数据是AI的圣杯,但如何有效利用却是一大难题
从敏捷的初创公司到全球巨头,各行各业都在投入巨资,以构建高效的AI应用和系统。然而,现实情况是,获取和利用来自不同来源、跨越文本、视频、音频等多种模态的数据,远非易事。这需要多层工作和集成,往往导致延误和错失商机。
总部位于加州的ApertureData应运而生。为了解决这一挑战,这家初创公司开发了统一的数据层ApertureDB,它将图数据库和向量数据库的强大功能与多模态数据管理相结合。这帮助AI和数据团队比以往更快地将应用推向市场。
ApertureData今天宣布获得825万美元种子轮融资,同时发布了其图向量数据库的云原生版本。
ApertureData创始人兼首席执行官Vishakha Gupta表示:“ApertureDB可以将数据基础设施和数据集准备时间缩短6-12个月,为首席技术官和首席数据官提供巨大的价值,他们现在需要在数据需求冲突的极不稳定的环境中制定成功的AI部署策略。”她指出,该产品可以将构建多模态AI的数据科学和机器学习团队的生产力平均提高十倍。
许多组织发现,管理不断增长的多模态数据堆积——每天数TB的文本、图像、音频和视频——是利用AI提升性能的瓶颈。
问题不在于缺乏数据(非结构化数据的数量一直在增长),而在于将数据投入高级AI所需的工具生态系统过于分散。
目前,团队必须从不同的来源获取数据,并将其存储在云存储桶中——文件或数据库中的元数据不断变化。然后,他们必须编写定制脚本才能搜索、获取或对信息进行预处理。
完成初始工作后,他们必须引入图数据库以及向量搜索和分类功能,才能提供计划中的生成式AI体验。这使得设置变得复杂,团队不得不处理大量的集成和管理任务,最终导致项目延误数月。
Gupta解释说:“企业希望他们的数据层能够让他们管理不同模态的数据,轻松地为机器学习准备数据,易于数据集管理,管理注释,跟踪模型信息,并让他们使用多模态搜索来搜索和可视化数据。遗憾的是,他们目前的选择是手动集成的解决方案,他们必须将云存储、数据库、各种格式的标签、难以处理的(视觉)处理库和向量数据库整合在一起,才能将多模态数据输入转换为有意义的AI或分析输出。”
受此挑战的启发,Gupta与英特尔实验室的另一位研究科学家Luis Remis合作,创办了ApertureData,旨在构建一个能够在一个地方处理与多模态AI相关的所有数据任务的数据层。
最终的产品ApertureDB,现在允许企业集中所有相关数据集——包括大型图像、视频、文档、嵌入及其关联的元数据——以实现高效的检索和查询处理。它存储数据,为用户提供统一的模式视图,然后提供知识图谱和向量搜索功能,供AI管道下游使用,无论是构建聊天机器人还是搜索系统。
Gupta补充说:“通过数百次对话,我们了解到我们需要一个数据库,它不仅能够理解多模态数据管理的复杂性,而且能够理解AI需求,使AI团队能够轻松地采用和部署到生产环境中。这就是我们使用ApertureDB构建的内容。”
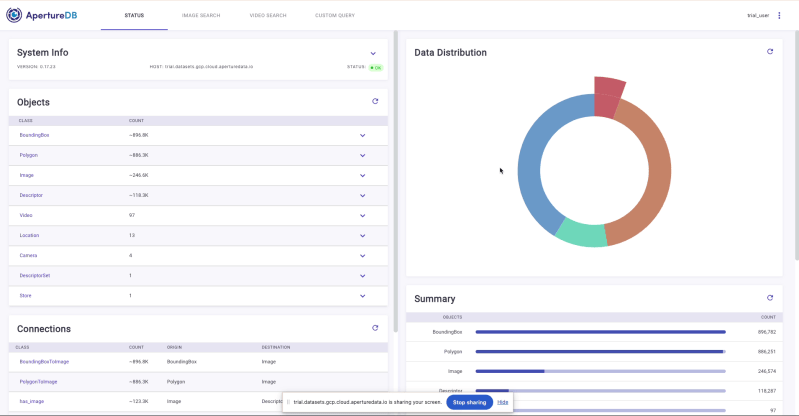
ApertureDB 仪表板
虽然市场上有很多针对AI的数据库,但ApertureData希望通过提供一个统一的产品来为自己创造一个利基市场,该产品可以本地存储和识别多模态数据,并轻松地将知识图谱的强大功能与快速的多模态向量搜索相结合,以满足AI用例的需求。用户可以轻松地存储和深入了解数据集之间的关系,然后使用他们选择的AI框架和工具进行目标应用。
Gupta强调说:“我们真正的竞争对手是内部构建的数据平台,它结合了数据工具,例如关系型/图数据库、云存储、数据处理库、向量数据库以及内部脚本或可视化工具,用于将不同模态的数据转换为有用的见解。我们通常会取代的现有产品是Postgres、Weaviate、Qdrant、Milvus、Pinecone、MongoDB或Neo4j等数据库——但在多模态或生成式AI用例的背景下。”
ApertureData声称,其数据库以其当前形式,可以轻松地将数据科学和AI团队的生产力平均提高10倍。它在调动多模态数据集方面,可以比分散的解决方案快35倍。同时,在向量搜索和分类方面,它比市场上现有的开源向量数据库快2-4倍。
这位首席执行官没有透露客户的具体名称,但指出他们已经从一些财富100强客户那里获得了部署,包括一家大型家居用品零售商、一家大型制造商以及一些生物技术、零售和新兴的生成式AI初创公司。
她说:“在我们的部署中,我们从客户那里听到的共同好处是生产力、可扩展性和性能。”她指出,该公司为其中一位客户节省了200万美元。
作为下一步,它计划通过扩展新的云平台来适应新兴的AI应用类别,专注于生态系统集成以向用户提供无缝体验,并扩展合作伙伴部署。