

亚马逊的AI购物助手Rufus:让购物更智能
在实体店里,我们习惯于向店员咨询各种问题,例如“冬天打高尔夫需要哪些装备?”、“徒步鞋和跑步鞋有什么区别?”、“五岁孩子最喜欢的恐龙玩具有哪些?”。然而,在网购时代,如何获得类似的购物建议呢?
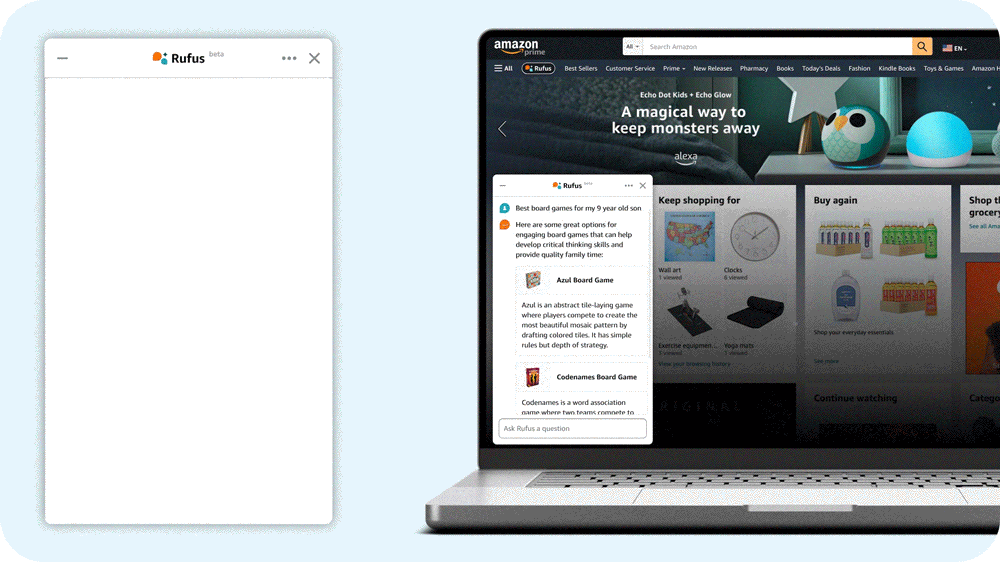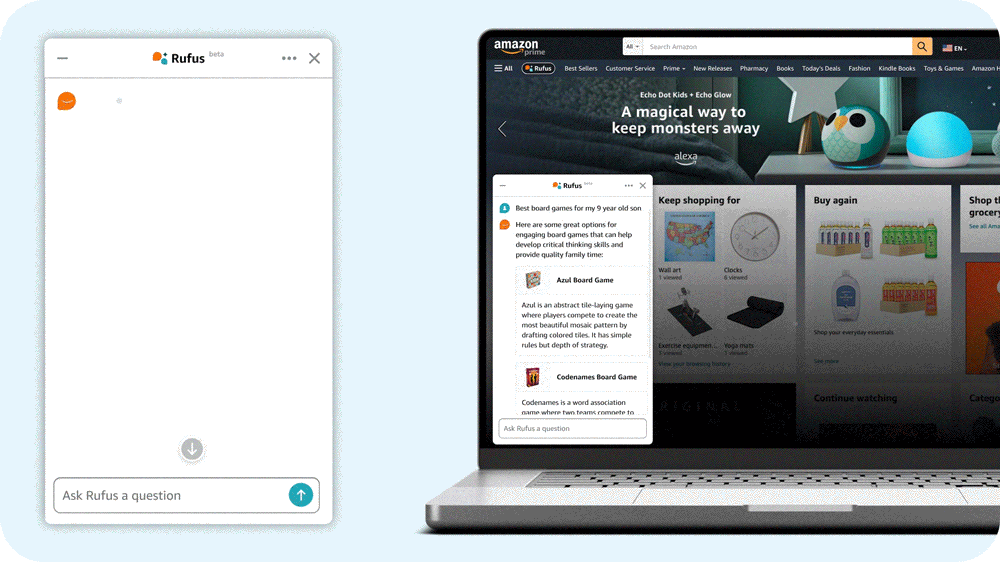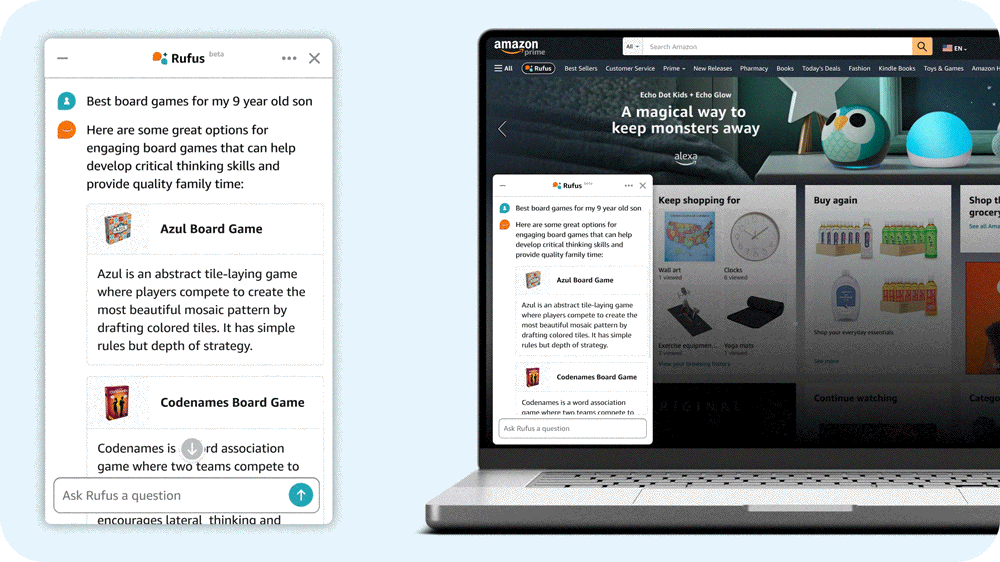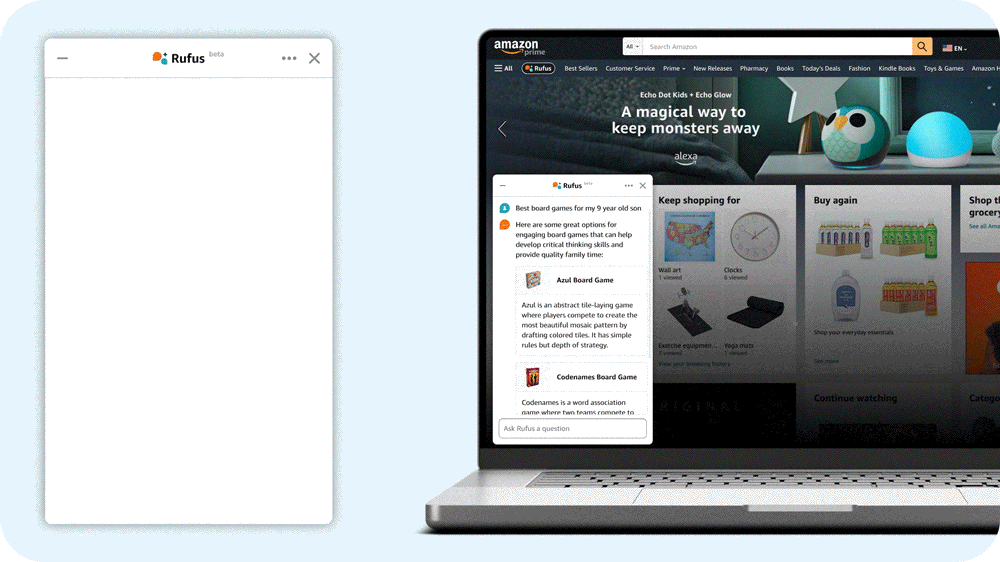
亚马逊的答案是Rufus,一个由生成式AI驱动的购物助手。Rufus通过在亚马逊应用程序中回答各种问题,帮助用户做出更明智的购物决策。用户可以获取产品详情、比较不同选项,并获得产品推荐。
我领导着开发Rufus背后的强大语言模型(LLM)的科学家和工程师团队。为了打造一个真正有用的对话式购物助手,我们在生成式AI的多个方面采用了创新技术。我们构建了一个专门针对购物的定制LLM;利用检索增强生成技术,整合了各种新颖的证据来源;利用强化学习来改进响应;在高性能计算方面取得进展,提高了推理效率并降低了延迟;并实施了新的流式架构,让购物者更快地获得答案。
Rufus如何获取答案
大多数LLM首先在广泛的数据集上进行训练,以赋予模型整体知识和能力,然后针对特定领域进行定制。这对于Rufus来说并不适用,因为我们的目标是从一开始就用购物数据对其进行训练——包括整个亚马逊商品目录、客户评论以及社区问答帖子。因此,我们的科学家构建了一个定制LLM,它在这些数据源以及网络上的公开信息的基础上进行训练。
为了能够回答各种各样的问题,Rufus必须超越其初始训练数据,获取新的信息。例如,要回答“这个锅可以放洗碗机吗?”这个问题,LLM首先解析问题,然后确定哪些检索来源可以帮助它生成答案。
我们的LLM使用检索增强生成(RAG)从已知可靠的来源获取信息,例如产品目录、客户评论和社区问答帖子;它还可以调用相关的亚马逊商店API。我们的RAG系统非常复杂,既因为使用了各种数据源,也因为每个数据源根据问题的不同而具有不同的相关性。
每个LLM,以及生成式AI的每种应用,都是一个不断完善的过程。为了让Rufus随着时间的推移变得更好,它需要学习哪些响应是有帮助的,哪些可以改进。客户是提供这些信息的最佳来源。亚马逊鼓励客户向Rufus提供反馈,告诉模型他们是否喜欢或不喜欢答案,这些反馈将用于强化学习过程。随着时间的推移,Rufus从客户反馈中学习,并改进其响应。
专为Rufus打造的芯片和处理技术
Rufus需要能够同时与数百万客户互动,而不会出现任何明显的延迟。这尤其具有挑战性,因为生成式AI应用程序非常计算密集,尤其是在亚马逊的规模下。
为了最大限度地减少生成响应的延迟,同时最大限度地提高系统能够处理的响应数量,我们采用了亚马逊的专用AI芯片Trainium和Inferentia,它们与核心亚马逊网络服务(AWS)集成。我们与AWS合作,对优化模型推理效率进行了优化,这些优化随后提供给所有AWS客户。
但是,标准的用户请求批处理方法会导致延迟和吞吐量问题,因为很难预测LLM在撰写每个响应时会生成多少个标记(在本例中,是文本单位)。我们的科学家与AWS合作,使Rufus能够使用连续批处理,这是一种新颖的LLM技术,使模型能够在批处理中的第一个请求完成后立即开始服务新请求,而不是等待批处理中的所有请求完成。这种技术提高了AI芯片的计算效率,使购物者能够快速获得答案。
我们希望Rufus能够为任何给定的问题提供最相关和最有帮助的答案。有时这意味着长篇文本答案,但有时是短篇文本,或者是一个指向商店的点击链接。我们必须确保呈现的信息遵循逻辑流程。如果我们没有正确地对信息进行分组和格式化,最终可能会得到一个令人困惑的响应,这对客户来说没有太大帮助。
这就是为什么Rufus使用高级流式架构来提供响应。客户无需等待长答案完全生成——相反,他们可以在答案的其余部分生成时获得答案的第一部分。Rufus通过向内部系统发出查询来填充流式响应中的正确数据(称为水化)。除了生成响应的内容之外,它还生成格式化指令,指定如何显示各种答案元素。
尽管亚马逊已经使用AI超过25年,以改善客户体验,但生成式AI代表着一种新的、变革性的东西。我们为Rufus感到自豪,以及它为我们的客户提供的全新功能。





