

突破记忆瓶颈:谷歌新型神经网络架构Titans
大型语言模型(LLM)在处理长序列信息时面临着巨大的挑战:如何扩展其推理时的记忆能力,同时避免内存和计算成本的爆炸式增长。谷歌研究人员开发了一种名为Titans的新型神经网络架构,有望解决这一难题。
Titans将传统的LLM注意力模块与“神经记忆”层相结合,使模型能够高效地处理短期和长期记忆任务。研究人员表示,采用神经长期记忆的LLM可以扩展到数百万个token,并且在参数数量远少于经典LLM和Mamba等替代方案的情况下,性能依然优于后者。
LLM中常用的经典Transformer架构利用自注意力机制来计算token之间的关系。这种方法非常有效,可以学习token序列中复杂而细致的模式。然而,随着序列长度的增长,计算和存储注意力的成本呈二次方增长。
近年来,一些研究人员提出了具有线性复杂度的替代架构,可以扩展而不导致内存和计算成本的爆炸式增长。然而,谷歌研究人员认为,线性模型的性能与经典Transformer相比并不具有竞争力,因为它们会压缩上下文数据,导致遗漏重要细节。
他们认为,理想的架构应该拥有不同的记忆组件,这些组件可以协调工作,利用现有知识,记忆新事实,并从其上下文中学习抽象概念。
“我们认为,在有效的学习范式中,类似于人脑,存在着不同的但相互连接的模块,每个模块负责学习过程中的一个关键组成部分,”研究人员写道。
“记忆是一个由多个系统组成的联盟——例如,短期记忆、工作记忆和长期记忆——每个系统都执行不同的功能,具有不同的神经结构,并且能够独立运行,”研究人员写道。
为了弥补当前语言模型的不足,研究人员提出了一种“神经长期记忆”模块,该模块可以在推理时学习新信息,而不会像完整注意力机制那样效率低下。神经记忆模块不是在训练期间存储信息,而是学习一个函数,该函数可以在推理期间记忆新事实,并根据遇到的数据动态调整记忆过程。这解决了其他神经网络架构所面临的泛化问题。
为了决定哪些信息值得存储,神经记忆模块使用了“惊讶”的概念。token序列与模型权重和现有记忆中存储的信息类型差异越大,它就越令人惊讶,因此越值得记忆。这使得该模块能够有效地利用其有限的记忆,只存储对模型已知信息有用的数据片段。
为了处理非常长的数据序列,神经记忆模块具有自适应遗忘机制,允许它删除不再需要的信息,这有助于管理记忆的有限容量。
记忆模块可以与当前Transformer模型的注意力机制相辅相成,研究人员将其描述为“短期记忆模块,关注当前上下文窗口大小。另一方面,我们能够持续从数据中学习并将其存储在权重中的神经记忆可以扮演长期记忆的角色。”
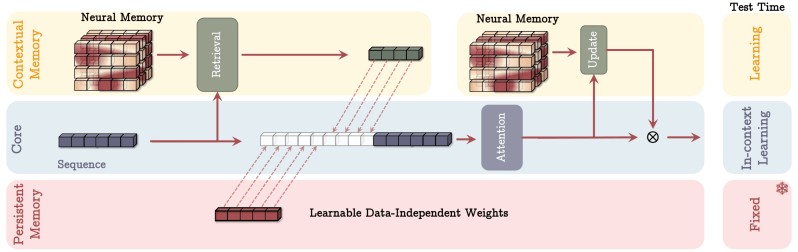
研究人员将Titans描述为一个模型家族,它将现有的Transformer模块与神经记忆模块相结合。该模型具有三个关键组件:“核心”模块,充当短期记忆,使用经典的注意力机制来关注模型正在处理的输入token的当前片段;“长期记忆”模块,使用神经记忆架构来存储超出当前上下文的的信息;以及“持久记忆”模块,可学习的参数,在训练后保持固定,并存储与时间无关的知识。
研究人员提出了连接这三个组件的不同方法。但总的来说,这种架构的主要优势在于使注意力和记忆模块能够相互补充。例如,注意力层可以使用历史和当前上下文来确定当前上下文窗口的哪些部分应该存储在长期记忆中。同时,长期记忆提供了当前注意力上下文中不存在的历史知识。
研究人员在各种任务上对Titans模型进行了小规模测试,包括语言建模和长序列语言任务,模型参数范围从1.7亿到7.6亿。他们将Titans的性能与各种基于Transformer的模型、Mamba等线性模型以及Samba等混合模型进行了比较。
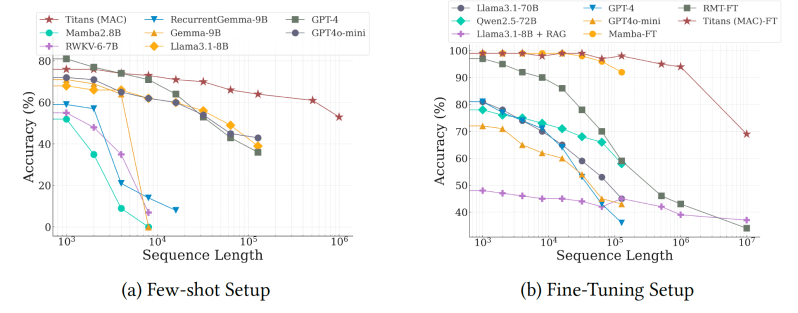
Titans在语言建模方面表现出强大的性能,优于其他模型,并且在参数规模相似的情况下,性能优于Transformer和线性模型。
在长序列任务中,这种性能差异尤为明显,例如“大海捞针”,模型必须从非常长的序列中检索信息片段;以及BABILong,模型必须对分布在非常长文档中的事实进行推理。事实上,在这些任务中,Titans的性能优于参数数量大几个数量级的模型,包括GPT-4和GPT-4o-mini,以及增强了检索增强生成(RAG)的Llama-3模型。
此外,研究人员能够将Titans的上下文窗口扩展到200万个token,同时将内存成本保持在适度水平。
这些模型还需要在更大的规模上进行测试,但论文中的结果表明,研究人员还没有触及Titans潜力的上限。
鉴于谷歌在长上下文模型领域处于领先地位,我们可以预期这种技术将应用于Gemini和Gemma等私有和开源模型。
随着LLM支持更长的上下文窗口,创建应用程序的潜力越来越大,您可以在提示中加入新知识,而不是使用RAG等技术。开发和迭代基于提示的应用程序的开发周期比复杂的RAG管道快得多。同时,Titans等架构可以帮助降低非常长序列的推理成本,使公司能够为更多用例部署LLM应用程序。
谷歌计划发布用于训练和评估Titans模型的PyTorch和JAX代码。





