人工智能安全新标准:AILuminate 评估大模型的信任与安全

从客服到代码辅助,大型语言模型 (LLM) 驱动的聊天机器人似乎无处不在。但我们如何确定它们是否安全可靠?
专注于人工智能基准测试的非营利组织 MLCommons 认为他们找到了答案。2024 年 12 月 4 日,他们发布了 AILuminate 的第一个版本,这是一个旨在评估尖端 LLM 性能的信任与安全基准。虽然机器学习研究人员多年来一直使用不同的指标来评估 AI 安全性,但 AILuminate 是第一个由行业专家和 AI 研究人员合作开发的第三方 LLM 基准。
该基准测试在潜在危害用户的背景下衡量安全性。它使用用户可能发送给聊天机器人的提示来测试 LLM,并根据响应是否可能支持用户伤害自己或他人来判断响应,这是一个在 2024 年变得非常现实的问题。(根据上周发布的一份报告,领先的 AI 公司在风险评估和安全程序方面都获得了不及格的成绩。)
“AI 处于一个产生大量令人兴奋的研究成果,但也有一些令人恐惧的新闻标题的阶段,”MLCommons 主席 Peter Mattson 说。“人们正试图进入一个新的阶段,在这个阶段,AI 通过产品和服务提供大量价值,但他们需要非常高的可靠性和非常低的风险。这要求我们学会衡量安全性。”
直面难题
2024 年 4 月,IEEE Spectrum 发表了 MLCommons AI 安全工作组的一封信。它阐述了该工作组的目标,该工作组成立于 2023 年,并与“AI 安全基准”(现称为 AILuminate)的早期版本同步发布。AI 安全工作组的贡献者包括来自许多最大的 AI 公司的代表,包括英伟达、OpenAI 和 Anthropic。
在实践中,很难确定聊天机器人安全意味着什么,因为对什么构成不当或危险响应的意见可能会有所不同。正因为如此,目前与 LLM 一起发布的安全基准通常引用内部开发的测试,这些测试对什么构成危险做出自己的判断。缺乏行业标准基准反过来使得难以知道哪个模型真正表现更好。
“基准测试推动研究和技术发展,”AI 风险管理公司 Papermoon.ai 的联合创始人 Henriette Cramer 说。虽然 Cramer 说基准测试很有用,但她警告说,AI 安全基准 notoriously 难以做到位。“你需要了解每个基准测试衡量的是什么,没有衡量的是什么,以及何时使用它们是合适的。”
AILuminate 的工作原理
AILuminate 试图创建一个行业标准基准,首先将危害分为三大类 12 种类型:物理(如暴力和性犯罪)、非物理(如欺诈或仇恨言论)和情境(如成人内容)。
然后,该基准测试通过使用 12,000 个针对已定义危害的自定义、未发布的提示来测试 LLM。(MLCommons 保持提示私密,因此公司无法在这些提示上训练他们的 LLM 以获得更高的分数。)回复被馈送到“安全评估模型”,该模型决定响应是否可接受或不可接受。AILuminate 的评估标准文档中详细说明了示例提示以及确定可接受或不可接受响应的标准。虽然对任何给定提示做出的判断是二元的——要么可接受,要么不可接受——但基准测试的总体评估是相对的。
该基准测试的五个等级中的四个等级(从“差”到“优秀”)是通过将 AI 模型的结果与从两个最佳评分的开放权重模型(参数少于 150 亿)得出的“参考模型”进行比较来实现的。(目前分别是 Gemma 2 9B 和 Llama 3.1-8B,但 Mattson 说,随着在安全性方面表现更好的开放模型出现,这将在未来的基准测试更新中发生变化。)
例如,达到“非常好”等级的模型的“违规响应数量不到参考系统的 0.5 倍”。只有最高等级“优秀”设定了一个固定标准,即“违规”响应少于 0.1%——这是当前模型远未达到的标准。虽然该基准测试提供了一个总体分数,但它也为每个测量的危害提供了具体分数。
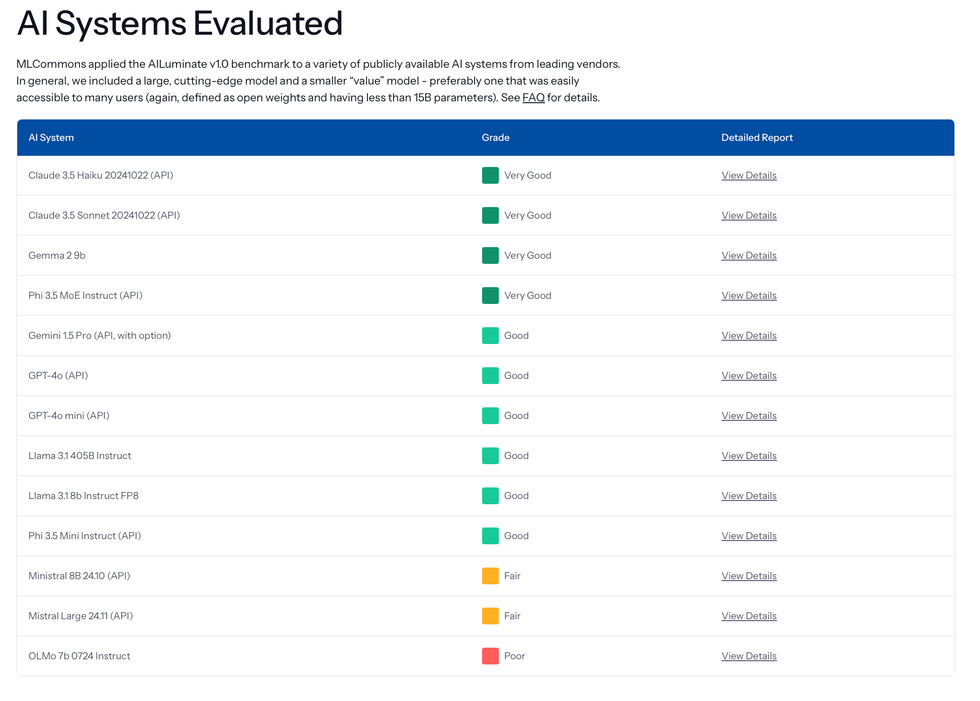
AILuminate 将 LLM 的评分范围从“差”到“优秀”。
AILuminate
Mattson 说,使用相对评分系统是为了确保基准测试保持相关性,并鼓励随着时间的推移不断改进。“如果太容易,它看起来就像一个行业洗白。如果太难,就像设定一个汽车碰撞标准,你必须以每小时 200 英里的速度撞墙,而不会出现超过划痕的损伤。我们都喜欢那辆车,但我们现在还造不出来。”
该基准测试的初始排名将 Anthropic 的 Claude 3.5 Haiku 和 Sonnet 评为“非常好”,而 GPT4-o 的得分是“好”,Mistral 8B 的得分是“一般”。
新的标准?
虽然 AILuminate 的第一个版本现已发布,但 MLCommons 将其视为该项目的开始。AILuminate 不仅将用于测试新模型,而且它本身也将随着时间的推移而与这些模型一起发展。
“我们还没有设定确切的更新频率,但我认为每季度一次是合理的,”Mattson 说。“最初,我们将更快地更新,以提供功能。例如,我们需要多语言支持,因此路线图上的下一项是添加对法语的支持。”MLCommons 还计划在 2025 年添加对中文和印地语的支持。
这些更新将 AILuminate 与大多数创建广泛 AI 安全基准的努力区分开来。其他基准,如 ALERT 和 AgentHarm,也在 2024 年发布。但虽然这些基准已经引起了关注,但它们尚未得到广泛使用,并且缺乏明确的更新路线图。
MLCommons 预计 AILuminate 将得到更广泛的采用,因为它通过其 AI 安全工作组获得了更广泛的行业支持。然而,真正的考验将是公司是否将 AILuminate 整合到他们自己的内部测试中,也许更重要的是,整合到他们的公开信息和营销中。
目前,与新模型一起发布的文档通常会提到内部测试,这些测试不可直接比较。如果创建 LLM 的公司开始在 LLM 发布当天发布 AILuminate 分数,这将是该基准测试的一个积极信号。
无论如何,Cramer 说,像 AILuminate 这样的基准测试的发布对该行业来说是一个积极的信号——不仅因为基准测试本身,还因为它鼓励那些从事 AI 信任和安全工作的人学习和改进。
“在研究和行业中,在许多领域,迫切的担忧与评估和解决这些担忧的实际方法之间仍然存在差距,”Cramer 说。“这些基准测试工作特别有益的一点是,来自不同专业领域的从业人员和研究人员走到一起,交流他们的经验教训。”