

订阅我们的每日和每周通讯,获取有关行业领先的 AI 报道的最新更新和独家内容。了解更多
ChatGPT 的出现将大型语言模型 (LLM) 带入了科技和非科技行业的广泛应用。这种流行主要归功于两个因素:
- LLM 作为知识宝库:LLM 在海量互联网数据上进行训练,并定期更新(即 GPT-3、GPT-3.5、GPT-4、GPT-4o 等);
- 涌现能力:随着 LLM 的发展,它们展现出小型模型中没有的能力。
这是否意味着我们已经达到了人类水平的智能,即我们所说的通用人工智能 (AGI)?Gartner 将 AGI 定义为一种能够理解、学习和应用跨越广泛任务和领域的知识的 AI 形式。通往 AGI 的道路漫长,其中一个关键障碍是 LLM 训练的自回归性质,它根据过去的序列预测单词。作为 AI 研究的先驱之一,Yann LeCun 指出,由于其自回归性质,LLM 可能会偏离准确的响应。因此,LLM 存在一些局限性:
- 知识有限:虽然在海量数据上进行训练,但 LLM 缺乏最新的世界知识。
- 推理能力有限:LLM 的推理能力有限。正如 Subbarao Kambhampati 指出,LLM 是优秀的知识检索器,但不是优秀的推理器。
- 缺乏动态性:LLM 是静态的,无法访问实时信息。
为了克服 LLM 的挑战,需要更先进的方法。这就是智能体变得至关重要的原因。
人工智能中智能体的概念已经发展了二十多年,其实现方式随着时间的推移而改变。如今,智能体在 LLM 的背景下被讨论。简单来说,智能体就像 LLM 挑战的瑞士军刀:它可以帮助我们进行推理,提供从互联网获取最新信息的方法(解决 LLM 的动态性问题),并可以自主完成任务。以 LLM 为其支柱,智能体正式包含工具、记忆、推理(或规划)和行动组件。
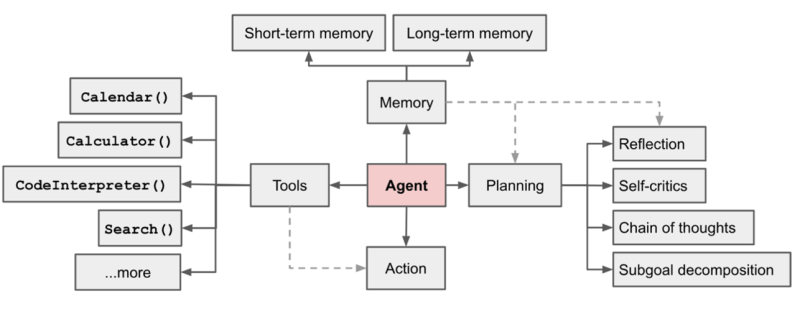 智能体的组件(图片来源:Lilian Weng)
智能体的组件(图片来源:Lilian Weng)
- 工具使智能体能够访问外部信息——无论是来自互联网、数据库还是 API——使它们能够收集必要的数据。
- 记忆可以是短期或长期。智能体使用草稿记忆临时保存来自各种来源的结果,而聊天历史是长期记忆的一个例子。
- 推理器使智能体能够有条理地思考,将复杂的任务分解成可管理的子任务,以便有效地处理。
- 行动:智能体根据其环境和推理执行行动,通过反馈迭代地适应和解决任务。ReAct 是迭代执行推理和行动的常用方法之一。
智能体擅长处理复杂的任务,尤其是在角色扮演模式下,利用 LLM 的增强性能。例如,在撰写博客时,一个智能体可能专注于研究,而另一个智能体则负责写作——每个智能体都处理一个特定的子目标。这种多智能体方法适用于许多现实生活中的问题。
角色扮演帮助智能体专注于特定任务以实现更大的目标,通过明确定义提示的各个部分——例如角色、指令和上下文——来减少幻觉。由于 LLM 的性能取决于结构良好的提示,因此各种框架将此过程形式化。CrewAI 就是这样一个框架,它提供了一种结构化的方法来定义角色扮演,我们将在下面讨论。
以使用单个智能体的检索增强生成 (RAG) 为例。这是一种有效的方法,通过利用来自索引文档的信息,使 LLM 能够处理特定领域的查询。然而,单智能体 RAG 也有其自身的局限性,例如检索性能或文档排名。多智能体 RAG 通过使用专门的智能体来进行文档理解、检索和排名来克服这些局限性。
在多智能体场景中,智能体以不同的方式协作,类似于分布式计算模式:顺序、集中、分散或共享消息池。CrewAI、Autogen 和 langGraph+langChain 等框架使多智能体方法能够解决复杂的问题。在本文中,我使用 CrewAI 作为参考框架来探索自主工作流管理。
大多数工业流程都是关于管理工作流,无论是贷款处理、营销活动管理还是 DevOps。为了实现特定目标,需要执行顺序或循环步骤。在传统方法中,每个步骤(例如,贷款申请验证)都需要人工执行繁琐且单调的任务,即手动处理每个申请并进行验证,然后才能进入下一步。
每个步骤都需要该领域专家的输入。在使用 CrewAI 的多智能体设置中,每个步骤都由一个由多个智能体组成的团队处理。例如,在贷款申请验证中,一个智能体可以通过对驾驶执照等证件进行背景调查来验证用户的身份,而另一个智能体则验证用户的财务信息。
这引发了一个问题:一个团队(包含多个顺序或层次结构的智能体)能否处理所有贷款处理步骤?虽然有可能,但这会使团队变得复杂,需要大量的临时记忆,并增加目标偏离和幻觉的风险。更有效的方法是将每个贷款处理步骤视为一个独立的团队,将整个工作流视为一个团队节点图(使用 langGraph 等工具),这些节点按顺序或循环运行。
由于 LLM 仍处于智能的早期阶段,因此无法完全自主地进行工作流管理。在关键阶段需要人工参与进行最终用户验证。例如,在团队完成贷款申请验证步骤后,需要人工监督来验证结果。随着对 AI 信心的增长,随着时间的推移,某些步骤可能会变得完全自主。目前,基于 AI 的工作流管理在辅助角色中发挥作用,简化繁琐的任务并缩短整体处理时间。
将多智能体解决方案投入生产可能会带来一些挑战。
- 规模:随着智能体数量的增加,协作和管理变得具有挑战性。各种框架提供了可扩展的解决方案——例如,Llamaindex 利用事件驱动的工作流来大规模管理多智能体。
- 延迟:由于任务是迭代执行的,因此智能体性能通常会产生延迟,需要多次调用 LLM。托管的 LLM(如 GPT-4o)由于隐式护栏和网络延迟而速度较慢。自托管的 LLM(具有 GPU 控制)在解决延迟问题方面非常有用。
- 性能和幻觉问题:由于 LLM 的概率性质,智能体性能在每次执行时可能会有所不同。输出模板(例如 JSON 格式)和在提示中提供充足的示例等技术可以帮助减少响应的可变性。通过训练智能体可以进一步减少幻觉问题。
正如 Andrew Ng 指出,智能体是 AI 的未来,并将随着 LLM 的发展而不断发展。多智能体系统将在处理多模态数据(文本、图像、视频、音频)和解决越来越复杂的任务方面取得进展。虽然 AGI 和完全自主的系统仍处于地平线上,但多智能体将弥合 LLM 和 AGI 之间的当前差距。
Abhishek Gupta 是 Talentica Software 的首席数据科学家。
DataDecisionMakers
欢迎来到 VentureBeat 社区!
DataDecisionMakers 是专家(包括从事数据工作的人员)分享数据相关见解和创新的平台。
如果您想了解前沿理念、最新信息、最佳实践以及数据和数据技术的未来,请加入我们 DataDecisionMakers。
您甚至可以考虑 撰写文章 !
阅读 DataDecisionMakers 的更多内容





