

Dify单实例在10 QPS压力下CPU使用率飙升至100%,导致智能客服机器人瘫痪,影响当日30%咨询转化率。对依赖Dify构建AI应用的企业而言,99.9%可用性意味着每年8.76小时的系统停机时间,而99.99%的可用性则可将停机时间压缩至52.56分钟。本文将基于Dify v0.6.9版本,系统拆解5大实战方案,以实现Dify从“能用”到“稳定可用”的跨越,深入探讨高可用部署的关键策略与实践。
理论基础:高可用指标与架构脆弱性
核心指标
- MTBF(平均无故障时间):目标>1000小时
- MTTR(平均恢复时间):需控制在5分钟内
- 可用性公式:
可用性 = MTBF / (MTBF + MTTR),99.99%要求MTTR<5分钟
Dify架构脆弱点
- Python性能瓶颈:GIL锁导致并发能力弱,4C8G单实例在10 QPS下触发CPU瓶颈(实测数据来自Dify官方压测报告)
- 工作流引擎共用:多应用共享引擎,状态流转管理加剧资源竞争,某金融科技公司实测3个应用并发时响应延迟增加200%
- 长链路调用:插件化架构导致多hop调用,链路可用性=各节点可用性乘积(3节点各99.9%时链路可用性仅99.7%)
实战方案一:基础设施层——多可用区部署与智能流量治理
问题场景
公司生产环境单可用区电力故障导致服务中断2小时,传统Nginx在处理SSE流式传输和自动故障转移方面存在不足,造成智能风控系统瘫痪。
技术方案
“主-备可用区+Higress AI网关”架构(适用Dify v0.6.9+):
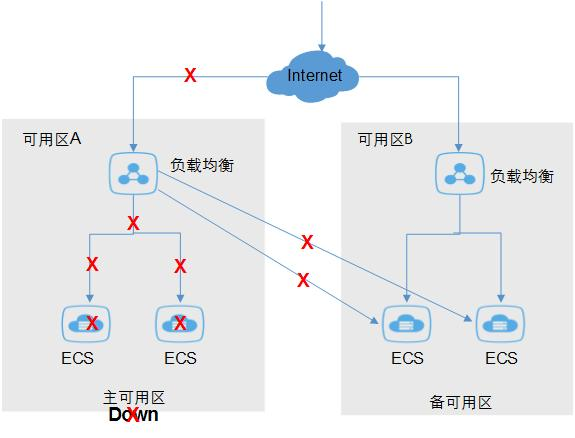
Dify多可用区部署架构
实施步骤
① 跨AZ部署应用实例,每个AZ至少2副本,确保单AZ故障时服务不中断
② 配置Higress限流规则,防止流量突增冲垮系统:
apiVersion: networking.higress.io/v1
kind: WasmPlugin
metadata: {name: dify-ratelimit}
spec:
plugin: ratelimit
config:
rateLimits:
- actions: [{generic_key: {descriptor_value: "dify-api"}}]
limit: {requests_per_unit: 100, unit: minute} # 按分钟限流100 QPS③ 启用本地优先路由策略,将跨AZ流量延迟从30ms降至8ms
验证方法
- 故障注入测试:关闭主AZ实例,观察流量自动切换至备AZ,业务中断<10秒
- 压测验证:模拟200 QPS流量,CPU使用率稳定在70%以下,无请求丢失
注意事项
- 选用Higress v1.5.0+版本,支持SSE流式传输无损转发
- 多AZ部署需同步数据库跨区复制,RDS PostgreSQL推荐采用“三地五中心”架构
实战方案二:数据库层——主从复制+读写分离+定时备份
问题场景
公司知识库批量导入场景中,单实例PostgreSQL读写冲突导致响应延迟从200ms增至2s,影响信贷审批效率。
技术方案
PostgreSQL 15主从架构(适用Dify v0.6.9+):
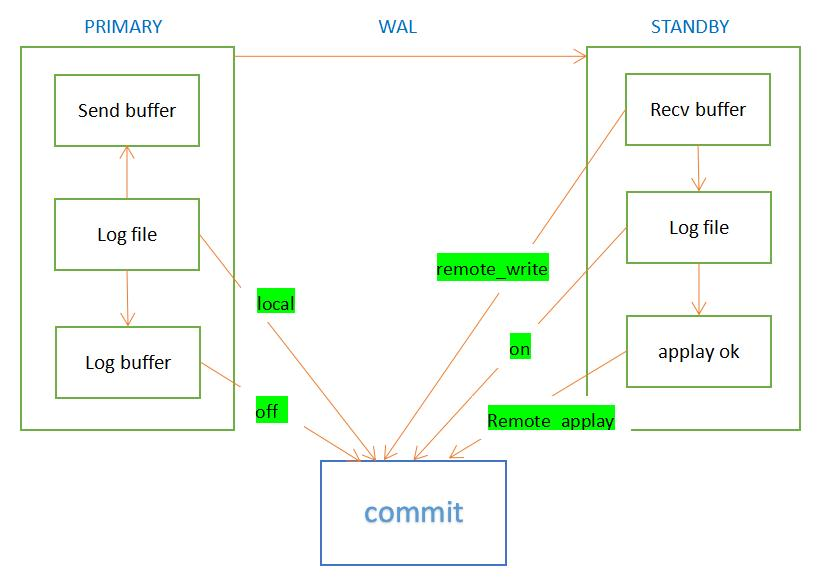
PostgreSQL主从复制_Dify架构
实施步骤
① 主库配置(生产环境推荐4C16G):
services:
db_primary:
image: postgres:15-alpine # 选用alpine镜像减少资源占用
environment: {POSTGRES_PASSWORD: "difyai123456"}
command: postgres -c wal_level=replica -c max_wal_senders=3 # 开启WAL复制
volumes: ["./volumes/db/primary:/var/lib/postgresql/data"]② 从库配置:通过pg_basebackup实现数据同步,延迟控制<100ms
③ 定时备份脚本:
#!/bin/bash
# 每日凌晨2点执行全量备份,保留7天历史数据
pg_basebackup -h db_primary -U repluser -D /backup/$(date +%Y%m%d) -F t -P
find /backup -type d -mtime +7 -exec rm -rf {} ; # 自动清理过期备份验证方法
- 主从同步检查:
psql -c "select now() - pg_last_xact_replay_timestamp() as delay" - 读写分离测试:写请求路由至主库,读请求分流至从库,QPS提升至200+
注意事项
- 主从切换需配合Keepalived实现自动故障转移
- 备份文件建议上传至对象存储(如S3/OBS),避免单点存储风险
实战方案三:缓存层——Redis Cluster与向量数据库融合
问题场景
平台知识库检索接口频繁查询相同商品文档片段,PostgreSQL负载过高,QPS仅50,用户等待时间超3秒。
技术方案
3主3从Redis Cluster+Milvus向量数据库(适用Dify v0.6.9+):
- Redis存储热点商品数据(TTL=1小时),Milvus加速向量检索(HNSW索引)
- 微服务架构拆分检索服务,通过LLMOps流程实现灰度发布
实施步骤
① Redis Cluster部署:
# 创建6个节点(3主3从)
for port in {7000..7005}; do
mkdir -p ./redis/$port
cat > ./redis/$port/redis.conf << EOF
port $port
cluster-enabled yes
cluster-config-file nodes.conf
appendonly yes
requirepass "dify_redis" # 启用密码认证
masterauth "dify_redis"
EOF
done② Milvus配置:创建collection时指定向量维度(如768维BERT嵌入)
③ 缓存策略:对TOP 1000商品知识库查询结果缓存,命中率提升至85%
验证方法
- 缓存命中率监控:通过Redis
INFO stats查看keyspace_hits/keyspace_misses - 检索延迟测试:Milvus向量查询延迟<50ms,整体接口QPS提升至500+
注意事项
- Redis Cluster不支持
pub/sub全功能,需改用Sentinel模式保障消息可靠性 - Milvus建议部署独立集群,避免与应用服务资源竞争
实战方案四:应用层——K8s无状态部署与自动扩缩容
问题场景
平台高峰期(晚间8-10点)CPU使用率达90%,响应延迟3s,手动扩容不及时导致学员投诉率上升15%。
技术方案
Kubernetes无状态部署+HorizontalPodAutoscaler(适用Dify v0.6.9+):
实施步骤
① 部署清单(dify-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata: {name: dify-api}
spec:
replicas: 3
selector: {matchLabels: {app: dify-api}}
template:
metadata: {labels: {app: dify-api}}
spec:
containers:
- name: dify-api
image: langgenius/dify-api:0.6.9 # 指定Dify版本
ports: [{containerPort: 5001}]
resources: {requests: {cpu: "1", memory: "2Gi"}, limits: {cpu: "2", memory: "4Gi"}}② HPA配置:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata: {name: dify-api-hpa}
spec:
scaleTargetRef: {apiVersion: apps/v1, kind: Deployment, name: dify-api}
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource: {name: cpu, target: {type: Utilization, averageUtilization: 70}} # CPU使用率70%触发扩容验证方法
- 负载测试:使用Locust模拟1000用户并发,HPA自动扩容至8副本
- 故障转移测试:手动删除Pod,K8s在30秒内重建新实例
注意事项
- 确保应用无状态:会话数据存储至Redis,文件存储至对象存储
- 配置PodDisruptionBudget:
minAvailable: 2防止滚动更新时服务不可用
实战方案五:监控告警——全链路可观测性
问题场景
Dify部署后,因缺乏关键指标监控,Redis集群切换时未及时发现主从延迟,导致数据一致性问题。
技术方案
Prometheus+Grafana+Alertmanager监控体系:
- 核心指标:API响应时间(P99<500ms)、数据库复制延迟(<100ms)、Redis内存使用率(<80%)
- 故障自愈:通过K8s livenessProbe自动重启异常Pod
实施步骤
① Prometheus告警规则(dify-alerts.yaml):
groups:
- name: dify_alerts
rules:
- alert: ApiHighErrorRate
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.05
for: 2m
labels: {severity: critical}
annotations: {summary: "API错误率过高", description: "5xx错误率超过5%持续2分钟"}
- alert: DbReplicationLag
expr: pg_replication_lag > 100ms
for: 1m
labels: {severity: warning}② Grafana看板:导入模板1860(PostgreSQL)+ 8919(Redis)+ 12856(K8s)
验证方法
- 告警触发测试:手动停止从库同步,验证告警在1分钟内触发
- 全链路追踪:通过Jaeger查看API→数据库→缓存调用链耗时分布
注意事项
- Prometheus建议部署持久化存储,保留15天历史数据
- 关键告警配置电话/短信通知,避免监控盲区
避坑指南:三大高可用误区
误区1:盲目GPU扩容
案例:未优化工作流,直接扩容GPU至8卡,利用率仅30%。
解决方案:采用Celery异步队列拆分任务,优先优化Prompt工程减少Token消耗
误区2:忽视跨AZ网络延迟
案例:多AZ部署时未配置本地优先路由,30ms延迟导致SSE流式对话卡顿。
解决方案:通过Higress网关配置地理路由策略,优先将请求转发至同AZ实例
误区3:监控盲区
案例:遗漏Redis集群cluster_state指标监控,主从切换失败未及时发现。
解决方案:补充关键指标监控(如redis_cluster_state{state="fail"}),设置紧急告警
未来趋势:Serverless架构对Dify高可用部署的影响
Serverless架构(如AWS Lambda+API Gateway)通过“按需付费+自动扩缩容”特性,为Dify部署提供新思路:
- 秒级弹性:流量低谷时缩容至0实例,高峰期自动扩容至百级并发
- 成本优化:非工作时间资源成本降低70%,适合中小团队试错
- 架构简化:无需管理K8s节点,聚焦业务逻辑开发




