

谷歌 Gemini-Exp-1206:数据分析与可视化的新纪元
在数据分析领域,将数据与可视化完美融合,并以此构建引人入胜的故事,一直是分析师们梦寐以求的目标。然而,繁琐的流程和耗时的操作往往令他们疲惫不堪,甚至需要熬夜加班才能完成任务。
谷歌最新推出的实验模型 Gemini-Exp-1206 或许能改变这一切。它有望彻底改变数据分析师的工作方式,帮助他们轻松地将数据分析与可视化结合,并以更直观的方式呈现分析结果。
投资分析师、初级银行家和咨询团队成员,他们都深知,加班加点、周末工作甚至通宵达旦,是获得晋升的必要条件。然而,他们花费大量时间进行数据分析,同时还要创建与分析结果相呼应的可视化图表,这无疑是一项艰巨的任务。
更具挑战性的是,每家银行、金融科技公司和咨询公司,例如摩根大通、麦肯锡和普华永道,都有自己独特的格式和规范来进行数据分析和可视化。
VentureBeat 采访了聘请这些公司并将其分配到项目的内部项目团队成员。在咨询团队工作的员工表示,将大量数据压缩和整合为可视化图表是一个持续的挑战。一位员工表示,咨询团队经常通宵工作,并对演示文稿的可视化进行至少三到四轮迭代,才能最终确定一个版本,并将其准备好在董事会层面上进行更新。
分析师们依赖的创建演示文稿的过程,需要进行大量的步骤和重复操作,才能将故事与可靠的可视化和图形结合起来。这使得它成为测试谷歌最新模型的一个引人注目的用例。
谷歌的 Patrick Kane 在 12 月初发布该模型时写道:“无论你是要解决复杂的编码挑战,为学校或个人项目解决数学问题,还是提供详细的多步骤说明来制定定制的商业计划,Gemini-Exp-1206 都能帮助你更轻松地完成复杂的任务。” 谷歌指出,该模型在更复杂的任务中表现出色,包括数学推理、编码和遵循一系列指令。
VentureBeat 本周对谷歌的 Exp-1206 模型进行了全面测试。我们创建并测试了 50 多个 Python 脚本,试图自动化和整合分析以及直观易懂的可视化,从而简化复杂数据的分析。鉴于超大规模企业在当今新闻周期中占据主导地位,我们的具体目标是创建对特定技术市场的分析,同时创建支持表格和高级图形。
通过 50 多个经过验证的 Python 脚本的迭代,我们的发现包括:
- Python 代码请求越复杂,模型“思考”的时间越长,并试图预测所需的结果。Exp-1206 试图预测从给定的复杂提示中需要什么,并且会根据提示中即使是最细微的差异改变其输出。我们看到,在模型创建的超大规模企业市场分析蜘蛛图上方,模型会在表格类型格式之间交替变化。
- 强制模型尝试复杂的数据分析和可视化,并生成一个 Excel 文件,会得到一个多标签电子表格。Exp-1206 从未被要求生成一个包含多个标签的 Excel 电子表格,但它却创建了一个。请求的主要表格分析在一个标签上,可视化在另一个标签上,辅助表格在第三个标签上。
- 告诉模型对数据进行迭代,并推荐它认为最适合数据的 10 种可视化,会带来有益的、有见地的结果。为了减少在董事会审查之前必须创建三到四轮幻灯片才能节省时间,我们强制模型生成多个图像概念迭代。这些图像可以轻松地清理并整合到演示文稿中,从而节省了大量手动创建幻灯片图表的时间。
VentureBeat 的目标是了解该模型在复杂性和分层任务方面能够被推到什么程度。它在创建、运行、编辑和微调 50 个不同的 Python 脚本方面的表现表明,该模型能够快速地识别代码中的细微差别,并立即做出反应。该模型根据提示历史进行灵活调整和适应。
在 Google Colab 中运行使用 Exp-1206 创建的 Python 代码的结果表明,细微的粒度扩展到一个八点蜘蛛图的图层阴影和半透明度,该蜘蛛图旨在显示六个超大规模企业竞争对手之间的比较。我们要求 Exp-1206 识别所有超大规模企业中的八个属性,并将其作为蜘蛛图的锚点,这些属性保持一致,而图形表示则有所不同。
我们在测试中选择了以下超大规模企业进行比较:阿里云、亚马逊网络服务 (AWS)、Digital Realty、Equinix、谷歌云平台 (GCP)、华为、IBM 云、Meta Platforms (Facebook)、微软 Azure、NTT 全球数据中心、Oracle 云和腾讯云。
接下来,我们编写了一个包含 11 个步骤、超过 450 个字的提示。目标是了解 Exp-1206 在处理顺序逻辑方面表现如何,以及它在复杂的多步骤过程中是否会迷失方向。(你可以在本文末尾的附录中阅读提示。)
接下来,我们在 Google AI Studio 中提交提示,选择 Gemini Experimental 1206 模型,如下图所示。
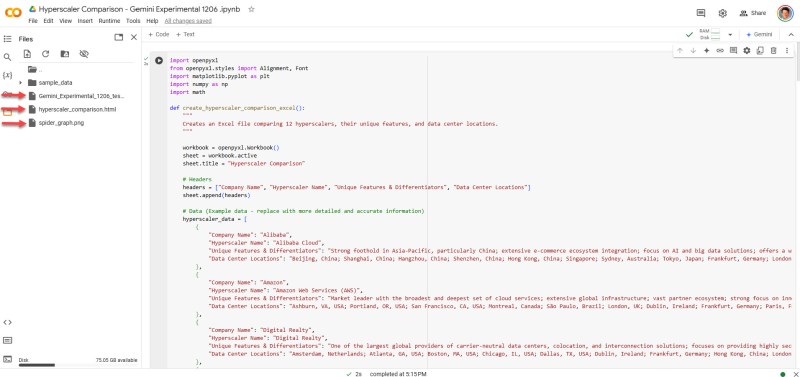
接下来,我们将代码复制到 Google Colab 中,并将其保存到一个 Jupyter 笔记本(Hyperscaler Comparison – Gemini Experimental 1206.ipynb)中,然后运行 Python 脚本。脚本运行完美,并创建了三个文件(用左上角的红色箭头表示)。
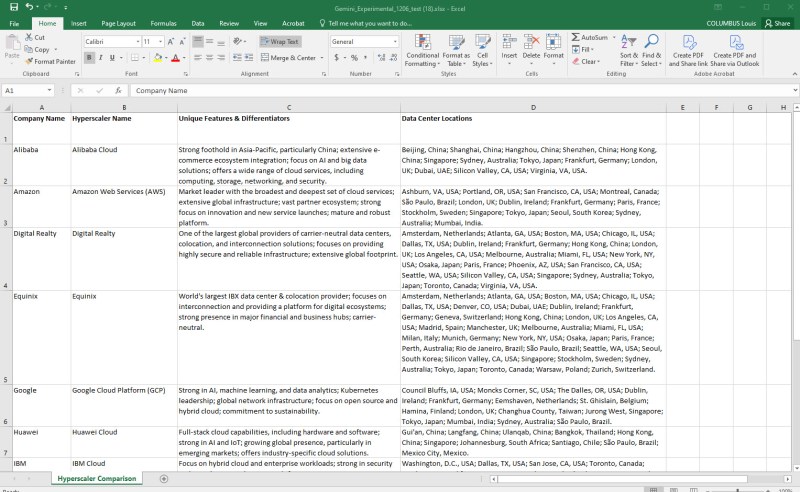
提示中的第一组指令要求 Exp-1206 创建一个 Python 脚本,该脚本将通过产品名称、独特功能和差异化因素以及数据中心位置来比较 12 个不同的超大规模企业。以下是脚本中请求的 Excel 文件的最终结果。将电子表格格式化以缩小到适合列的大小,只需不到一分钟。
下一组命令要求创建一个表格,该表格宽三列,深七列。第一列标题为 Hyperscaler,第二列为 Unique Features & Differentiators,第三列为 Infrastructure and Data Center Locations。将列标题加粗并居中。将超大规模企业的标题也加粗。仔细检查以确保此表格中每个单元格内的文本环绕,并且不会跨入下一个单元格。调整每行的高度以确保所有文本都能适合其目标单元格。此表格比较了亚马逊网络服务 (AWS)、谷歌云平台 (GCP)、IBM 云、Meta Platforms (Facebook)、微软 Azure 和 Oracle 云。将表格居中在输出页面的顶部。
接下来,以亚马逊网络服务 (AWS)、谷歌云平台 (GCP)、IBM 云、Meta Platforms (Facebook)、微软 Azure 和 Oracle 云为例,定义该组中最具差异化的八个方面。使用这八个差异化方面创建一个蜘蛛图,比较这六个超大规模企业。创建一个单一的、大型的蜘蛛图,清晰地显示这六个超大规模企业的差异,使用不同的颜色来提高其可读性和查看不同超大规模企业轮廓或足迹的能力。确保标题为“What Most Differentiates Hyperscalers, December 2024”。确保图例完全可见,并且不在图形顶部。
将蜘蛛图添加到页面的底部。将蜘蛛图居中在输出页面上的表格下方。
以下是在 Python 脚本中包含的超大规模企业:阿里云、亚马逊网络服务 (AWS)、Digital Realty、Equinix、谷歌云平台 (GCP)、华为、IBM 云、Meta Platforms (Facebook)、微软 Azure、NTT 全球数据中心、Oracle 云和腾讯云。





