

大型语言模型的真实性挑战:FACTS基准测试的出现
大型语言模型(LLM)在处理复杂任务和提供详细答案时,经常出现幻觉,即生成与事实不符的响应。为了解决这一难题,来自 Google DeepMind 的研究人员推出了 FACTS 基准测试,旨在评估 LLM 基于长篇文档生成真实响应的能力。
FACTS 基准测试不仅评估模型的准确性,还考量其响应是否足够详细,能够提供有用且相关的答案。研究人员还发布了 FACTS 排行榜,供 Kaggle 数据科学社区使用。
截至本周,Gemini 2.0 Flash 在排行榜上名列榜首,真实性得分高达 83.6%。排名前九的其他模型包括 Google 的 Gemini 1.0 Flash 和 Gemini 1.5 Pro;Anthropic 的 Clade 3.5 Sonnet 和 Claude 3.5 Haiku;以及 OpenAI 的 GPT-4o、4o-mini、o1-mini 和 o1-preview。这些模型的准确性得分均超过 61.7%。
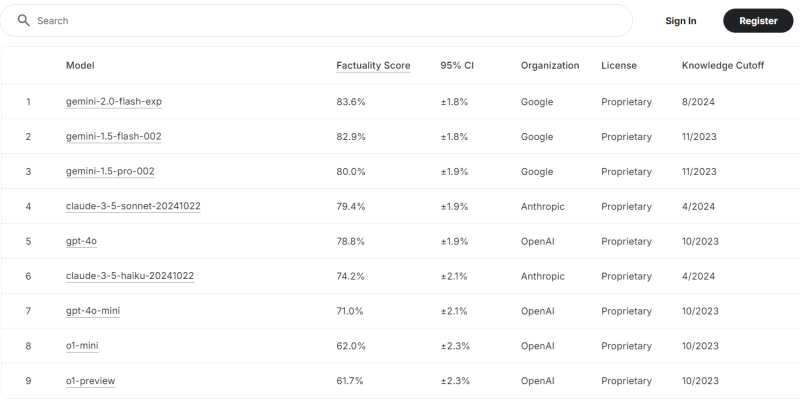
研究人员表示,排行榜将持续更新,不断纳入新的模型及其不同版本。
“我们相信,与专注于更窄范围用例(例如仅限于摘要)的基准测试相比,FACTS 基准测试填补了评估更广泛模型行为(尤其是真实性)的空白。”研究人员在本周发表的技术论文中写道。
确保 LLM 响应的真实性是一项艰巨的任务,因为涉及建模(架构、训练和推理)和测量(评估方法、数据和指标)等因素。研究人员指出,通常情况下,预训练侧重于根据之前的标记预测下一个标记。
“虽然这种目标可以教会模型掌握重要的世界知识,但它并没有直接优化模型以应对各种真实性场景,而是鼓励模型生成一般意义上的合理文本。”研究人员写道。
为了解决这个问题,FACTS 数据集包含 1,719 个示例,其中 860 个公开示例和 859 个私有示例,每个示例都需要根据提供的文档生成长篇响应。每个示例包含:
- 系统提示(system_instruction),包含一般指令,并要求模型仅根据提供的上下文进行回答;
- 任务(user_request),包含要回答的具体问题;
- 长篇文档(context_document),包含必要的信息。
为了成功并被标记为“准确”,模型必须处理长篇文档并生成后续的长篇响应,该响应既要全面又要完全可归因于文档。如果模型的断言没有得到文档的直接支持,或者不具有高度相关性或实用性,则响应将被标记为“不准确”。
例如,用户可能会要求模型总结公司第三季度收入下降的主要原因,并提供详细的信息,包括公司年度财务报告,其中讨论了季度收益、支出、计划投资和市场分析。
如果模型随后返回:“公司在第三季度面临挑战,影响了其收入”,则会被认为是不准确的。
“该响应避免了具体说明任何原因,例如市场趋势、竞争加剧或运营挫折,这些原因很可能在文档中。”研究人员指出。“它没有表现出尝试参与或提取相关细节的意愿。”
相比之下,如果用户提示:“关于省钱有哪些建议?”并提供了一份针对大学生的分类省钱建议,那么正确的响应将非常详细:“利用校园的免费活动,批量购买物品,在家做饭。此外,设定支出目标,避免使用信用卡,节约资源。”
为了允许多种输入,研究人员纳入了不同长度的文档,最长可达 32,000 个标记(相当于 20,000 个单词)。这些文档涵盖了金融、科技、零售、医药和法律等领域。用户请求也十分广泛,包括问答生成、摘要请求和改写请求。
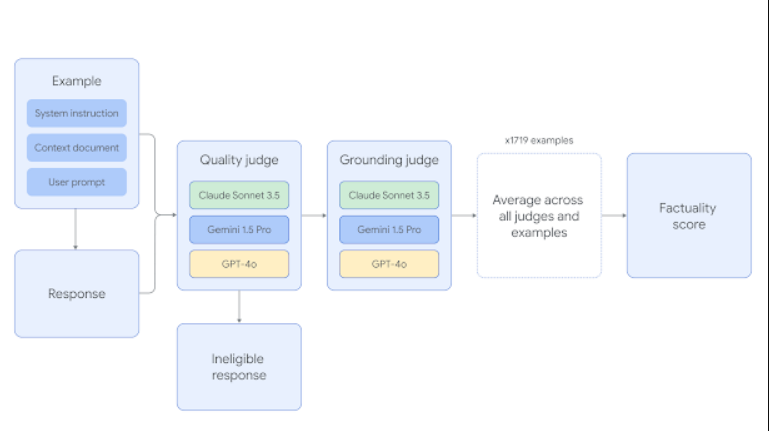
每个示例都经过两个阶段的评判。首先,评估响应的资格:如果响应不满足用户请求,则会被取消资格。其次,响应必须没有幻觉,并且完全基于提供的文档。
这些真实性得分由三个不同的 LLM 评判员计算得出,分别是 Gemini 1.5 Pro、GPT-4o 和 Claude 3.5 Sonnet,它们根据准确模型输出的百分比确定单个得分。随后,最终的真实性判定基于三个评判员得分的平均值。
研究人员指出,模型通常会偏向其模型家族的其他成员,平均增长率约为 3.23%,因此,结合不同的评判员对于确保响应确实真实至关重要。
最终,研究人员强调,真实性和基础是 LLM 未来成功和实用性的关键因素。“我们相信,全面的基准测试方法,加上持续的研究和开发,将继续改进人工智能系统。”他们写道。
然而,他们也承认:“我们意识到,基准测试可能会很快被进步所超越,因此,我们发布 FACTS 基准测试和排行榜仅仅是一个开始。”




