人工智能的“视觉思考”:赋予AI空间推理能力
人类在解决问题时,往往会在脑海中构建问题的视觉模型。一项新的研究表明,赋予人工智能类似的“视觉思考”能力,可以显著提升其在空间推理方面的表现。
大型语言模型在许多基于文本的任务中表现出色,但在需要更复杂推理的任务中却常常力不从心。为了提升其在这些任务中的表现,一种名为“思维链”(CoT)的提示方法应运而生。该方法引导模型逐步思考问题,并取得了显著的成果,尤其是在数学、编码和逻辑推理方面。
然而,这种以语言为中心的技巧在需要空间或视觉推理的问题上效果并不理想。为了弥合这一差距,剑桥大学和微软研究院的研究人员开发了一种新方法,让AI能够同时进行文本和图像的“思考”。
该技术使能够处理图像和文本数据的多模态大型语言模型能够生成其中间推理步骤的视觉表示。在arXiv上发布的非同行评审研究中,研究人员报告称,当他们在涉及二维迷宫的空间推理挑战中测试该方法时,与传统的CoT方法相比,他们在最具挑战性的场景中观察到了显著的改进。
剑桥大学的博士生、该论文的共同主要作者李成祖表示:“空间关系、布局以及一些几何特征很难用纯文本描述。这就是我们认为仅用文本推理会限制模型在空间任务中的表现的原因,这也是引入视觉‘思考’的主要动机。”
AI视觉推理的工作原理
这并非首次尝试让AI进行视觉推理。但李成祖表示,以往的方法要么涉及从图像中提取信息并将其转换为文本,然后进行推理,要么依赖于外部软件工具或专门的视觉模型来实现视觉推理。
新方法使单个多模态模型能够自行生成视觉和文本推理步骤。李成祖表示,这项工作直到最近才成为可能,这得益于更强大的多模态AI的开发。早期的模型可以解释图像和文本,但只能生成文本输出。在这些实验中,研究人员使用了一个名为Anole的模型,该模型可以以任何一种模态进行响应。
该模型是Meta的Chameleon多模态模型的开源扩展:Anole背后的研究人员对其进行了重新训练,使其能够生成交织着图像的文本序列。例如,它可以生成一个包含每个步骤图像的分步食谱。李成祖及其同事利用这个预训练模型,并使用来自三个不同复杂程度的迷宫游戏的文本和图像数据对其进行了微调。他们将微调后的版本称为“多模态思维可视化”(MVoT)。
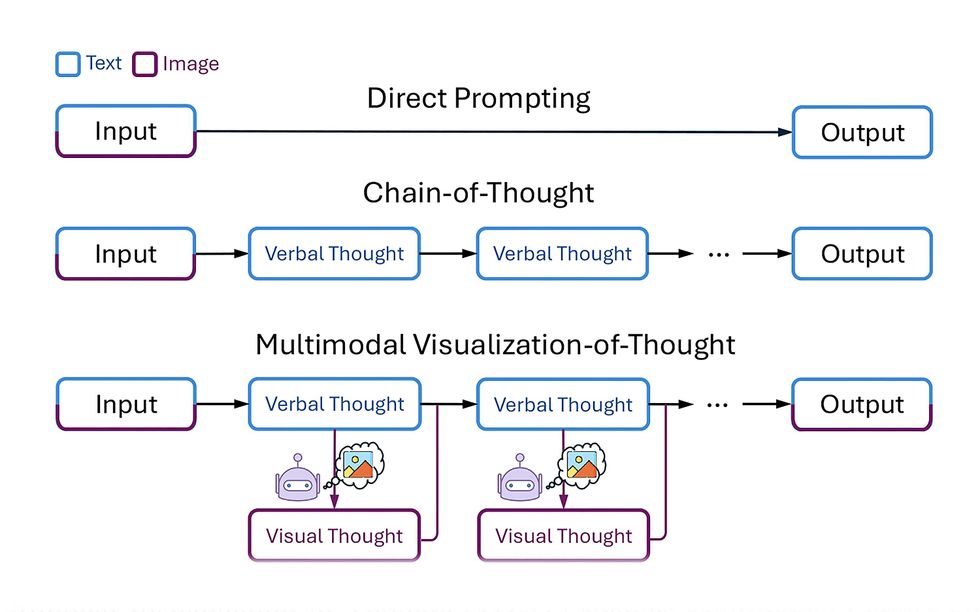
研究人员将新技术(底部)与仅用文本推理的技术(中间)和直接跳过推理直接生成答案的技术(顶部)进行了比较。
李成祖,吴文山等
该模型的目标是确定在每个迷宫中执行预定的一系列动作会发生什么。在训练过程中,模型会看到包含迷宫起始位置图像和任务文本描述的示例,以及包含动作文本描述和玩家在地图上的位置图像的推理步骤序列,最后是关于这些动作结果的答案,例如到达目标位置或掉入陷阱。
在测试过程中,模型只被提供起始图像和要执行的动作序列。然后,它会生成图像和文本推理步骤,并预测会发生什么。
研究人员将MVoT与另外四个模型进行了比较,其中三个模型是他们自己微调的。前两个版本的模型只在关于迷宫的文本数据上进行训练:一个模型直接从提示生成最终答案,另一个模型使用文本CoT推理。另一个模型在图像和文本推理示例上进行训练,但随后进行纯文本推理。最后,他们将MVoT在迷宫任务上的表现与OpenAI的GPT-4o模型的表现进行了比较,GPT-4o是该公司最先进的多模态模型。
他们发现,在所有三个游戏中,MVoT模型的表现明显优于除使用传统文本CoT的模型之外的所有模型。该模型在两个较简单的迷宫中实际上表现略好,在两个迷宫中都成功地预测了98%的结果,而MVoT的得分分别为93%和95%。但传统的文本CoT模型在最复杂的游戏中表现要差得多,得分仅为61%,而MVoT的得分则为86%。他们测试了这两个模型在越来越大的迷宫中的表现,虽然MVoT的表现保持稳定,但另一个模型的表现随着迷宫大小的增加而急剧下降。
研究人员表示,这种结果可能是因为CoT依赖于对环境的准确文本描述,而随着迷宫变得越来越复杂,这种描述也变得越来越困难。相比之下,在推理过程中加入图像似乎使MVoT在处理更具挑战性的环境方面更胜一筹。
AI视觉推理的应用
虽然研究人员使用的测试很简单,但李成祖表示,将这种方法扩展到更复杂的领域可能会带来广泛的应用。其中最引人注目的应用是机器人技术,该方法可以帮助机器更有效地推理它们从环境中获得的视觉输入。它还可以帮助AI导师更好地说明和解释想法,尤其是在几何等领域。更广泛地说,他表示,该方法可以通过为人类提供关于模型在空间任务中思考内容的清晰图像来提高模型的可解释性。
李成祖承认,一个潜在的差距是,该模型没有机制来决定何时进行视觉推理或何时进行文本推理。目前,该模型只是在两者之间交替,这对于这些具有离散步骤的迷宫导航挑战非常有效,但对于更复杂的空间推理任务可能不太合适。
李成祖表示:“我们还没有真正触及何时进行视觉推理过程或不进行视觉推理过程的问题。但我认为,这绝对是值得进一步探索的一个非常有趣的方向。”他补充说,一种可能性是,在每个步骤中生成包含视觉和文本描述的推理序列,然后让人类提供关于哪种描述更具表现力的反馈。然后,可以使用这些反馈来训练模型,使其在每个推理步骤中选择最佳选项。