

突破字节级限制:Meta 和华盛顿大学联手打造新型语言模型
在人工智能领域,大型语言模型 (LLM) 的发展日新月异。近期,Meta 和华盛顿大学的科学家们携手推出了一个名为“字节潜伏式转换器 (BLT)”的新型架构,有望成为 LLM 发展史上的里程碑。
BLT 的出现,为解决 LLM 在字节级处理数据时面临的长期难题提供了新的思路。它有望构建出能够处理稀有数据、对变化更具鲁棒性且不依赖固定词汇表的全新模型。
传统的 LLM 通常基于预定义的字节序列组成的静态词元集进行训练。在推理过程中,词元化器会将输入序列分解成词元,然后传递给 LLM。这种方法虽然提高了计算效率,但也带来了偏差,导致模型在遇到词汇表中未包含的词元时性能下降。
例如,许多领先的语言模型在处理网络上表示较少的语言时,速度会变慢,成本也会更高,因为这些语言的词语没有包含在模型的词元词汇表中。拼写错误的词语也会导致模型对输入进行错误的词元化。此外,词元化模型在字符级任务(例如操作序列)方面也存在困难。
更重要的是,修改词汇表需要重新训练模型。扩展词元词汇表可能需要对模型架构进行调整,以适应增加的复杂性。
另一种方法是直接在单个字节上训练 LLM,这可以解决上述许多问题。然而,字节级 LLM 的大规模训练成本过高,而且无法处理非常长的序列,因此词元化仍然是当前 LLM 的重要组成部分。
BLT 是一种无词元化架构,它直接从原始字节中学习,并与基于词元化的模型性能相当。为了解决其他字节级 LLM 的低效问题,BLT 使用了一种动态方法,根据字节包含的信息量对字节进行分组。
研究人员表示:“我们架构的核心思想是,模型应该根据需要动态分配计算资源。”
与词元化模型不同,BLT 没有固定的词汇表。相反,它使用熵度量将任意字节组映射到“补丁”中。BLT 通过一个包含三个转换器块的新型架构实现这种动态补丁操作:两个小型字节级编码器/解码器模型和一个大型“潜伏式全局转换器”。
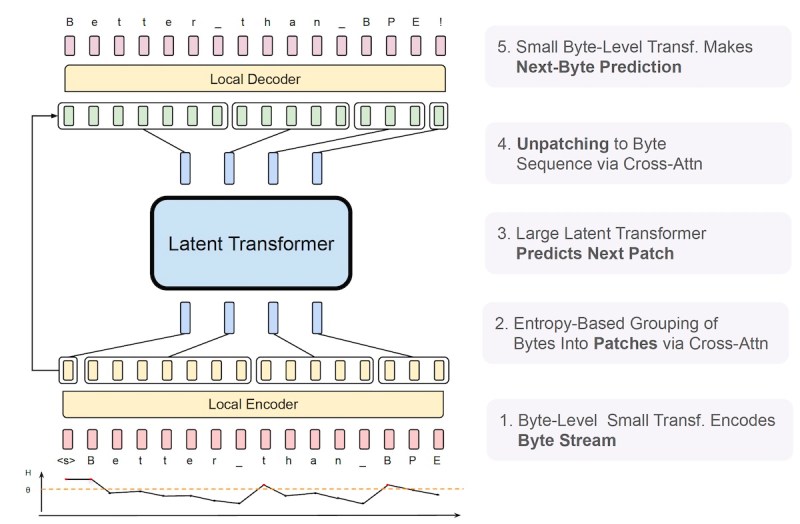 BLT 架构(来源:arXiv)
BLT 架构(来源:arXiv)
编码器和解码器是轻量级模型。编码器接收原始输入字节,并创建传递给全局转换器的补丁表示。在另一端,局部解码器接收全局转换器处理的批次表示,并将它们解码成原始字节。
潜伏式全局转换器是模型的主要工作负载。它接收编码器生成的补丁表示,并预测序列中的下一个补丁。当由解码器处理时,该补丁将被解包成一个或多个字节。
全局转换器在训练和推理过程中占用了大部分计算资源。因此,补丁机制决定了全局转换器的使用方式,并有助于控制用于输入和输出不同部分的计算量。
BLT 重新定义了词汇表大小和计算需求之间的权衡。在标准 LLM 中,增加词汇表大小意味着平均而言更大的词元,这可以减少处理序列所需的步骤。然而,这也将需要在转换器内部的投影层中使用更大的维度,而这本身会消耗更多资源。
相比之下,BLT 可以根据数据的复杂性而不是词汇表大小来平衡计算资源。例如,大多数词语的结尾很容易预测,需要更少的资源。另一方面,预测新词语的第一个字节或句子的第一个词语需要更多的计算周期。
研究人员写道:“BLT 为扩展开辟了新的维度,允许在固定的推理预算内同时增加模型和补丁大小。这种新范式对于实际环境中常见的计算机制而言具有优势。”
研究人员对 BLT 和经典转换器进行了实验,模型规模从 4 亿个参数到 80 亿个参数不等。
作者表示,这是“第一个对字节级模型进行浮点运算控制的扩展研究,模型参数规模高达 80 亿个,训练字节数高达 4T,表明我们可以在没有固定词汇表词元化的前提下,从字节端到端地进行大规模模型训练。”
他们的研究结果表明,在控制分配给训练的计算资源的情况下,BLT 的性能与 Llama 3 相当,而在推理过程中使用的浮点运算次数最多减少了 50%。这种效率来自于模型的动态补丁机制,该机制导致更长的字节组,节省了可以重新分配用于增加潜伏式全局转换器大小的计算资源。
研究人员写道:“据我们所知,BLT 是第一个字节级转换器架构,在计算最优机制下实现了与基于 BPE 的模型相同的扩展趋势。”
除了效率之外,BLT 模型还被证明比基于词元化的模型更能抵抗噪声输入。它们具有增强的字符级理解能力,并且在字符操作和低资源机器翻译等任务中也表现出更好的性能。根据研究人员的说法,BLT 直接处理原始字节而不是词元的能力“在对数据长尾建模方面提供了显著的改进”,这意味着这些模型在处理训练语料库中不常出现的模式方面更出色。
这仅仅是构建语言模型的新标准的开始。研究人员指出,现有的转换器库和代码库被设计为对基于词元化的转换器架构具有很高的效率。这意味着 BLT 仍然有空间从软件和硬件优化中获益。





