

AI 训练数据的新突破:Salesforce 推出 ProVision,程序化生成视觉指令数据
随着全球企业纷纷加码 AI 项目,高质量训练数据的获取已成为一大瓶颈。公开网络的数据资源日渐枯竭,而 OpenAI 和 Google 等巨头则通过独家合作来扩充其专有数据集,进一步限制了其他企业的获取途径。
为了应对这一挑战,Salesforce 在视觉训练数据领域迈出了重要一步,推出了 ProVision,一个能够程序化生成视觉指令数据的全新框架。这些数据集经过系统化合成,可以用于训练高性能的多模态语言模型 (MLM),使模型能够回答有关图像的问题。
Salesforce 已经发布了 ProVision-10M 数据集,并将其用于提升各种多模态 AI 模型的性能和准确性。
对于数据专业人士而言,ProVision 框架代表着重大进步。通过程序化生成高质量的视觉指令数据,ProVision 减少了对有限或标签不一致数据集的依赖,这是多模态系统训练中常见的挑战。
此外,系统化合成数据集的能力确保了更好的控制、可扩展性和一致性,从而加快迭代周期并降低获取特定领域数据的成本。这项工作是对合成数据生成领域持续研究的补充,紧随 Nvidia 发布 Cosmos 之后,Cosmos 是一套面向物理 AI 训练的世界基础模型,专门用于从文本、图像和视频等多种输入组合生成基于物理的视频。
如今,指令数据集是 AI 预训练或微调的核心。这些专门的数据集帮助模型遵循并有效地响应特定指令或查询。在多模态 AI 的情况下,模型能够在学习大量不同数据点(以及描述这些数据点的问答对,即视觉指令数据)后,分析图像等内容。
然而,生成这些视觉指令数据集并非易事。如果企业为每个训练图像手动创建数据,则会浪费大量时间和人力资源来完成项目。另一方面,如果选择使用专有语言模型来完成这项任务,则需要面对高昂的计算成本以及幻觉的风险,即问答对的质量和准确性可能不足。
此外,使用专有模型也是一个黑盒机制,因为它难以解释数据生成过程,也难以精确控制或定制输出。
为了解决这些问题,Salesforce 的 AI 研究团队开发了 ProVision 框架,该框架利用场景图与人工编写的程序相结合,系统化地合成以视觉为中心的指令数据。
场景图可以被描述为图像语义的结构化表示,其中内容中的对象被表示为节点。每个对象的属性(如颜色或大小)直接分配到其相应的节点,而这些对象之间的关系则被描绘为连接相应节点的有向边。这些表示可以来自手动标注的数据集(如 Visual Genome),也可以借助场景图生成管道生成,该管道结合了各种最先进的视觉模型,涵盖图像语义的各个方面,从对象和属性检测到深度估计。
一旦场景图准备就绪,它们就会为使用 Python 和文本模板编写的程序提供支持,这些程序充当完整的数据生成器,能够为 AI 训练管道创建问答对。
“每个 [数据] 生成器利用数百个预定义模板,这些模板系统地整合这些注释以生成多样化的指令数据。这些生成器旨在…比较、检索和推理基于每个场景图中编码的详细信息的物体、属性和关系的基本视觉概念,”框架背后的研究人员在论文中写道。
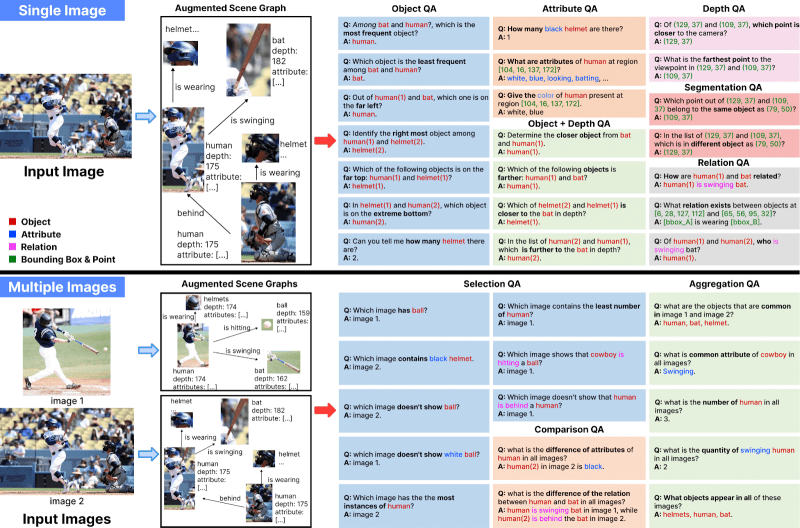
在他们的工作中,Salesforce 使用了两种方法——增强手动标注的场景图和从头开始生成——来设置场景图,为 24 个单图像数据生成器和 14 个多图像生成器提供支持。
“有了这些数据生成器,我们就可以根据图像的场景图自动合成问题和答案。例如,给定一张繁忙街道的图像,ProVision 可以生成诸如“行人和汽车之间是什么关系?”或“哪个物体更靠近红色建筑,[the] 汽车还是行人?”之类的问答对,”首席研究员张洁玉和薛乐在博客文章中指出。
第一种方法的数据生成器(使用 Depth Anything V2 和 SAM-2 从 Visual Genome 的场景图中增强深度和分割注释)帮助他们创建了 150 万个单图像指令数据点和 420 万个多图像指令数据点。同时,另一种方法(使用来自 DataComp 数据集的 12 万张高分辨率图像以及 Yolo-World、Coca、Llava-1.5 和 Osprey 等模型)生成了 230 万个单图像指令数据点和 420 万个多图像指令数据点。
总而言之,这四个部分组合起来构成了 ProVision-10M,一个包含超过 1000 万个独特指令数据点的数据集。该数据集现已在 Hugging Face 上提供,并已证明在 AI 训练管道中非常有效。
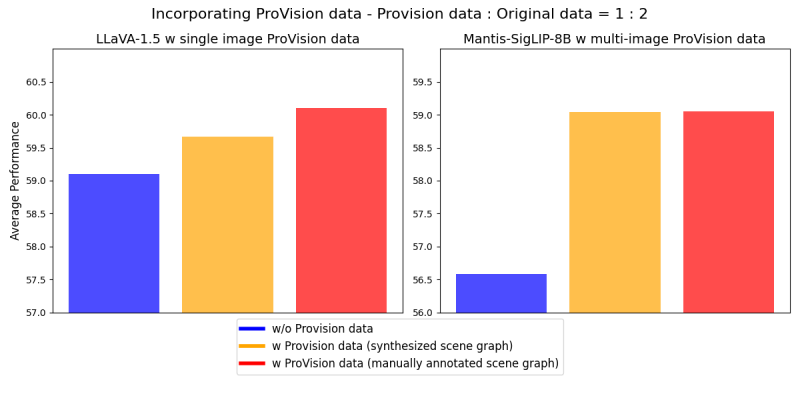
具体而言,当公司将 ProVision-10M 纳入多模态 AI 微调配方(LLaVA-1.5 用于单图像指令数据,Mantis-SigLIP-8B 用于多图像指令数据)时,观察到显著的改进,模型的平均性能高于没有 ProVision 数据的微调。
“在指令调优阶段采用我们的单图像指令数据,在 CVBench 的 2D 分割上提高了 7%,在 3D 分割上提高了 8%,在 QBench2、RealWorldQA 和 MMMU 上的性能提高了 3%。我们的多图像指令数据在 Mantis-Eval 上提高了 8%,”研究人员在论文中指出。
虽然有许多工具和平台(包括 Nvidia 新发布的 Cosmos 世界基础模型)可以生成不同类型的数据(从图像到视频),这些数据可用于多模态 AI 训练,但只有少数工具关注了创建与这些数据配对的指令数据集的问题。
Salesforce 通过 ProVision 解决了这一瓶颈,为企业提供了一种超越手动标注或黑盒语言模型的方法。程序化生成指令数据的方法确保了生成过程的可解释性和可控性,并能够高效地扩展,同时保持事实准确性。
从长远来看,Salesforce 希望研究人员能够在此基础上进一步完善场景图生成管道,并创建更多涵盖新型指令数据的生成器,例如用于视频的生成器。





