

UC Berkeley于2025年8月在arXiv上发表的论文《Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First》,对Agent使用数据库的负载特征进行了量化分析。该研究结合这些负载特征,提出了Agent-First数据库的架构设想及其所需具备的关键能力。
前言
文章《AI Agent 需要什么样的数据库?》曾总结了AI Agent使用数据库的负载特征及数据库所需具备的能力:
| 负载特征 | 能力要求 |
|---|---|
| 即时创建 | 极短的冷启动时长,提供极佳的用户体验。 |
| 大量小实例 / 活跃时长不稳定 | 自动弹性伸缩,降低平台成本。 |
| 反复调试 | 快速 PITR,提供任意时间点的快速数据恢复能力。 |
其中,“即时创建”、“大量小实例”和“活跃时长不稳定”主要反映数据库实例生命周期层面的负载特征。然而,Agent使用SQL查询的具体特征,该文章并未深入分析。
尽管反复调试与SQL查询紧密相关,但缺乏定量分析,导致以下关键问题仍未得到解答:
“Agent 需要反复调试多少次才能成功?”
“Agent 查询数据库的 SQL 本身有哪些特征?”
“有多少 SQL 是重复多次查询的?”
“怎样才能帮助 Agent 减少调试的次数?”
明确Agent使用SQL查询的这些负载特征,对于设计Agent-First数据库至关重要。
UC Berkeley的论文《Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First》针对上述问题给出了答案,并提出了对Agent-First数据库的未来构想。
Agent SQL 查询的负载特征
为明确Agent使用SQL的特征,论文基于BIRD Text2SQL benchmark进行分析,并对比了GPT-4o-mini和Qwen2.5-Coder-7B-Instruct两个模型,后端数据库采用DuckDB。
BIRD Text2SQL benchmark包含12,751个Question-SQL对,分布在95个库中,数据量达33.4GB。测试过程是将自然语言的Question发送给Agent,由Agent生成SQL并查询数据库,最终对比Agent生成的SQL与答案SQL的查询结果和时长。
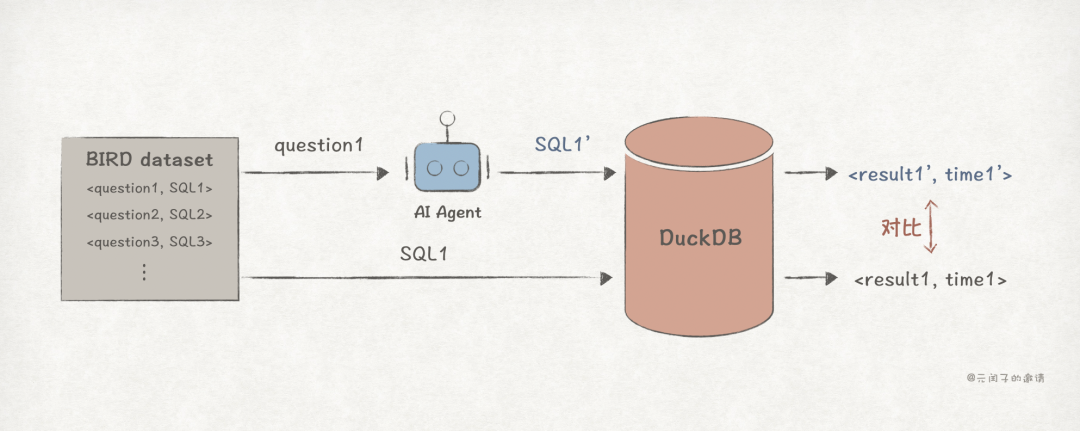
研究得出了如下分析结论。
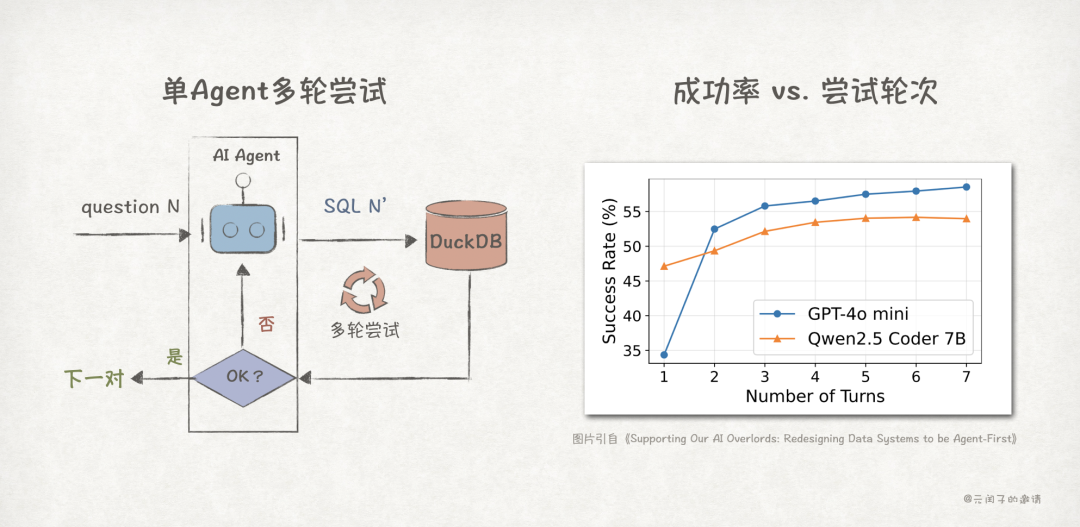
结论 1:单 Agent 多轮尝试或多 Agent 并发尝试有助于提升 SQL 查询正确率
如下所示,单Agent随着尝试轮次的增加,任务成功率呈增长趋势,但5轮后增长减弱,稳定在55%左右。
采用多个Agent并发执行任务,也能提升任务成功率。如下图所示,当并发数增加到50时,成功率可达70%左右。
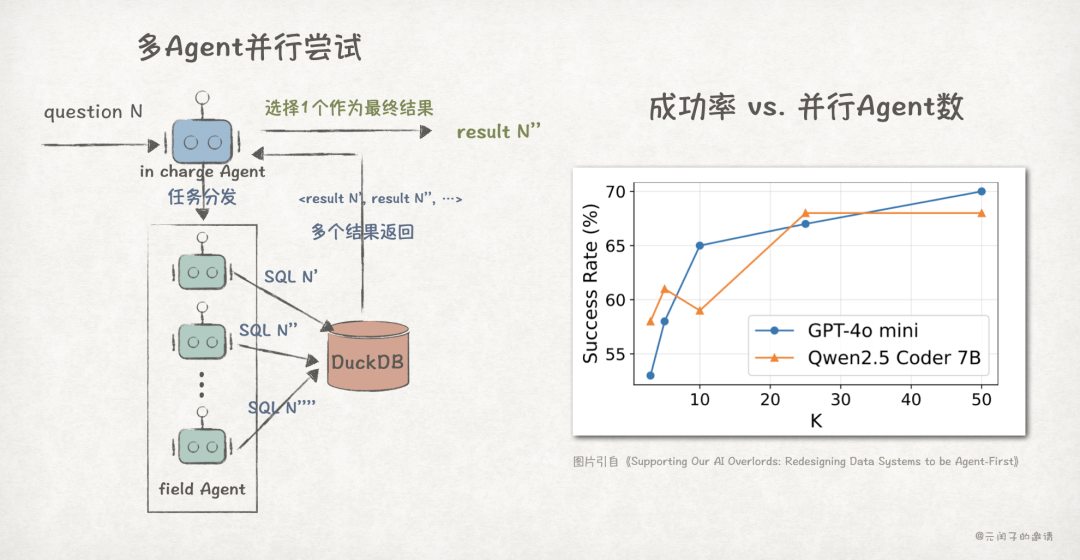
无论是单Agent多轮尝试,还是多Agent并发尝试,都将导致请求吞吐量呈倍级、甚至数十倍级的提升,对数据库的性能提出了更高的要求。
结论 2:Agent 有大量重复的 SQL 查询,占总查询数的 80%~90%
在多Agent并行尝试的方案下,取K=50,观察在BIRD dataset下产生的所有执行计划,得到算子的分布如下:
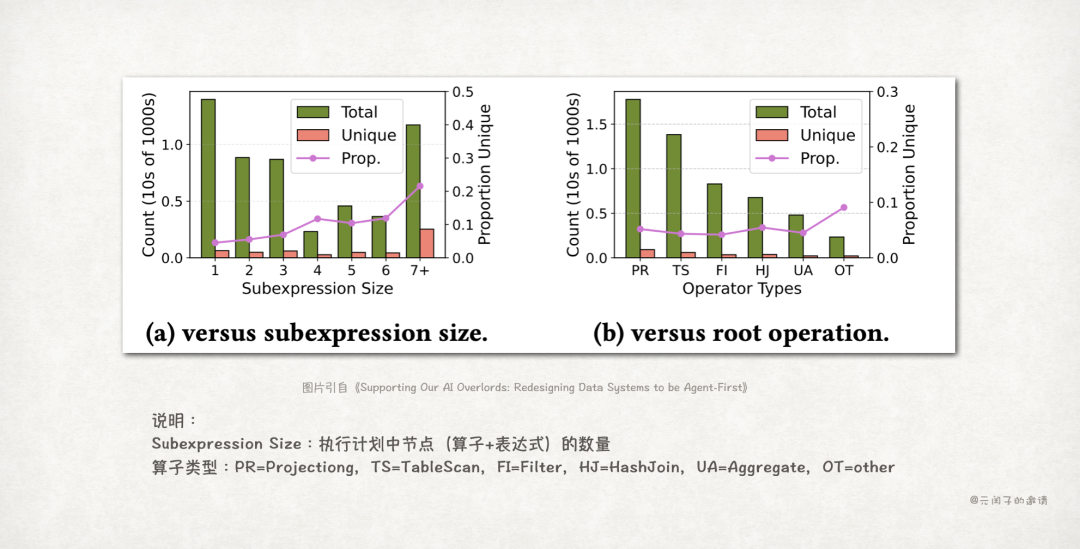
上图从两个维度展现了SQL的重复程度:
(a) 不同的执行计划的节点数可能不同,在不同规模的执行计划下,unique节点的占比只有5%~22%(Prop. 曲线)。
(b) 按照节点(算子)类型归类,无重复节点(算子类型相同,算子中表达式不同)的占比只有5%~10% (Prop. 曲线)。
大量的重复查询意味着,缓存或记忆,将是提升Agent访问数据库性能的关键。
结论 3:Agent 的 SQL 查询类型是多样的
当Agent接收到数据查询任务时,它并不会立即生成结果查询SQL,而是会先进行探索,例如查找有哪些表、表中有哪些列等。
论文将Agent完成数据查询任务时执行的SQL划分为四种类型:
- 探索表(exploring tables):查询数据库中都有哪些表。
- 探索列(exploring specifical columns):查询指定表中有哪些列。
- 中间查询(attempting part of the query):基于前两步信息,构建中间查询,开始尝试查询相关数据。
- 完整查询(attempting entire query):根据子查询生成完整的SQL,并执行查询,得到最终结果。
由此可见,Agent首先进行粗粒度的元数据查询,随后逐步执行从部分到整体的数据查询,直至任务完成。
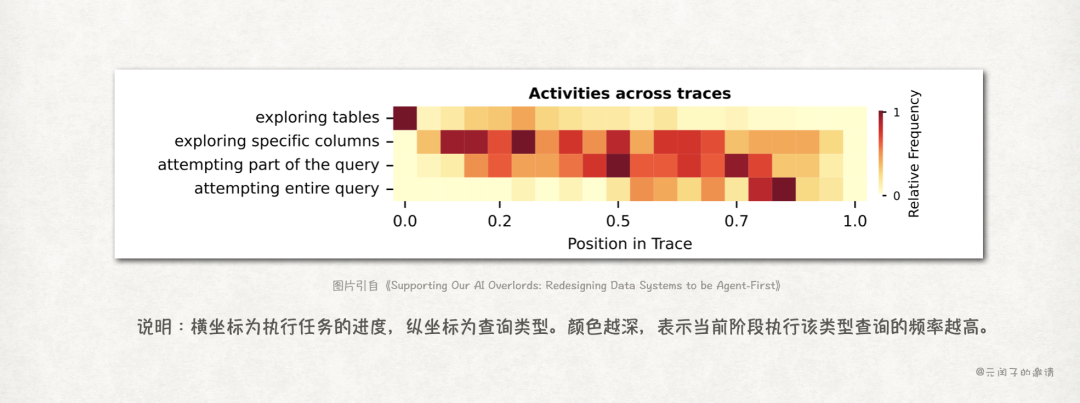
当然,Agent不一定会严格按照这四种SQL类型顺序执行。如上图所示,在任务执行过程中,Agent大部分时间都处于试错阶段,反复探索列和执行中间查询。
结论 4:适当的引导可以有效降低 Agent 完成一项任务的轮次
如果Agent大部分时间都在试错,这意味着数据库大部分时间都在做无用功,浪费资源。
若对Agent进行适当引导,例如告知Agent完成该任务所需的表和列有哪些,能否减少这些无用功?
论文对此进行了对比实验,结果数据如下:
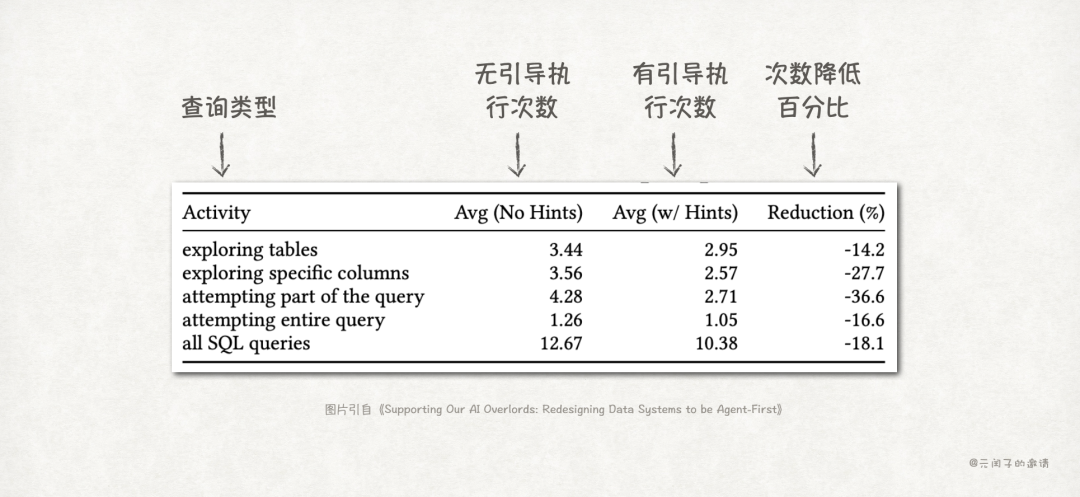
结果显示,适当的引导可降低总SQL查询次数达18.1%!其中,探索列和中间查询的降幅最大,分别达到27.7%和36.6%。
论文将满足上述特征的Agent负载称为Agentic Speculation。
显然,专为人类设计的传统数据库已难以高效支持Agentic Speculation。数据库需要从被动的查询执行者,转型为能与Agent主动协作的伙伴,即Agent-First数据库。
Agent-First 数据库
论文提出了Agent-First数据库的架构畅想,如下图所示:
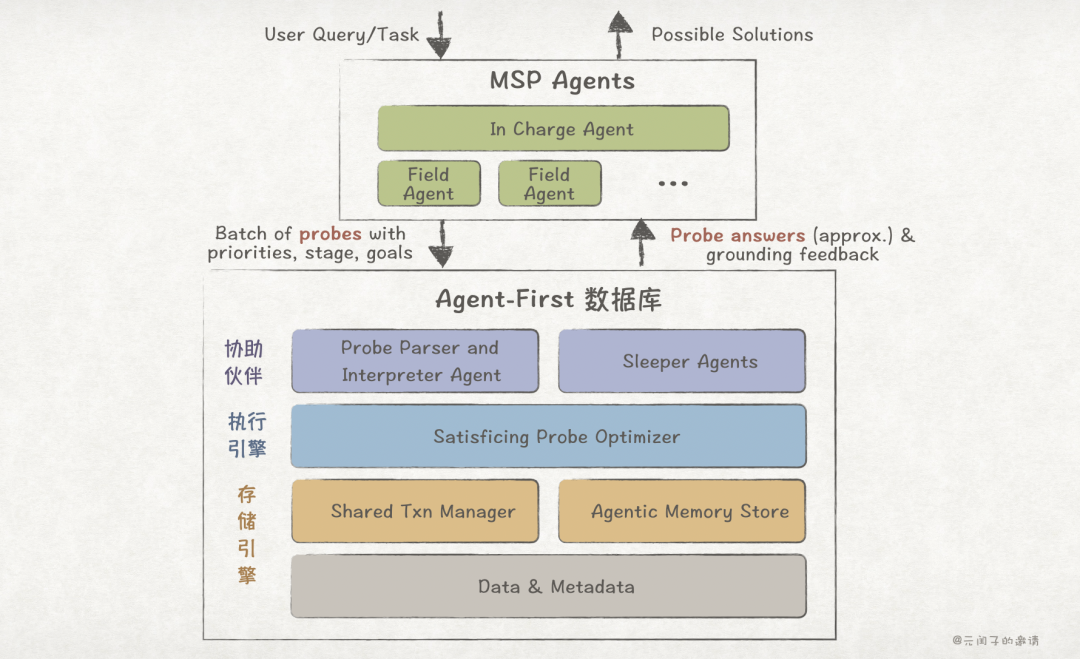
Agent-First数据库不再是对传统数据库的修补,而是一种与Agent深度融合的重构。
查询方式的重构
首先,Agent与数据库交互的语言,不再是SQL,而是一批Probe。
Probe不仅包含SQL,还附带一段由自然语言描述的背景信息,这主要起到引导作用,有助于减少Agent的反复试错。
背景信息可以包含如下内容:
- 查询意图。阐述本次查询的最终目的,为数据库提供方向性指导。
- 查询阶段。元数据探索阶段和数据查询阶段对数据的精度、调度优先级均有不同要求。
- 查询精度。例如,可以指定查询结果无需100%精确,80%即可。
- 优先级。在本批Probe中,当前查询的优先级,便于数据库更好地调度。
- 终止条件。例如,在全表扫描请求中,指定查询终止条件为扫描80%数据即可,或查询时长不超过1ms。
- 开放性目标。例如,当Agent需要了解美国东西海岸的销售差异时,可以下达一个开放性指令:“请从东西海岸各选两个州,生成统计数据,具体选择哪些州由数据库自行决定,以效率最高为准。” 这是传统SQL难以实现的功能。
通过背景信息,Probe极大扩展了SQL语义查询的功能。
在数据库侧,库内Agent替代传统的SQL解析器。
Probe Parser and Interpreter Agent会解析Probe,随后提交给后端执行查询;
此外,数据库会按需唤醒一个或多个Sleeper Agents,它们不直接回答主要问题,而是提供辅助信息和成本建议:
- Sleeper Agents拥有数据分布的全景图,可帮助MSP Agents更好地理解数据本身。
例如,Sleeper Agents可以推荐相关表:“您查询了orders表,可能还需要查询customers表。”
例如,解释查询结果:“您的查询结果为空,原因并非没有相关数据,而是列名CA有误,正确的列名是California。”
- Sleeper Agents还能给出查询效率和成本建议,帮助MSP Agents更高效地进行查询。
例如,“本次全美数据查询请求成本过高,是否考虑先查询加州数据?”
例如,“系统发现您正在连续独立查询50个州的数据,将其合并为一个批处理请求将显著提升效率。”
最终,数据库会将查询结果和这些建议打包返回给MSP Agents,这体现了从被动应答到主动引导的转变。
查询优化的重构
其次,查询优化器的目标不再是传统数据库那样“最快地给出单次查询的精确结果”,而是“用最小的总时间代价,完成本批次以及未来批次的Probes查询任务”。查询结果不一定是精确的,只要能完成MSP Agents交代的任务即可。
这意味着查询优化器不仅要局限于当前批次的优化,更需具备根据历史交互记录和最终目标,预测未来查询的能力。
对于当前批次优化(Intra-Probe Optimization):
-
近似替代精确。例如,优化器发现当前处于探索阶段,可适当降低查询精度,减少资源消耗。
-
避免“因小便宜吃大亏”。例如,当前查询若返回一个低精度的结果,很可能引发更多轮的查询,得不偿失。这就需要优化器综合考虑当前数据库自身的状态、系统资源,决定在本轮或下一轮执行精确查询。
-
动态调整计划。执行计划从静态转变为动态,例如,对于A列,最初优化的结果是设置查询精度为80%,但随着查询的执行,发现系统资源不足,便主动将精度调整为60%。
对于多轮批次优化(Inter-Probe Optimizations):
- 基于增量信息做剪枝,避免做无用功。例如,若上一批次Probe P查询了
<用户姓名, 年龄>,而本批次Probe P’又需查询<用户姓名, 年龄, 电话>,优化器会分析新增的“电话”信息是否对最终目标有益。若无益,则直接舍弃,避免重复查询。 - 提前准备好下一批查询的结果。例如,若优化器发现Agent正反复对
users和orders表进行JOIN查询,便可主动将两表JOIN的结果通过物化视图缓存,以提升后续查询效率。
数据索引的重构
对于传统数据库而言,业务流程通常是固定的。
例如,应用知晓哪些列会被频繁查询,即可预先为这些列建立索引,从而提升随机查询性能。
例如,若应用属于OLAP业务,则会采用列式存储以提升复杂分析查询性能。
然而,Agent的业务流程具有动态性,查询类型也呈多样化。它可以是对元数据的探索性查询、也可以是精确数据查询;可以是TP业务的点查,也可以是AP业务的批量扫描;可以是全文检索,也可以是向量检索。
另外,Agent还会存在大量重复的查询。
因此,仅依靠传统的索引机制,已难以高效支撑Agentic Speculation。
还需要引入Agent记忆存储:
- 存储知识。存储元数据,例如该表有哪些列,每列的类型是什么,以提升探索查询阶段的性能。
- 存储经验。存储过去的查询结果,使得下次查询能够直接复用,避免重复查询。
事务管理的重构
Agent会存在大量的“What-if”式探索流程。论文中提到,Neon数据库统计数据显示,Agent创建的数据分支数量是人类的20倍、Agent执行数据回滚的次数是人类的50倍。
这决定了Agent之间的数据操作需要良好的隔离性,以避免相互影响。
传统的MVCC事务隔离机制已无法应对这种场景。MVCC旨在让多个并发事务互不干扰,感知不到对方的存在。其处理的是短暂的、并行的“现在”。其所有版本最终都会被清理,历史轨迹始终为一条直线,规模小且短暂。
然而,Agent的“What-if”探索旨在创建无数个平行的“未来”,需要同时保留成百上千个数据快照,并在每个快照上运行调试、比较结果,最终选择最优的“未来”。因此,其历史是一个庞大的树状结构,规模大且持久。
类似于Git的数据分支机制,无疑更适合Agent大量的“What-if”事务管理需求。
此外,鉴于Agent会频繁调试数据,快速创建和回滚分支是其必备能力。该能力可基于Copy-on-Write、Redirect-on-Write等技术实现。
在数据分支能力方面,Neon数据库走在了业界前列,其相关实现细节可参考文章《AI Agent 需要什么样的数据库?》。
最后
Agent SQL查询的负载特征与Agent-First数据库所需能力总结如下:
| Agent SQL 查询负载特征 | Agent-First 数据库能力 |
|---|---|
| 高吞吐量 | 批量 Probe 处理、跨批查询优化 |
| 高重复率 | 查询优化器主动增加结果缓存、Agent 记忆存储 |
| 多样性 | Agent 记忆存储 |
| 可引导 | Probe 替代 SQL、Sleeper Agents 提供辅助信息和成本建议 |
| 大量 “What-if” 探索 | 数据分支替代 MVCC 事务隔离 |
虽然论文给出了Agent-First数据库的架构,但这更多是一种对未来的畅想,离真正落地还有许多技术难题待解决。
其中最突出的问题是成本高昂。
Agent-First数据库在内部署了多个LLM Agent,每次数据查询可能涉及多Agent协作,这可能导致极高的查询成本和时延。
此外,如何处理库内Agent记忆更新、如何实现高效查询优化策略等,都仍需深入研究。
然而,随着AI Agent在今年的飞速发展,Agent-First数据库的出现或许指日可待。
参考
[1] Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First, UC Berkeley
[2]AI Agent 需要什么样的数据库?, 元闰子



