

AI 新星崛起:DeepSeek R1 搅动硅谷
DeepSeek,这家由香港量化分析公司 High-Flyer Capital Management 旗下的子公司,凭借其最新发布的开源大型推理模型 DeepSeek R1,在硅谷和全球范围内掀起了一场风暴。DeepSeek R1 的性能与 OpenAI 最强大的模型 o1 相媲美,但训练成本却低得多,无论是对用户还是对 DeepSeek 本身。
DeepSeek R1 的出现,彻底改变了原本就竞争激烈、瞬息万变的 AI 模型市场。此前,OpenAI、Anthropic 和 Google 在争夺最强大的专有模型方面势均力敌,而 Meta Platforms 则以其开源模型紧追其后。然而,这次不同的是,DeepSeek 背后的公司来自中国,这个与美国存在地缘政治“友敌”关系的国家,其科技领域一直被认为落后于硅谷。
DeepSeek R1 的横空出世,让美国和西方科技界人士感到不安,他们开始质疑 OpenAI 以及科技巨头们一味投入资金和算力(图形处理单元,GPU,通常用于训练 AI 模型的强大游戏芯片)来开发更强大模型的策略。
然而,一些西方科技领袖对 DeepSeek 的快速崛起持积极态度。
Mosaic 浏览器联合创始人、Netscape 浏览器公司联合创始人、著名风险投资公司 Andreessen Horowitz(a16z)合伙人 Marc Andreessen 在 X 上发文称:“DeepSeek R1 是我见过的最令人惊叹、最令人印象深刻的突破之一——而且作为开源模型,它对世界来说是一份宝贵的礼物 [机器人表情,敬礼表情]。”
Meta 基础人工智能研究(FAIR)部门首席人工智能科学家 Yann LeCun 在 LinkedIn 上写道:
“看到 DeepSeek 的表现,有些人可能会想:‘中国在 AI 领域超越了美国。’这种想法是错误的。正确的理解应该是:‘开源模型正在超越专有模型。’DeepSeek 从开源研究和开源软件(例如 Meta 的 PyTorch 和 Llama)中获益匪浅。他们提出了新的想法,并在此基础上进行构建。由于他们的工作是公开发布的,并且是开源的,所以每个人都可以从中获益。
这就是开源研究和开源软件的力量。”
甚至 Meta AI 的创始人兼首席执行官马克·扎克伯格(Mark “Zuck” Zuckerberg)似乎也试图用自己的帖子来对抗 DeepSeek 的崛起。他在 Facebook 上承诺,Facebook 的开源 AI 模型家族 Llama 的新版本将在今年发布时成为“最先进的模型”。他写道:
“今年将是 AI 的决定性一年。我预计到 2025 年,Meta AI 将成为领先的助手,服务超过 10 亿人,Llama 4 将成为最先进的模型,我们将构建一个 AI 工程师,它将开始为我们的研发工作贡献越来越多的代码。为了实现这一目标,Meta 正在建设一个 2GW+ 的数据中心,其规模之大,足以覆盖曼哈顿的很大一部分。我们将在 2025 年上线约 1GW 的算力,并在年底拥有超过 130 万个 GPU。我们计划今年在资本支出方面投入 600-650 亿美元,同时大幅扩大我们的 AI 团队,并且我们有资金在未来几年继续投资。这是一项巨大的努力,在未来几年,它将推动我们的核心产品和业务,解锁历史性的创新,并扩展美国的技术领先地位。让我们一起努力吧!”
他还分享了一张图片,展示了他在帖子中提到的 2 吉瓦数据中心叠加在曼哈顿上的样子:
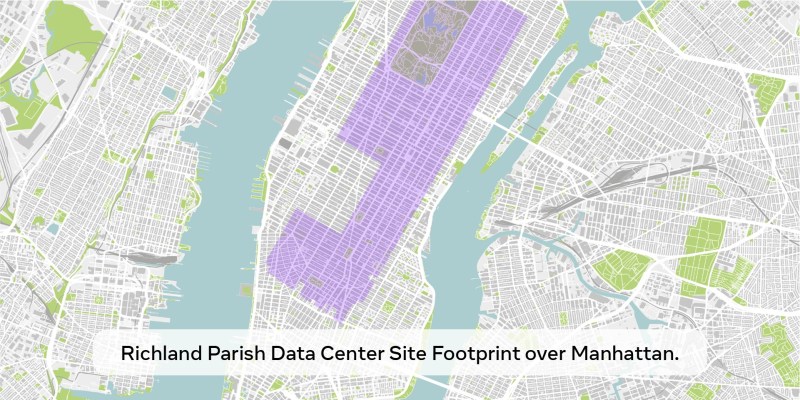
显然,尽管扎克伯格宣称致力于开源 AI,但他并不相信 DeepSeek 优化效率、使用比大型实验室少得多的 GPU 的方法是 Meta 或者 AI 未来发展的正确方向。
然而,随着美国公司在新的 AI 基础设施上投入或支出创纪录的资金,而许多专家指出这些基础设施贬值速度很快(由于硬件/芯片和软件的进步),一个问题仍然存在:最终哪种愿景将胜出,成为全球主要的 AI 提供商?或者,也许未来将是多种模型并存,每个模型都拥有较小的市场份额?让我们拭目以待,因为这场竞争正变得比以往任何时候都更加激烈。





