

大型语言模型的代码生成能力:超越简单测试
随着大型语言模型(LLM)在代码生成领域的不断进步,用于评估其性能的基准测试正变得越来越不适用。尽管许多 LLM 在这些基准测试中取得了相似的较高分数,但要理解在特定软件开发项目和企业中使用哪种 LLM 仍然很困难。
耶鲁大学和清华大学的一篇新论文提出了一种新方法,用于测试模型解决“自调用代码生成”问题的能力,这些问题需要推理、生成代码以及在解决问题时重用现有代码。
自调用代码生成更类似于现实的编程场景,可以更好地理解当前 LLM 解决现实世界编码问题的能力。
用于评估 LLM 编码能力的两个流行基准测试是 HumanEval 和 MBPP(Mostly Basic Python Problems)。这些是手工制作的问题数据集,要求模型为简单的任务编写代码。然而,这些基准测试只涵盖了软件开发人员在现实世界中面临的挑战的一部分。在实际场景中,软件开发人员不仅要编写新代码,还要理解和重用现有代码,并创建可重用组件来解决复杂问题。
“理解并随后利用自己生成的代码,即自调用代码生成,对于 LLM 利用其推理能力进行代码生成至关重要,而当前的基准测试无法捕捉到这一点,”研究人员写道。
为了测试 LLM 在自调用代码生成方面的能力,研究人员创建了两个新的基准测试,HumanEval Pro 和 MBPP Pro,它们扩展了现有数据集。HumanEval Pro 和 MBPP Pro 中的每个问题都建立在原始数据集中现有示例的基础上,并引入了额外的元素,要求模型解决基本问题并调用解决方案来解决更复杂的问题。

例如,原始问题可以是简单的,比如编写一个函数,将字符串中所有出现的给定字符替换为一个新字符。扩展后的问题将是编写一个函数,将字符串中多个字符的出现替换为其给定的替换。这将要求模型编写一个新函数,该函数调用它在简单问题中生成的先前函数。
“这种对自调用代码生成的评估提供了对 LLM 编程能力的更深入见解,超越了单一问题代码生成的范围,”研究人员写道。
研究人员在 20 多个公开和私有模型上测试了 HumanEval Pro 和 MBPP Pro,包括 GPT-4o、OpenAI o1-mini、Claude 3.5 Sonnet,以及 Qwen、DeepSeek 和 Codestral 系列。
他们的发现表明,传统编码基准测试和自调用代码生成任务之间存在显著差异。“虽然前沿 LLM 擅长生成单个代码片段,但它们往往难以有效地利用自己生成的代码来解决更复杂的问题,”研究人员写道。
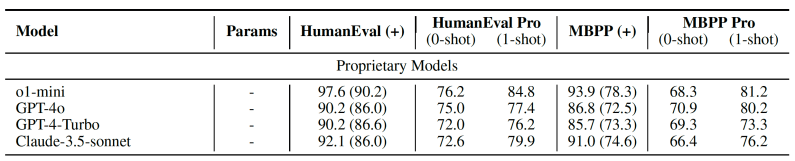
例如,使用单次生成(pass@1),o1-mini 在 HumanEval 上取得了 96.2% 的成绩,但在 HumanEval Pro 上仅取得了 76.2% 的成绩。
另一个有趣的发现是,虽然指令微调在简单的编码任务上提供了显著的改进,但在自调用代码生成上却显示出收益递减。研究人员指出,“当前基于指令的微调方法对于更复杂的自调用代码生成任务来说不够有效,”这表明我们需要重新思考如何训练基础模型来完成编码和推理任务。
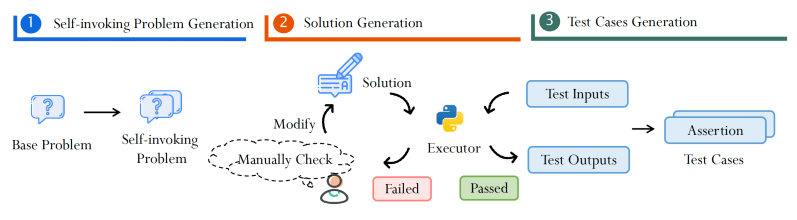
为了帮助推进自调用代码生成的研究,研究人员提出了一种技术,可以自动将现有的编码基准测试重新用于自调用代码生成。该方法使用前沿 LLM 根据原始问题生成自调用问题。然后,他们生成候选解决方案,并通过执行代码并在其上运行测试用例来验证其正确性。该流程最大限度地减少了手动代码审查的需要,有助于以更少的努力生成更多示例。
这个新的基准测试系列出现之际,旧的编码基准测试正迅速被前沿模型征服。当前的前沿模型,如 GPT-4o、o1 和 Claude 3.5 Sonnet,已经在 HumanEval 和 MBPP 以及它们更高级的版本 HumanEval+ 和 MBPP+ 上取得了非常高的分数。
与此同时,还有一些更复杂的基准测试,例如 SWE-Bench,它评估模型在端到端软件工程任务中的能力,这些任务需要广泛的技能,例如使用外部库和文件,以及管理 DevOps 工具。SWE-Bench 是一个非常困难的基准测试,即使是最先进的模型也表现出适度的性能。例如,OpenAI o1 在 SWE-Bench Verified 上表现不稳定。
自调用代码生成介于简单的基准测试和 SWE-Bench 之间。它有助于评估一种非常具体的推理能力:在模块中使用现有代码来解决复杂问题。自调用代码基准测试可以证明是评估 LLM 在现实世界环境中实用性的一个非常实用的指标,在现实世界环境中,人类程序员处于控制地位,AI 副驾驶帮助他们完成软件开发过程中的特定编码任务。
“HumanEval Pro 和 MBPP Pro 有望成为代码相关评估的宝贵基准测试,并通过揭示当前模型的不足之处,鼓励在训练方法方面的创新,从而激发未来的 LLM 开发,”研究人员写道。





