

OpenAI 的 o3 模型在 ARC-AGI 基准测试中取得突破性进展
OpenAI 最新发布的 o3 模型在人工智能研究界引起了轰动,它在超难的 ARC-AGI 基准测试中取得了前所未有的成绩。在标准计算条件下,o3 的得分高达 75.7%,而高计算版本更是达到了 87.5%。
虽然 o3 在 ARC-AGI 中取得的成就令人印象深刻,但它并不意味着人工智能通用智能(AGI)的代码已被破解。
ARC-AGI 基准测试基于抽象推理语料库(ARC),该语料库测试人工智能系统适应新任务和展现灵活智能的能力。ARC 由一组视觉谜题组成,需要理解物体、边界和空间关系等基本概念。虽然人类只需很少的演示就能轻松解决 ARC 谜题,但目前的人工智能系统却难以应对。ARC 长期以来被认为是人工智能最具挑战性的衡量标准之一。
 ARC 谜题示例(来源:arcprize.org)
ARC 谜题示例(来源:arcprize.org)
ARC 的设计巧妙,无法通过在数百万个示例上训练模型来覆盖所有可能的谜题组合,从而作弊。
该基准测试包含一个公开的训练集,其中包含 400 个简单的示例。训练集辅以一个公开的评估集,其中包含 400 个更具挑战性的谜题,用于评估人工智能系统的泛化能力。ARC-AGI 挑战赛包含 100 个谜题的私有和半私有测试集,这些测试集不公开。它们用于评估候选人工智能系统,而不会冒将数据泄露给公众并用先验知识污染未来系统的风险。此外,比赛还限制了参与者可以使用的计算量,以确保谜题不会通过蛮力方法解决。
o1-preview 和 o1 在 ARC-AGI 上的最高得分仅为 32%。研究人员 Jeremy Berman 开发的另一种方法采用混合方法,将 Claude 3.5 Sonnet 与遗传算法和代码解释器相结合,取得了 53% 的成绩,这是 o3 出现之前最高的得分。
ARC 的创建者 François Chollet 在一篇博文中将 o3 的表现描述为“人工智能能力的惊人且重要的阶跃式提升,展示了 GPT 家族模型前所未有的新任务适应能力。”
值得注意的是,在之前的模型上使用更多计算无法达到这些结果。作为参考,模型从 2020 年 GPT-3 的 0% 进步到 2024 年初 GPT-4o 的 5% 花了 4 年时间。虽然我们对 o3 的架构知之甚少,但可以肯定的是,它的大小不会比其前代大几个数量级。
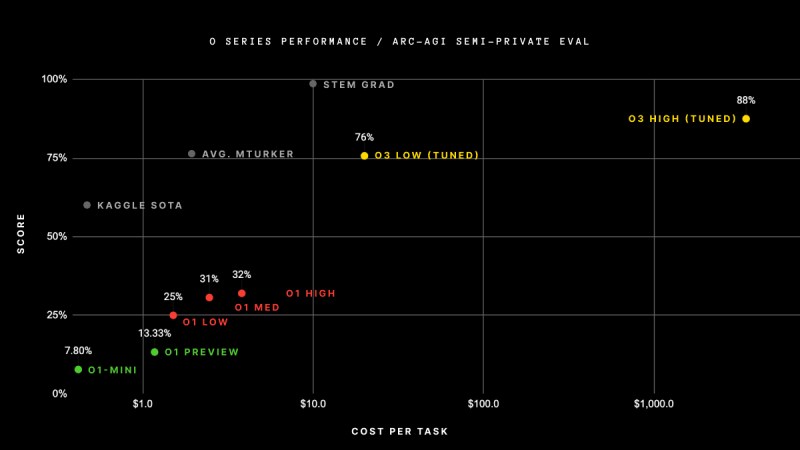 不同模型在 ARC-AGI 上的表现(来源:arcprize.org)
不同模型在 ARC-AGI 上的表现(来源:arcprize.org)
“这不仅仅是渐进式的改进,而是一次真正的突破,标志着人工智能能力与之前大型语言模型(LLM)的局限性相比发生了质的转变,”Chollet 写道。“o3 是一个能够适应以前从未遇到过的任务的系统,可以说在 ARC-AGI 领域接近人类水平的表现。”
值得注意的是,o3 在 ARC-AGI 上的表现代价高昂。在低计算配置下,模型需要花费 17 到 20 美元和 3300 万个 token 来解决每个谜题,而在高计算预算下,模型使用的计算量大约是前者的 172 倍,每个问题需要数十亿个 token。然而,随着推理成本的不断下降,我们可以预期这些数字会变得更加合理。
解决新问题的关键是 Chollet 和其他科学家所说的“程序合成”。一个思考系统应该能够开发出解决特定问题的微型程序,然后将这些程序组合起来解决更复杂的问题。经典的语言模型已经吸收了大量的知识,并包含了一套丰富的内部程序。但它们缺乏组合性,这使得它们无法解决超出其训练分布的谜题。
不幸的是,关于 o3 的内部工作原理的信息很少,科学家们的观点也存在分歧。Chollet 推测,o3 使用一种程序合成方法,该方法使用思维链(CoT)推理和搜索机制,并结合一个奖励模型,在模型生成 token 时评估和改进解决方案。这与开源推理模型在过去几个月里一直在探索的方法类似。
其他科学家,例如艾伦人工智能研究所的 Nathan Lambert 认为,“o1 和 o3 实际上可能只是来自一个语言模型的前向传递。” 在 o3 发布当天,OpenAI 的研究员 Nat McAleese 在 X 上发帖称,o1“只是一个用强化学习训练的 LLM。o3 是通过在 o1 基础上进一步扩展强化学习来实现的。”
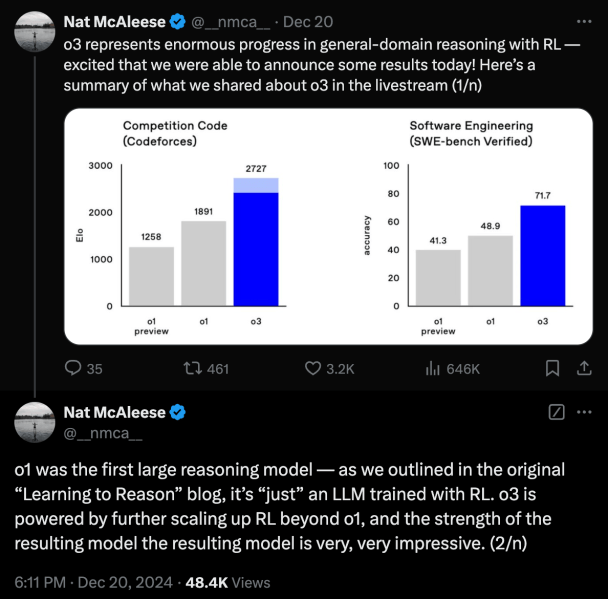
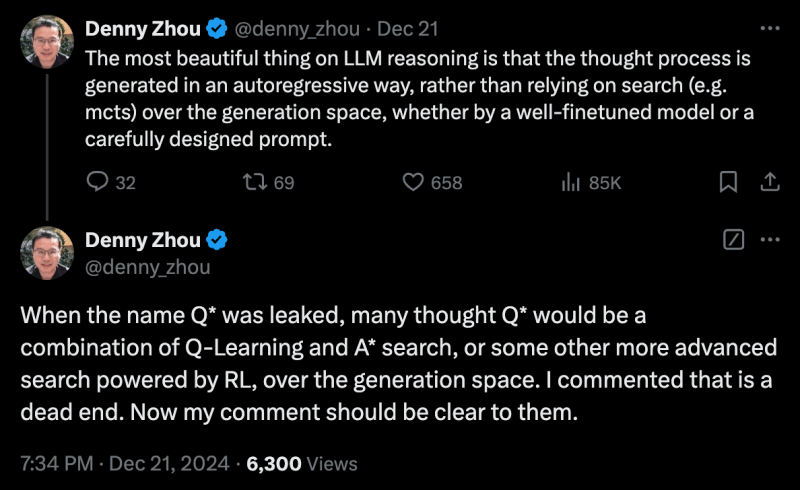
同一天,谷歌 DeepMind 推理团队的 Denny Zhou 将搜索和当前强化学习方法的结合称为“死胡同”。
“LLM 推理中最美妙的事情是,思维过程是通过自回归的方式生成的,而不是依赖于生成空间的搜索(例如蒙特卡洛树搜索),无论是通过精心微调的模型还是精心设计的提示,”他在 X 上发帖说。
虽然 o3 推理的细节与 ARC-AGI 的突破相比似乎微不足道,但它很可能定义了训练 LLM 的下一个范式转变。目前,关于通过训练数据和计算来扩展 LLM 的规律是否已经触及瓶颈存在争议。测试时扩展是依赖于更好的训练数据还是不同的推理架构,这将决定未来的发展方向。
ARC-AGI 这个名字具有误导性,有些人将其等同于解决 AGI。然而,Chollet 强调,“ARC-AGI 并不是 AGI 的试金石。”
“通过 ARC-AGI 并不等于实现 AGI,事实上,我认为 o3 还没有达到 AGI,”他写道。“o3 在一些非常简单的任务上仍然会失败,这表明它与人类智能存在根本差异。”
此外,他指出,o3 无法自主学习这些技能,它依赖于推理过程中的外部验证器和训练过程中的人工标记推理链。
其他科学家也指出了 OpenAI 报告结果的缺陷。例如,该模型在 ARC 训练集上进行了微调,以取得最先进的结果。“求解器不应该需要太多特定的‘训练’,无论是针对领域本身还是针对每个特定任务,”科学家 Melanie Mitchell 写道。
为了验证这些模型是否拥有 ARC 基准测试旨在衡量的抽象和推理能力,Mitchell 建议“看看这些系统是否能够适应特定任务的变体,或者使用相同的概念,但在 ARC 以外的其他领域进行推理任务。”
Chollet 和他的团队目前正在开发一个对 o3 具有挑战性的新基准测试,即使在高计算预算下,也可能将其得分降低到 30% 以下。与此同时,人类无需任何训练就能解决 95% 的谜题。
“当创造对普通人来说很容易但对人工智能来说很难的任务变得不可能时,你就知道 AGI 已经出现了,”Chollet 写道。




