

小模型也能胜过大模型?Hugging Face 揭示推理能力新突破
在人工智能领域,模型规模一直被视为性能的关键指标。然而,Hugging Face 的最新研究表明,通过巧妙的配置,小模型也能在复杂任务中超越大型模型。
研究人员发现,一个仅拥有 30 亿参数的 Llama 3 模型,在解决复杂的数学问题时,竟然能够胜过拥有 700 亿参数的同类模型。这一发现颠覆了人们对模型规模的传统认知,也为企业构建定制化推理模型提供了新的思路。

这项研究的灵感源自 OpenAI 的 o1 模型,该模型通过额外的“思考”步骤来解决复杂的数学、编码和推理问题。o1 模型的核心思想是扩展“推理时间计算”,即在推理过程中使用更多计算周期来测试和验证不同的响应和推理路径,最终得出最优答案。
由于 o1 模型是私有的,OpenAI 对其内部机制讳莫如深,研究人员只能通过逆向工程来探索其工作原理。目前,已经出现了一些开源的 o1 模型替代方案。
Hugging Face 的研究基于 DeepMind 今年 8 月发布的一项研究,该研究探讨了推理时间计算和预训练计算之间的权衡关系。研究结果为如何在固定预算下平衡训练和推理计算以获得最佳结果提供了全面的指导。
除了使用额外的推理时间计算之外,这项技术的成功还依赖于两个关键要素:一个用于评估小模型答案的奖励模型,以及一个用于优化模型推理路径的搜索算法。

最简单的推理时间扩展方法是“多数投票”,即向模型多次发送相同的提示,并选择投票最多的答案。在简单的任务中,多数投票可能有效,但在复杂的推理问题或存在一致性错误的任务中,其效果会迅速下降。
更高级的推理方法是“最佳 N 中选一”。在这种方法中,小模型会生成多个答案,但不会进行多数投票,而是使用奖励模型来评估答案并选择最佳答案。“加权最佳 N 中选一”是该方法的更细致版本,它会考虑答案的一致性,选择既自信又出现频率更高的答案。
研究人员使用了一个“过程奖励模型”(PRM),该模型不仅根据最终答案,还根据小模型在得出答案过程中经历的多个阶段来评分。实验结果表明,加权最佳 N 中选一和 PRM 使 Llama-3.2 1B 在困难的 MATH-500 基准测试中接近了 Llama-3.2 8B 的水平。
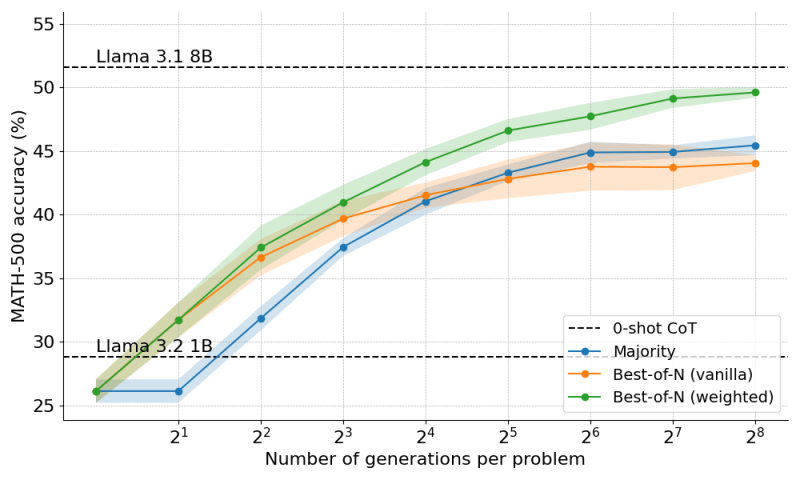
为了进一步提高模型的性能,研究人员在模型的推理过程中添加了搜索算法。他们没有让模型一次性生成答案,而是使用了“束搜索”算法,该算法会逐步引导模型的答案生成过程。
在每一步中,小模型都会生成多个部分答案。搜索算法会使用奖励模型来评估答案,并选择值得进一步探索的子集。该过程会重复进行,直到模型耗尽推理预算或找到正确答案。这样,推理预算就可以集中在最有希望的答案上。
研究人员发现,虽然束搜索可以提高模型在复杂问题上的性能,但在简单问题上往往不如其他技术。为了解决这一挑战,他们在推理策略中添加了两个要素。
第一个是“多样化验证树搜索”(DVTS),它是束搜索的一种变体,可以确保小模型不会陷入错误的推理路径,并使响应分支多样化。第二个是根据 DeepMind 论文提出的“计算最优扩展策略”,该策略会根据输入问题的难度动态选择最佳的推理时间扩展策略。
这些技术的结合使 Llama-3.2 1B 超越了自身的局限,在性能上显著超过了 8B 模型。他们还发现,该策略具有可扩展性,当应用于 Llama-3.2 3B 时,他们能够超越更大的 70B 模型。
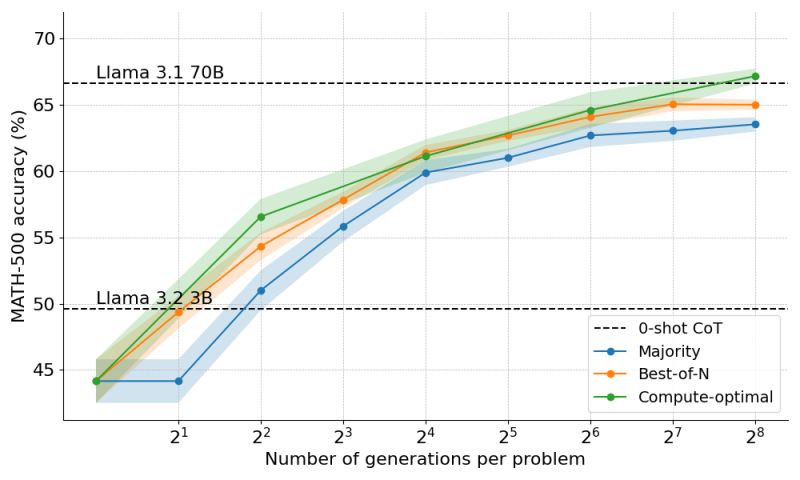
推理时间计算的扩展改变了模型成本的动态。企业现在可以选择将计算资源分配到哪里。例如,如果您内存不足或可以容忍较慢的响应时间,您可以使用小型模型,并花费更多推理时间周期来生成更准确的答案。
然而,推理时间扩展也存在局限性。例如,在 Hugging Face 进行的实验中,研究人员使用了一个经过专门训练的 Llama-3.1-8B 模型作为 PRM,这需要并行运行两个模型(即使它比 70B 模型更节省资源)。研究人员承认,推理时间扩展的最终目标是实现“自我验证”,即原始模型验证自己的答案,而不是依赖外部验证器。这是一个开放的研究领域。
本研究中提出的推理时间扩展技术也仅限于答案可以明确评估的问题,例如编码和数学。对于主观任务,例如创意写作和产品设计,需要进一步研究才能创建奖励模型和验证器。
但可以肯定的是,推理时间扩展已经引起了广泛的关注和研究活动,我们预计未来几个月将出现更多工具和技术。企业应该密切关注这一领域的发展趋势。




