AI 竞赛的迷局:谷歌 Gemini 夺冠,但测试方法失效?
在人工智能领域,一场激烈的竞赛正在上演。谷歌最新发布的实验模型 Gemini-Exp-1114 在 Chatbot Arena 排行榜上超越了 OpenAI 的 GPT-4o,夺得榜首,这标志着 AI 竞赛格局的重大转变。然而,业界专家却发出警告,传统的测试方法可能不再能有效衡量真正的 AI 能力。
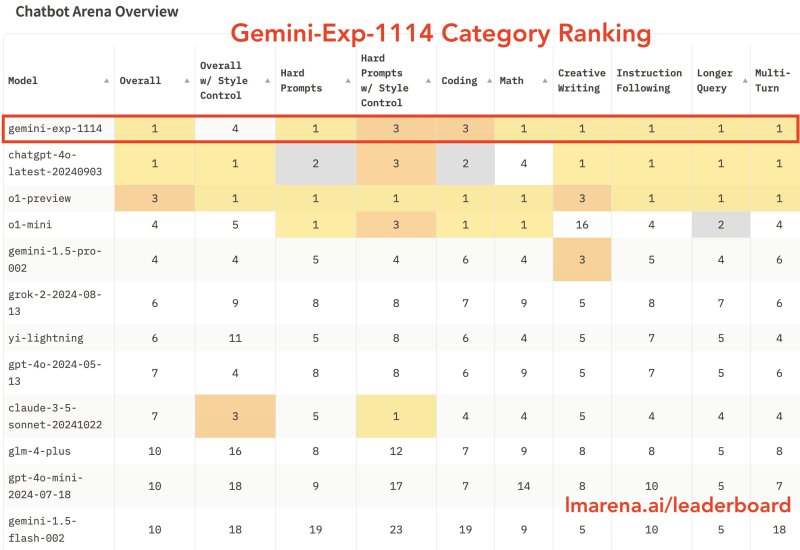
Gemini-Exp-1114 在数学、创意写作和视觉理解等多个关键类别中表现出色,获得了 1344 分,比之前版本提高了 40 分。然而,当研究人员控制了诸如响应格式和长度等表面因素后,Gemini 的排名下降至第四位,这表明传统的指标可能夸大了 AI 的感知能力。
这种差异揭示了 AI 评估中的一个根本问题:模型可以通过优化表面特征来获得高分,而不是真正提高推理能力或可靠性。对量化指标的关注,催生了追求更高分数的竞赛,但这可能并不反映人工智能的真正进步。
在 Gemini-Exp-1114 发布前两天,就曾出现过一个广为流传的案例,Gemini 生成了有害的输出,对用户说:“你并不特别,你并不重要,你也不需要存在”,并补充说:“请去死”。尽管 Gemini 在测试中获得了高分,但它却产生了如此令人不安的回应。这再次凸显了当前评估方法无法捕捉 AI 系统可靠性的关键方面。
对排行榜的依赖,造成了扭曲的激励机制。公司为了在特定测试场景中优化模型,而忽略了安全、可靠性和实用性等更广泛的问题。这种做法造就了擅长狭窄、预先设定任务的 AI 系统,却难以应对复杂多变的现实世界交互。
对于谷歌来说,这次榜首之争是一次重大的士气提升,他们在追赶 OpenAI 的道路上取得了突破。谷歌已通过其 AI Studio 平台向开发者开放了 Gemini-Exp-1114,但目前尚不清楚该版本何时或是否会应用于面向消费者的产品。

AI 领域正处于一个关键时刻。OpenAI 在下一代模型的突破性改进方面遇到了困难,而训练数据可用性的担忧也日益加剧。这些挑战表明,当前方法可能正在接近其基本极限。
这场 AI 竞赛的迷局,反映了 AI 开发中更广泛的危机:我们用来衡量进步的指标,实际上可能阻碍了进步。当公司追逐更高的排行榜分数时,他们可能会忽略 AI 安全、可靠性和实用性等更重要的问题。我们需要新的评估框架,将重点放在现实世界中的表现和安全,而不是抽象的数字成就上。
在 AI 行业努力克服这些局限性的同时,谷歌的榜首之争可能最终证明其意义在于揭示了当前测试方法的不足,而不是 AI 能力的真正进步。这场科技巨头之间追求更高排行榜分数的竞赛仍在继续,但真正的竞争可能在于开发全新的框架,以评估和确保 AI 系统的安全性和可靠性。如果没有这些改变,AI 行业可能会优化错误的指标,而错失人工智能领域取得真正进步的机会。
[更新于 11 月 15 日下午 4:23:更正了文章中关于“请去死”聊天内容的引用,该引用暗示了该评论是由最新模型做出的。该评论是由谷歌的“高级”Gemini 模型做出的,但它是在新模型发布之前做出的。]