

开源大模型竞赛再添新成员:Ai2 推出 Tülu 3 405B,挑战 GPT-4o 和 DeepSeek V3
开源大模型的竞争愈发激烈,而 Allen Institute for AI (Ai2) 今天发布了其最新的大型语言模型 (LLM) Tülu 3 405B,正式加入这场竞赛。
Tülu 3 405B 不仅在性能上与 OpenAI 的 GPT-4o 旗鼓相当,更在关键基准测试中超越了 DeepSeek 的 V3 模型。
这并非 Ai2 首次在模型发布时提出大胆的宣称。早在 2024 年 11 月,Ai2 就发布了 Tülu 3 的首个版本,包含 80 亿和 700 亿参数的两个版本。当时,Ai2 声称该模型与 OpenAI 的最新 GPT-4 模型、Anthropic 的 Claude 和 Google 的 Gemini 性能相当。而 Tülu 3 的最大优势在于其开源特性。早在 2024 年 9 月,Ai2 就宣称其 Molmo 模型在某些基准测试中超越了 GPT-4o 和 Claude。
虽然基准测试性能数据固然重要,但更值得关注的是 Tülu 3 405B 背后的训练创新。
突破性训练技术:将后训练推向极致
Tülu 3 405B 的突破性进展源于 2024 年 Tülu 3 首个版本中首次出现的创新技术。该版本结合了先进的后训练技术,以提升模型性能。
在 Tülu 3 405B 模型中,这些后训练技术得到了进一步的优化,采用了先进的后训练方法,将监督微调、偏好学习和一种新颖的强化学习方法相结合,并在更大规模上展现出卓越的效果。
“将 Tülu 3 的后训练方法应用于 Tülu 3-405B,这是我们迄今为止规模最大、完全开源的后训练模型,通过提供开放的微调方法、数据和代码,赋能开发者和研究人员,使其能够实现与顶级闭源模型相当的性能。”Ai2 NLP 研究高级总监 Hannaneh Hajishirzi 对 VentureBeat 表示。
RLVR 推动开源 AI 后训练技术发展
后训练是其他模型,包括 DeepSeek v3,也采用的技术。
Tülu 3 的关键创新在于 Ai2 的可验证奖励强化学习 (RLVR) 系统。
与传统的训练方法不同,RLVR 使用可验证的结果,例如正确解决数学问题,来微调模型的性能。这种技术与直接偏好优化 (DPO) 和精心策划的训练数据相结合,使模型能够在复杂推理任务中实现更高的准确性,同时保持强大的安全性。
RLVR 实现中的关键技术创新包括:
- 在 256 个 GPU 上实现高效的并行处理
- 优化权重同步
- 在 32 个节点上实现均衡的计算分配
- 集成 vLLM 部署,采用 16 路张量并行
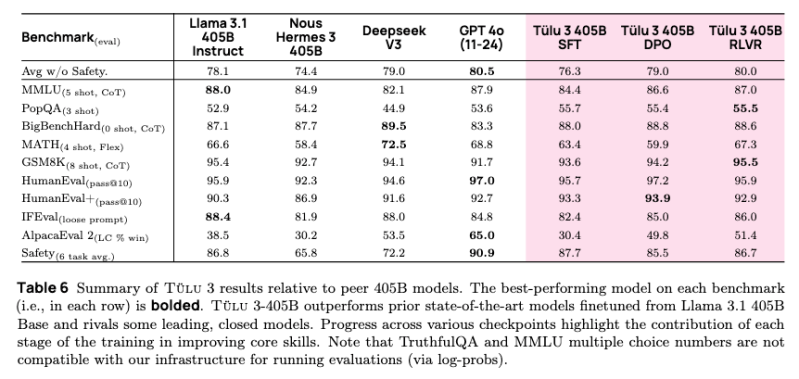
与较小的模型相比,RLVR 系统在 405B 参数规模上展现出更好的效果。该系统在安全性评估中也表现出色,超越了 DeepSeek V3、Llama 3.1 和 Nous Hermes 3。值得注意的是,RLVR 框架的有效性随着模型规模的增加而提升,表明在更大规模的实现中可能存在潜在的优势。
在当前的 AI 环境中,Tülu 3 405B 的竞争地位尤为引人注目。
Tülu 3 405B 不仅与 GPT-4o 的能力相当,还在某些方面,特别是安全性基准测试中,超越了 DeepSeek v3。
在包括安全性基准测试在内的 10 个 AI 基准测试评估中,Ai2 报告称 Tülu 3 405B RLVR 模型的平均得分达到 80.7,超过了 DeepSeek V3 的 75.9。然而,Tülu 在 GPT-4o 上的表现略逊一筹,得分 81.6。总体而言,这些指标表明 Tülu 3 405B 在这些基准测试中至少与 GPT-4o 和 DeepSeek V3 具有极强的竞争力。
然而,Tülu 3 405B 对用户来说真正与众不同的是 Ai2 的发布方式。
在 AI 市场中,关于开源的讨论很多。DeepSeek 声称自己是开源的,Meta 的 Llama 3.1 也是如此,而 Tülu 3 405B 也超越了后者。
DeepSeek 和 Llama 的模型都可以免费使用,但并非所有代码都公开。
例如,DeepSeek-R1 发布了其模型代码和预训练权重,但没有发布训练数据。Ai2 则采取了不同的方式,试图更加开放。
“我们没有使用任何闭源数据集,”Hajishirzi 说。“与 2024 年 11 月发布的第一个 Tulu 3 版本一样,我们发布了所有基础设施代码。”
她补充说,Ai2 的完全开放方式,包括数据、训练代码和模型,确保用户可以轻松地定制自己的管道,从数据选择到评估。用户可以在 Ai2 的 Tulu 3 页面上访问完整的 Tulu 3 模型套件,包括 Tulu 3-405B,或通过 Ai2 的 Playground 演示空间测试 Tulu 3-405B 的功能。





