

Exa:颠覆搜索引擎的全新尝试
Exa,一家初创公司,正试图以一种全新的方式重塑搜索引擎。他们利用大型语言模型的技术,提供更精准的搜索结果,挑战着包括谷歌和 OpenAI 在内的搜索巨头。Exa 的目标是将互联网混乱的网页海洋,打造成一个井井有条的目录,提供更精确、更具体的搜索结果。
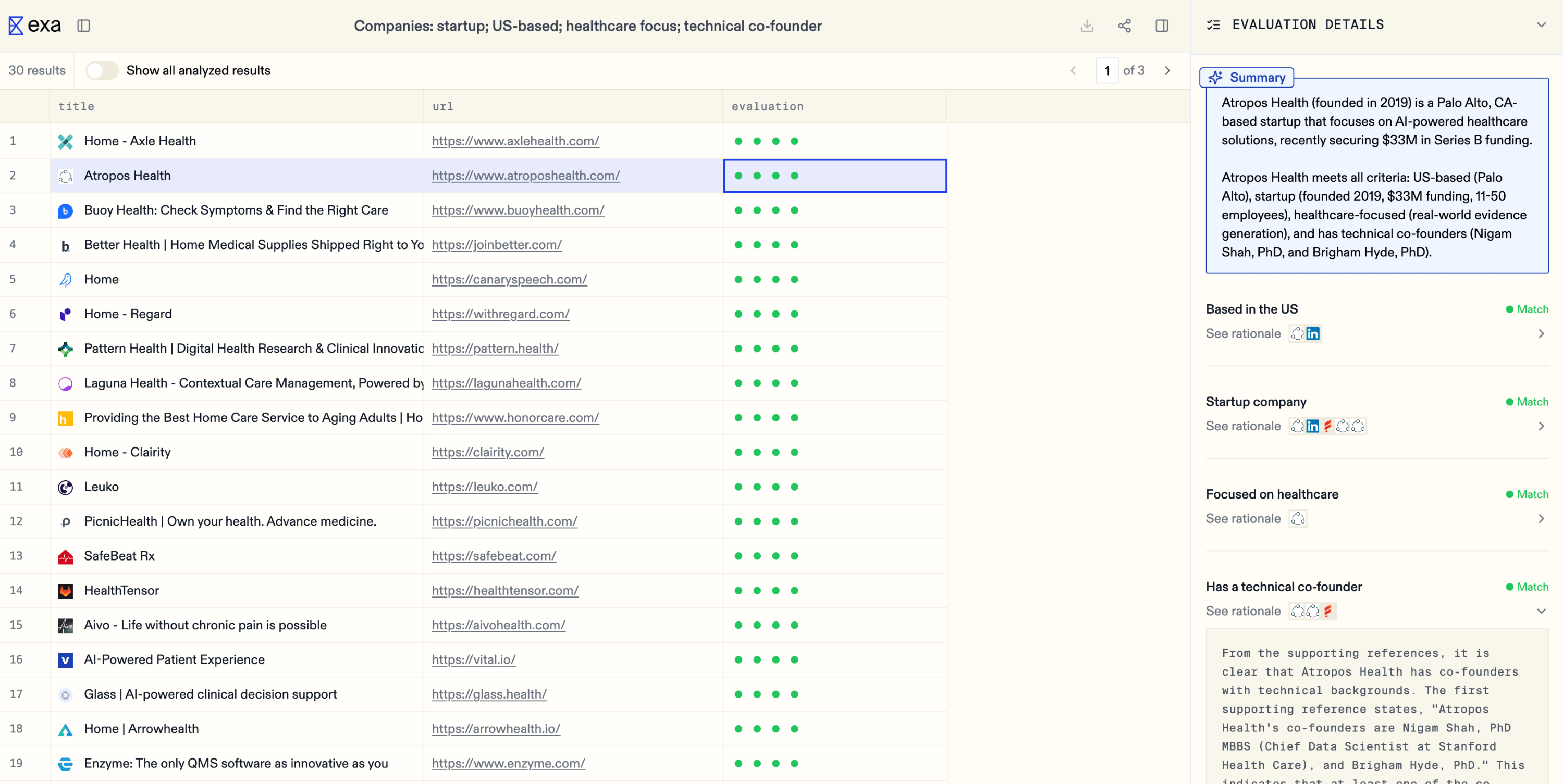
Exa 已经将他们的搜索引擎作为后端服务提供给其他公司,供他们构建自己的应用程序。今天,他们发布了面向消费者的搜索引擎版本,名为 Websets。
“互联网是一座数据宝库,但它也杂乱无章,”Exa 的联合创始人兼 CEO Will Bryk 说,“这里有 Joe Rogan 的视频,那里有《大西洋月刊》的文章,毫无组织。但我们的梦想是让互联网像一个数据库一样。”
Websets 旨在服务于那些需要寻找其他搜索引擎难以找到的信息的用户,例如特定类型的人或公司。例如,搜索“制造未来硬件的初创公司”,你将得到一个包含数百家公司的列表,而不是那些含糊其辞的网页链接。Bryk 认为,谷歌无法做到这一点:“对于投资者、招聘人员,或者任何想要从互联网获取数据集的人来说,这都是一个非常有价值的应用场景。”
自 2021 年《麻省理工科技评论》报道谷歌研究人员正在探索将大型语言模型应用于新型搜索引擎以来,这一领域发展迅速。这一想法很快招致了激烈的批评,但科技公司对此并不理会。三年过去了,谷歌和微软等巨头,以及 Perplexity 和 OpenAI 等新兴公司,都在争夺这一热门趋势的市场份额。OpenAI 在 10 月份推出了 ChatGPT Search。
Exa 目前还没有试图超越这些公司。相反,他们提出了一个全新的方案。大多数其他搜索公司将大型语言模型与现有的搜索引擎结合起来,利用模型分析用户的查询,然后总结结果。但搜索引擎本身并没有发生太大变化。例如,Perplexity 仍然将查询指向 Google Search 或 Bing。可以将今天的 AI 搜索引擎比作一个三明治,新鲜的面包,但馅料却陈旧。
超越关键词
Exa 为用户提供熟悉的链接列表,但利用大型语言模型的技术,重新定义了搜索本身。基本思路是:谷歌通过爬取网页,建立一个庞大的关键词索引,然后将这些关键词与用户的查询进行匹配。Exa 爬取网页,并将网页内容编码成一种称为嵌入的格式,这种格式可以被大型语言模型处理。
嵌入将单词转换成数字,使具有相似含义的单词变成具有相似值的数字。实际上,这使得 Exa 可以捕捉网页文本的含义,而不仅仅是关键词。
大型语言模型使用嵌入来预测句子中的下一个单词。Exa 的搜索引擎预测下一个链接。输入“制造未来硬件的初创公司”,模型将给出可能跟随该短语的(真实的)链接。
然而,Exa 的方法也存在成本问题。对网页进行编码而不是索引关键词,速度慢且成本高。Bryk 表示,Exa 已经编码了数十亿个网页。与谷歌索引的近万亿个网页相比,这只是沧海一粟。但 Bryk 并不认为这是一个问题:“你不需要嵌入整个互联网才能发挥作用。”(有趣的是,“exa”代表 1 后面跟着 18 个 0,“googol”代表 1 后面跟着 100 个 0。)
Websets 返回结果的速度非常慢,有时搜索需要几分钟。但 Bryk 声称这是值得的。“很多客户开始要求成千上万甚至上万个结果,”他说,“他们愿意去喝杯咖啡,回来再看一个庞大的列表。”
“当我不知道自己在寻找什么的时候,我发现 Exa 最有用,”斯坦福大学计算机科学专业的学生 Andrew Gao 说,他使用过 Exa 搜索引擎。“例如,查询‘关于金融领域 LLM 的一篇有趣的博客文章’在 Exa 上比在 Perplexity 上效果更好。”但他补充说,它们擅长不同的领域:“我将它们用于不同的目的。”
“我认为嵌入是表示现实世界中的人、地点和事物等实体的绝佳方式,”Diffbot 的 CEO Mike Tung 说,Diffbot 是一家使用知识图谱构建另一种搜索引擎的公司。但他指出,如果你试图嵌入整个句子或网页文本,你会丢失很多信息:“将《战争与和平》表示为一个单一的嵌入,将丢失故事中发生的几乎所有具体事件,只留下其类型和时代的概括性感觉。”
Bryk 承认 Exa 仍在发展中。他也指出了其他局限性。如果你只是想查找单个信息,例如泰勒·斯威夫特的男朋友的名字或 Will Bryk 是谁,Exa 就不如竞争对手的搜索引擎:“它会给出很多波兰语姓氏的人,因为我的姓氏是波兰语,而嵌入在匹配精确关键词方面很糟糕,”他说。
目前,Exa 通过在需要时将关键词重新加入到混合中来解决这个问题。但 Bryk 对此持乐观态度:“我们正在弥补嵌入方法的不足,直到嵌入方法变得如此好,以至于我们不再需要弥补这些不足。”





