

谷歌 Gemini AI 的“秘密武器”:实时多流视觉处理
谷歌的 Gemini AI 悄然改变了人工智能领域,它取得了一项前所未有的成就:实时处理多个视觉流。这一突破让 Gemini 不仅能够观看实时视频流,还能同时分析静态图像,这在人工智能领域是一个巨大的飞跃。
这项突破并非通过谷歌的旗舰平台发布,而是来自一个名为“AnyChat”的实验性应用程序。AnyChat 巧妙地利用了 Gemini 架构的潜力,突破了 AI 处理复杂多模态交互的界限。多年来,AI 平台一直局限于处理实时视频流或静态照片,但从未同时处理两者。AnyChat 彻底打破了这一障碍。
Gradio 的机器学习负责人,AnyChat 的创造者 Ahsen Khaliq 在接受 VentureBeat 独家采访时表示:“即使是 Gemini 的付费服务目前也无法做到这一点。现在,你可以与 AI 进行真实的对话,同时它还能处理你的实时视频流和你想分享的任何图像。”
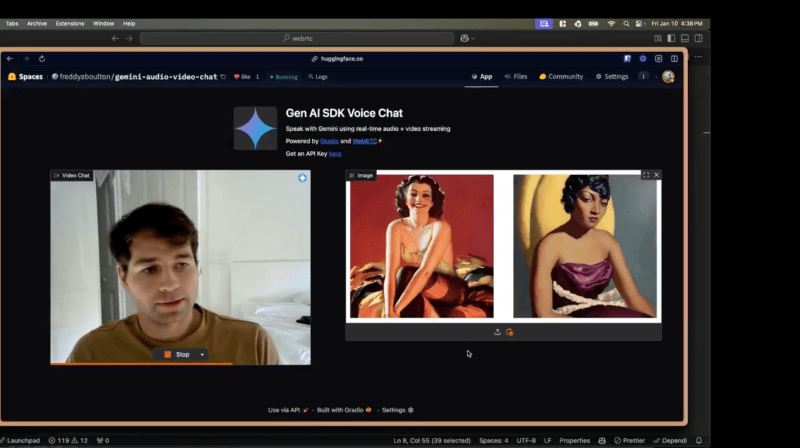
Gemini 多流处理能力背后的技术成就在于其先进的神经网络架构,AnyChat 巧妙地利用了这种架构,能够在不牺牲性能的情况下处理多个视觉输入。这种能力已经存在于 Gemini 的 API 中,但尚未在谷歌面向最终用户的官方应用程序中提供。
相比之下,包括 ChatGPT 在内的许多 AI 平台的计算需求限制了它们只能进行单流处理。例如,ChatGPT 目前在上传图像时会禁用实时视频流。即使处理一个视频流也会消耗大量资源,更不用说将其与静态图像分析结合起来。
这项突破的潜在应用既具有变革性,也具有即时性。学生现在可以将摄像头对准一个微积分问题,同时向 Gemini 展示教科书,以获得逐步指导。艺术家可以分享正在进行的作品以及参考图像,并获得关于构图和技巧的细致入微的实时反馈。
AnyChat 的成就之所以引人注目,不仅在于技术本身,还在于它绕过了 Gemini 官方部署的限制。这一突破得益于谷歌 Gemini 团队的特殊授权,使 AnyChat 能够访问谷歌自身平台中尚未提供的功能。
利用这些扩展的权限,AnyChat 优化了 Gemini 的注意力机制,能够同时跟踪和分析多个视觉输入,同时保持对话连贯性。开发人员可以使用几行代码轻松地复制这种能力,正如 AnyChat 使用 Gradio(一个用于构建机器学习界面的开源平台)所证明的那样。

这种简单性突出了 AnyChat 不仅仅是 Gemini 潜力的展示,也是开发人员构建自定义视觉 AI 应用程序的工具包。
AnyChat 的成功并非偶然。该平台的开发人员与 Gemini 的技术架构紧密合作,以扩展其极限。通过这样做,他们揭示了 Gemini 的一面,即使是谷歌的官方工具也尚未探索。
这种实验性方法使 AnyChat 能够处理实时视频和静态图像的同步流,实质上打破了“单流障碍”。结果是一个平台,它感觉更加动态、直观,并且能够比其竞争对手更有效地处理现实世界的用例。
Gemini 新功能的影响远远超出了创意工具和休闲 AI 交互。想象一下,一位医务人员同时向 AI 展示患者的实时症状和历史诊断扫描。工程师可以将实时设备性能与技术图表进行比较,并获得即时反馈。质量控制团队可以将生产线输出与参考标准进行匹配,从而实现前所未有的准确性和效率。
在教育领域,这种潜力具有变革意义。学生可以使用 Gemini 实时分析教科书,同时解决练习题,获得能够弥合静态和动态学习环境之间差距的上下文感知支持。对于艺术家和设计师来说,能够同时展示多个视觉输入为创意协作和反馈开辟了新的途径。
目前,AnyChat 仍然是一个实验性的开发者平台,它使用 Gemini 开发人员授予的扩展速率限制运行。然而,它的成功证明了同步的多流 AI 视觉不再是遥不可及的愿望,它已经成为现实,准备大规模采用。
AnyChat 的出现引发了一些发人深省的问题。为什么 Gemini 的官方发布没有包含这种能力?是疏忽、资源分配的故意选择,还是表明规模更小、更灵活的开发人员正在推动下一波创新浪潮?
随着 AI 竞赛的加速,AnyChat 的教训很清楚:最重大的进步并不总是来自科技巨头的庞大研究实验室。相反,它们可能来自独立的开发人员,他们看到了现有技术的潜力,并敢于将其推向更远。
现在,Gemini 的突破性架构已被证明能够进行多流处理,为新一代 AI 应用奠定了基础。谷歌是否会将其功能整合到其官方平台中尚不确定。然而,有一点是明确的:AI 的能力与其官方应用之间的差距变得更加有趣了。




