAG 技术。例如,像 Interleaving Retrieval with Chain-of-Thought (IRCoT) 和 Retrieval Augmented Thought (RAT) 这样的技术使用思维链提示来根据先前回忆的信息指导检索过程。
另一种很有前景的方法是将知识图谱与 LLM 相结合。知识图谱以结构化格式表示信息,这使得执行复杂推理和链接不同概念变得更容易。图 RAG 系统可以将用户的查询转换为包含来自图数据库中不同节点的信息的链。
可解释的理由查询要求 LLM 不仅理解事实内容,还需要应用特定领域的规则。这些理由可能不存在于 LLM 的预训练数据中,但它们也不难在知识语料库中找到。
研究人员写道:“可解释的理由查询代表了依赖外部数据来提供理由的应用程序中一个相对简单的类别。这些类型查询的辅助数据通常包括对用于解决问题的思维过程的清晰解释。”
例如,客户服务聊天机器人可能需要将处理退货或退款的文档化指南与客户投诉提供的上下文相结合。
处理这些查询的关键挑战之一是将提供的理由有效地整合到 LLM 中,并确保它能够准确地遵循这些理由。提示微调技术,例如使用强化学习和奖励模型的技术,可以增强 LLM 遵守特定理由的能力。
LLM 也可以用来优化它们自己的提示。例如,DeepMind 的 OPRO 技术使用多个模型来评估和优化彼此的提示。
开发人员还可以使用 LLM 的思维链推理能力来处理复杂的理由。然而,为可解释的理由手动设计思维链提示可能很耗时。像 Automate-CoT 这样的技术可以帮助自动化此过程,方法是使用 LLM 本身从少量标记数据集创建思维链示例。
隐藏的理由查询提出了最重大的挑战。这些查询涉及特定领域的推理方法,这些方法在数据中没有明确说明。LLM 必须发现这些隐藏的理由并将其应用于回答问题。
例如,模型可能可以访问包含解决问题所需知识的隐含历史数据。模型需要分析这些数据,提取相关模式,并将它们应用于当前情况。这可能涉及将现有解决方案应用于新的编码问题,或使用先前法律案件的文档来推断新的法律案件。
研究人员写道:“导航隐藏的理由查询……需要复杂的分析技术来解码和利用嵌入在不同数据源中的潜在智慧。”
隐藏的理由查询的挑战包括检索与查询在逻辑上或主题上相关的,即使在语义上不相似的信息。此外,回答查询所需的知识通常需要从多个来源进行整合。
一些方法使用 LLM 的上下文学习能力来教它们如何从多个来源选择和提取相关信息,并形成逻辑理由。其他方法侧重于为少样本和多样本提示生成逻辑理由示例。
然而,有效地解决隐藏的理由查询通常需要某种形式的微调,尤其是在复杂的领域。这种微调通常是特定于领域的,并且涉及在能够让 LLM 对查询进行推理并确定它需要哪种外部信息的示例上训练 LLM。
微软研究院团队编制的调查和框架表明,LLM 在使用外部数据进行实际应用方面取得了多大的进步。然而,这也提醒我们,许多挑战尚未解决。企业可以使用此框架,在将外部知识整合到其 LLM 中时做出更明智的决策。
RAG 技术可以有效地克服普通 LLM 的许多缺点。然而,开发人员还必须意识到他们使用的技术的局限性,并知道何时升级到更复杂的系统或避免使用 LLM。





