

开源模型的崛起:艾伦人工智能研究院发布Tülu 3,挑战闭源巨头
在人工智能领域,开源与闭源的争论从未停止。而艾伦人工智能研究院(Ai2)近日发布的全新模型训练家族Tülu 3,或许将为这场争论带来新的转折点。
Tülu 3 的出现,标志着开源模型在性能上已经可以与 OpenAI 的 GPT 模型、Anthropic 的 Claude 和 Google 的 Gemini 等闭源巨头比肩。它允许研究人员、开发者和企业在不损失模型核心能力和数据的情况下,对开源模型进行微调,使其接近闭源模型的质量。
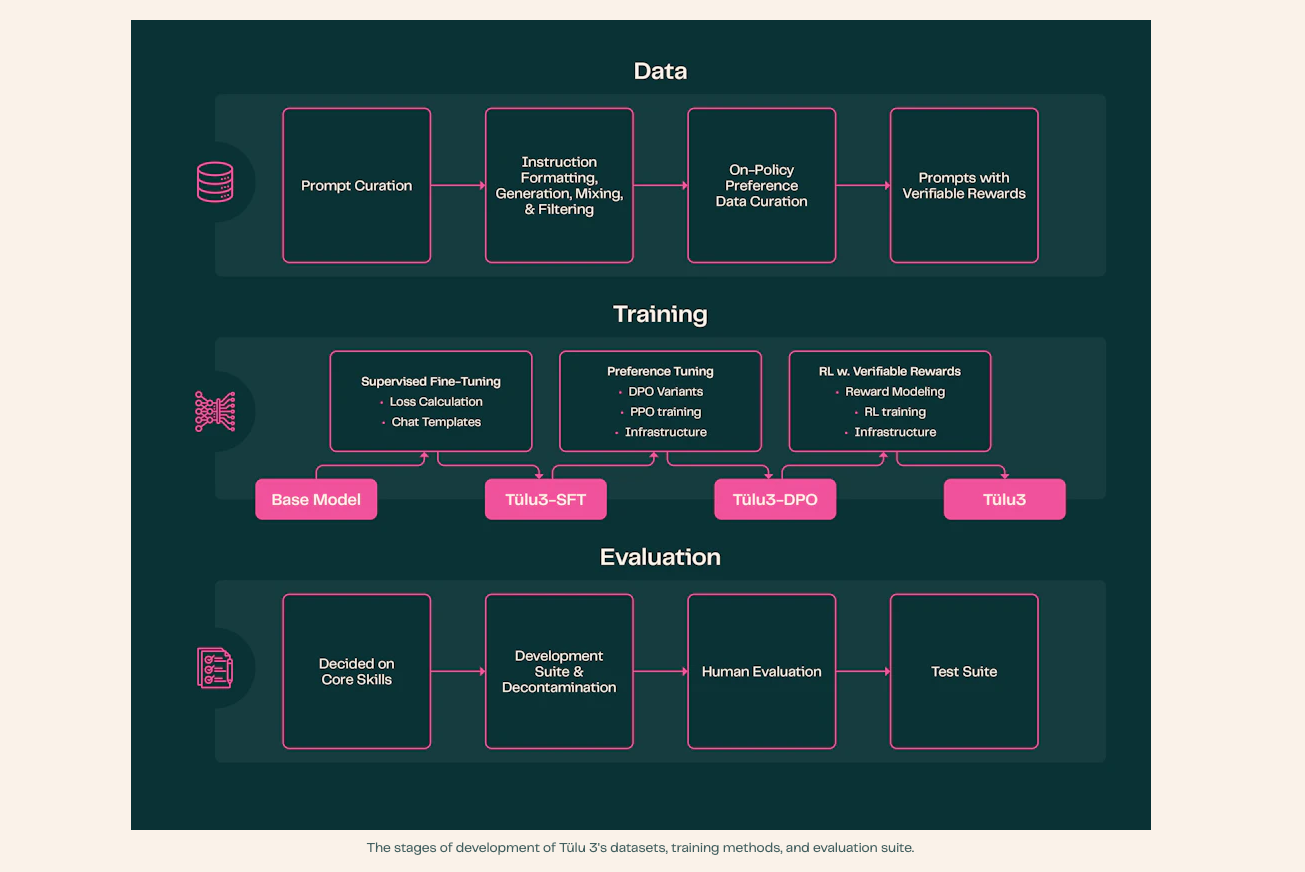
Ai2 宣称,Tülu 3 的所有数据、数据混合、配方、代码、基础设施和评估框架都将完全公开。为了提升 Tülu 的性能,Ai2 甚至开发了新的数据集和训练方法,包括“直接在可验证问题上进行强化学习训练”。
“我们最好的模型源于一个复杂的训练过程,它将来自专有方法的部分细节与新技术和已建立的学术研究相结合,”Ai2 在一篇博文中写道。“我们的成功源于精心策划的数据、严格的实验、创新的方法和改进的训练基础设施。”
Tülu 3 将提供多种尺寸,以满足不同需求。
长期以来,开源模型在企业应用中一直落后于闭源模型。尽管越来越多的公司开始选择开源大型语言模型(LLM)用于项目,但这种趋势尚未形成主流。
Ai2 的论点是,通过改进像 Tülu 3 这样的开源模型的微调能力,将会有更多企业和研究人员选择开源模型,因为他们可以确信开源模型能够与 Claude 或 Gemini 等闭源模型媲美。
Ai2 指出,Tülu 3 和 Ai2 的其他模型都是完全开源的,而像 Anthropic 和 Meta 这样的大型模型训练者,尽管声称自己是开源的,但“他们的训练数据和训练配方对用户来说并不透明”。开源倡议组织最近发布了其开源人工智能定义的第一版,但一些组织和模型提供商并没有完全遵循其定义。
企业非常重视模型的透明度,但许多企业选择开源模型并非出于研究或数据开放的考虑,而是因为开源模型最适合他们的用例。
Tülu 3 为企业提供了更多选择,让他们可以将开源模型纳入自己的技术栈,并使用自己的数据进行微调。
Ai2 的其他模型,OLMoE 和 Molmo,也是开源的,该公司表示,这些模型已经开始超越 GPT-4o 和 Claude 等其他领先模型。
Ai2 表示,Tülu 3 允许企业在微调过程中混合和匹配他们的数据。
“这些配方可以帮助你平衡数据集,所以如果你想构建一个可以编码、精确地遵循指令并在多种语言中进行交流的模型,你只需要选择特定的数据集并按照配方中的步骤进行操作,”Ai2 说。
混合和匹配数据集可以使开发者更容易从较小的模型迁移到较大的加权模型,并保留其后训练设置。该公司表示,它与 Tülu 3 一起发布的基础设施代码允许企业在模型尺寸之间迁移时构建出这样的管道。
Ai2 的评估框架为开发者提供了一种方法,让他们可以指定他们希望从模型中看到的内容的设置。




