

引言
提示词工程聚焦数年后,出现新术语:上下文工程(context engineering)。使用语言模型构建应用,从“为提示词寻找合适的词语”,转变为“什么样的上下文配置最可能产生期望的模型行为”。
上下文(Context):大型语言模型(LLM)使用时包含的token集合。
工程(engineering)问题:针对LLM约束优化这些token的使用,下方将说明为何需要约束。
使用LLM需要在上下文中思考:考虑LLM在任何时刻可用的整体状态,及该状态可能产生的行为。
本文旨在探讨上下文工程,提供思维模型,用于构建可控、有效的智能体。
对比:上下文工程 vs. 提示词工程
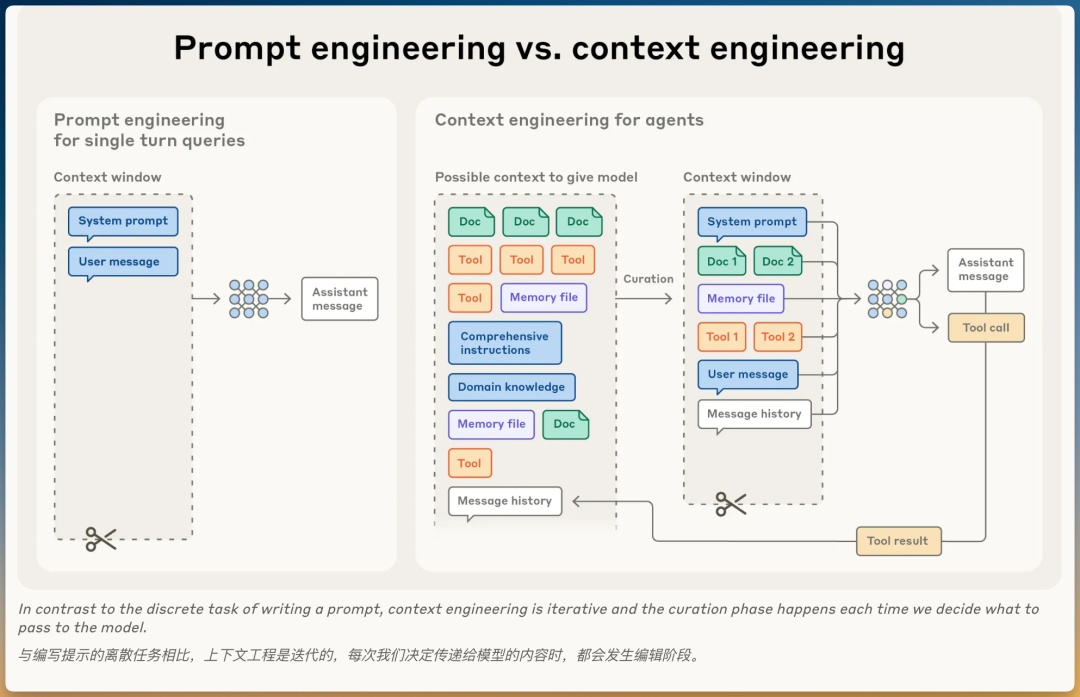
提示词工程
- • 定义:编写和组织LLM指令的方法
- • 关注点:如何编写有效提示词,特别是系统提示词
- • 适用场景:单次分类或文本生成任务
上下文工程
- • 定义:在LLM推理期间选择和维护最优token集合的策略
- • 范围:包括提示词之外进入上下文的所有信息(系统指令、工具、MCP、外部数据、消息历史等)
- • 适用场景:多轮推理、长时间运行的智能体
为什么需要演进?
智能体在循环运行中生成越来越多可能相关的数据,这些信息必须循环精炼。
上下文工程的核心:从不断演化的可能信息中选择什么进入有限上下文窗口。
关键区别
提示词工程:离散任务(写一次提示词)
上下文工程:迭代过程(每次推理都要决定传递什么给模型)
为什么上下文工程对构建智能体重要
核心问题:上下文腐化
LLM像人类一样,在某个点会失去焦点或困惑。
“大海捞针”式基准测试研究揭示上下文腐化(context rot)现象:
- • 上下文窗口token数量增加
- • 模型准确回忆信息的能力下降
这一特性出现在所有模型中。
根本原因:注意力预算有限
上下文是边际收益递减的有限资源。
如同人类拥有有限工作记忆容量,LLM解析大量上下文时动用“注意力预算”:
- • 每个新token消耗预算一部分
- • 需要选择LLM可用token
架构约束
这种注意力稀缺源于LLM架构约束。
LLM基于transformer架构:
- • 每个token关注整个上下文中的每个其他token
- • 导致n个token间存在n²个成对关系
上下文长度增加 → 模型捕获成对关系的能力被拉伸稀薄 → 上下文大小和注意力焦点间产生张力。
训练数据的限制
模型训练时:
- • 见过的短文本很多(如短对话、短文章)
- • 见过的长文本很少(如长文档、长对话)
结果:
- • 模型擅长处理短上下文
- • 处理长上下文时能力不足
- • 难以准确记住距离很远的信息之间的关系
类比:就像学生主要练习短跑,偶尔跑一次马拉松,那他马拉松成绩自然不如短跑。
扩大上下文窗口的局限
有人可能会想:直接扩大上下文窗口不就行了?
确实有技术可以让模型处理更长的上下文(位置编码插值技术),但有代价:
效果:
- • 不是到某个长度突然完全失效(断崖式)
- • 而是越长,准确率越低(渐进式)
具体表现:
- • 模型在较长上下文中仍能工作
- • 但信息检索和长程推理的精度会降低
- • 越长的上下文,精度下降越明显
类比:就像人的注意力——可以同时看10个屏幕,但记忆准确度会比看1个屏幕低很多。
结论
这些现实意味着上下文工程对构建智能体至关重要。
即使技术进步允许更长上下文,仍需要精心选择放入什么信息。
上下文的构成
受限于有限注意力预算,好的上下文工程意味着找到最小的有效token集合,最大化期望结果的可能性。
下面概述这一原则在上下文不同组成部分中的实际意义。
系统提示词
系统提示词应清晰、简单、直接,保持适度的抽象程度。
两种极端,一个平衡点
适度的抽象程度意味着在两种失败模式间找平衡:
❌ 极端1:过度硬编码
- • 在提示词中硬编码复杂、脆弱的逻辑
- • 试图引出精确智能体行为
- • 问题:创造脆弱性,维护复杂性随时间增加
❌ 极端2:过于模糊
- • 提供模糊的高级指导
- • 无法给LLM提供期望输出的具体信号
- • 问题:错误假设共享上下文
✅ 平衡点:适度抽象
- • 足够具体:能引导行为
- • 足够灵活:为模型提供强启发式

组织建议
将提示词组织成不同部分:
- •
<background_information>背景信息 - •
<instructions>指令 - •
## Tool guidance工具指导 - •
## Output description输出描述
使用XML标签或Markdown标题划分这些部分。
💡 随着模型变强,提示词格式可能变得不那么重要
最小信息集原则
追求完全符合预期行为的最小信息集。
注意:
- • 最小 ≠ 短
- • 仍需预先给智能体足够信息确保它遵守期望行为
迭代优化流程
- 1.起点:用最佳可用模型测试最小提示词
- 2.观察:看它在任务上表现如何
- 3.改进:根据初始测试中发现的失败模式添加清晰指令和示例
工具
工具允许智能体与环境交互,在工作时引入新的额外上下文。
核心作用
工具定义智能体与其信息/行动空间间的契约。
工具促进效率的两个方面:
- • 返回token高效的信息
- • 鼓励高效的智能体行为
设计原则
类似设计良好的代码库的函数,工具应满足:
1. 自包含
- • 一个工具完成一件完整的事
- • 不需要依赖其他工具配合
- • ✅ 好例子:
search_file(keyword)– 直接搜索并返回结果 - • ❌ 差例子:
prepare_search()+execute_search()+get_results()– 需要三步配合
2. 鲁棒(对错误友好)
- • 能处理异常情况,不会崩溃
- • 给出明确的错误信息
- • ✅ 好例子:文件不存在时返回
{"error": "文件未找到", "path": "xxx"} - • ❌ 差例子:文件不存在时直接报错退出
3. 清晰(一看就懂)
- • 从工具名称和描述就能知道它做什么
- • ✅ 好例子:
get_user_profile(user_id)– 明确获取用户资料 - • ❌ 差例子:
process(id)– 不知道处理什么
4. 功能重叠最小
- • 每个工具做一件事,避免重复
- • ✅ 好例子:一个
search_user(query_type, value) - • ❌ 差例子:三个工具
search_by_name()、search_by_id()、search_by_email()
输入参数设计:
- • 描述性强:一看参数名就知道要传什么
- • 意义明确:不产生歧义
- • 发挥模型优势:让LLM用自然语言理解,而非复杂格式
常见失败模式
❌ 臃肿的工具集
- • 覆盖太多功能
- • 导致使用哪个工具的模糊决策点
关键原则:
如果人类工程师无法明确说明在给定情况下应使用哪个工具,不能期望AI智能体做得更好。
✅ 最小可行工具集
选择最小可行工具集的好处:
- • 更可靠的维护
- • 长交互中更好的上下文修剪
示例
提供示例(few-shot提示)是众所周知的最佳实践,强烈建议使用。
常见误区
❌ 塞满边缘情况
- • 在提示词中塞满一长串边缘情况
- • 试图覆盖LLM应遵循的每个可能规则
- • 结果:提示词冗长,模型反而抓不住重点
推荐做法
✅ 选择典型示例
建议选择一组:
- •多样化:覆盖不同场景
- •典型:非边缘情况,是常见情况
- •有代表性:有效描绘智能体的预期行为
💡对LLM来说,示例是值千言万语的“图片”。
总体指导原则
对上下文不同组成部分(系统提示词、工具、示例、消息历史等):
保持上下文信息丰富但紧凑
上下文检索和智能体搜索
智能体的简单定义
文章强调了基于LLM的工作流和智能体的区别。
简单定义:智能体 = LLM在循环中自主使用工具
与客户合作发现,领域正收敛到这个简单范式:
- • 随着底层模型变强 → 智能体自主水平扩展
- • 更智能的模型 → 独立导航问题空间并从错误中恢复
即时检索策略
背景:从“预检索”到“即时检索”
工程师在为智能体设计上下文时的思维转变:
传统方法:预推理时间检索
- • 采用基于embedding的检索
- • 推理前就浮现重要上下文
新趋势:“即时(Just in Time)”上下文策略
- • 运行时动态检索
- • 用到时才加载
工作方式
采用“即时”方法构建的智能体:
不会:
- • ❌ 预先处理所有相关数据
而是:
- • ✅ 维护轻量级标识符(文件路径、存储查询、网络链接等)
- • ✅ 运行时用工具动态将数据加载到上下文中
案例:Claude Code
Anthropic的智能体编码解决方案Claude Code使用这种方法对大型数据库执行复杂数据分析:
- 1. 模型编写针对性查询
- 2. 存储结果
- 3. 利用
head和tail等Bash命令分析大量数据 - 4. 无需将完整数据对象加载到上下文中
类比:像人类一样思考
这种方法反映人类认知:
人类不会:
- • ❌ 记忆整个信息语料库
人类会:
- • ✅ 引入文件系统、收件箱和书签等外部组织系统
- • ✅ 按需检索相关信息
元数据的价值:不打开文件也能获取信息
除了节省存储空间,元数据(文件路径、文件名、时间戳等)本身就能帮助智能体做决策。
什么是元数据?
元数据 = 关于数据的数据
类比:就像看书架上的书:
- • 不用打开书
- • 从书名、作者、出版日期就能判断要不要读
三种元数据类型
1. 文件路径暗示用途
智能体看到文件路径,就能判断文件用途:
示例1:
-
•
tests/test_utils.py- • 位置:
tests/文件夹 - • 推断:这是测试文件
- • 行为:如果要找核心逻辑,跳过
- • 位置:
示例2:
-
•
src/core_logic.py- • 位置:
src/文件夹 - • 推断:这是核心逻辑
- • 行为:如果要修改业务功能,优先看这里
- • 位置:
2. 文件名暗示内容
示例:
- •
config.json→ 配置文件 - •
utils.py→ 工具函数 - •
main.py→ 程序入口 - •
README.md→ 项目说明
3. 时间戳暗示相关性
示例:
- •
last_modified: 2天前→ 可能是最近修改的,相关性高 - •
last_modified: 2年前→ 可能是旧代码,相关性低
综合使用元数据
智能体通过元数据组合判断:
场景:修复最近的bug
- 1. 看时间戳 → 找最近修改的文件
- 2. 看路径 → 排除测试文件
- 3. 看文件名 → 优先看
bugfix.py而非config.json
效果:
- • 不用读所有文件内容
- • 快速定位相关文件
- • 节省上下文窗口
渐进式披露(Progressive Disclosure)
让智能体自主导航和检索数据也实现渐进式披露——允许智能体通过探索逐步发现相关上下文。
每次交互都提供线索
智能体通过探索获得信息:
- • 文件大小 → 暗示复杂性
- • 命名约定 → 暗示目的
- • 时间戳 → 暗示相关性
逐层组装理解
智能体的工作方式:
- 1. 仅在工作记忆中维护必要内容
- 2. 利用笔记策略进行额外持久化
- 3. 自我管理上下文窗口
效果:
- • ✅ 专注于相关子集
- • ❌ 而非淹没在详尽但可能无关的信息中
权衡与解决方案
权衡:速度 vs 精准
缺点:
- • ❌ 运行时探索比检索预计算数据慢
- • ❌ 需要工程确保LLM拥有正确工具和启发式
风险:没有适当指导,智能体可能:
- • 误用工具
- • 追逐死胡同
- • 未能识别关键信息
- • 浪费上下文
解决方案:混合策略
某些情况下,最有效的智能体可能采用混合策略:
- • 预先检索一些数据(提高速度)
- • 根据判断进行进一步自主探索(保持灵活)
“正确”自主水平的决策边界取决于任务。
案例:Claude Code的混合模型
Claude Code采用混合模型:
- •预检索部分:
CLAUDE.md文件被预先放入上下文 - •即时检索部分:
glob和grep等原语允许导航环境并即时检索文件
适用场景
混合策略更适合动态内容较少的上下文,例如:法律或金融工作。
未来趋势
随着模型能力提高:
- • 智能体设计将趋向让智能模型智能地行动
- • 人工选择逐渐减少
💡“做最简单有效的事情”可能仍将是对在Claude之上构建智能体的团队的最佳建议。
长期任务的上下文工程
问题:上下文窗口总会不够
长期任务的挑战:
- • Token计数超过LLM上下文窗口
- • 需要在长序列动作中维持连贯性
- • 例如:大型代码库迁移、综合研究项目(数十分钟到数小时)
为什么不能只等更大的上下文窗口?
看似显而易见的策略:等待更大上下文窗口。
现实:在可预见的未来,所有大小的上下文窗口都会受影响:
- • 上下文污染
- • 信息相关性问题
- • 至少在需要最强智能体性能时如此
三种解决方案
为使智能体在扩展时间范围内有效工作,Anthropic开发了三种技术:
- 1.压缩(Compaction)
- 2.结构化笔记(Structured Note-taking)
- 3.多智能体架构(Multi-Agent Architectures)
方案1:压缩(Compaction)
什么是压缩?
当对话接近上下文窗口限制时:
- 1. 总结内容
- 2. 用摘要重新启动新上下文窗口
核心目标:
- • 高保真方式提炼上下文窗口内容
- • 智能体以最小性能下降继续
案例:Claude Code如何压缩
Claude Code的做法:
- 1.总结:将消息历史传递给模型
- 2.保留:
-
• ✅ 架构决策
-
• ✅ 未解决的bug
-
• ✅ 实现细节
-
3.丢弃:
-
• ❌ 冗余工具输出
-
• ❌ 重复消息
-
4.继续:用压缩上下文 + 最近访问的5个文件
- • 确保压缩提示词捕获轨迹中每个相关信息片段
- • 迭代消除多余内容
- • 工具在消息历史深处被调用过
- • 智能体无需再次看到原始结果
- • 已作为Claude开发者平台功能推出
- 1. 智能体定期将笔记写入上下文窗口外的持久化内存
- 2. 稍后拉回上下文窗口
- • Claude Code:创建待办事项列表
- • 自定义智能体:维护
NOTES.md文件 - • 跟踪复杂任务进度
- • 维护关键上下文和依赖关系
- • 避免在数十次工具调用中丢失信息
- 1.维护精确统计(数千游戏步骤)
-
• “在过去1,234步中,一直在1号道路训练宝可梦”
-
• “皮卡丘已获得8级,目标是10级”
-
2.自主开发工具(无需提示)
-
• 开发探索区域的地图
-
• 记住已解锁的关键成就
-
• 维护战斗策略的战略笔记
-
• 学习哪些攻击对不同对手效果最好
-
3.跨上下文重置保持连贯
-
• 读取自己笔记
-
• 继续多小时训练序列或地牢探索
- • 基于文件的系统
- • 在上下文窗口外存储和查阅信息
- • 随时间构建知识库
- • 跨会话维护项目状态
- • 引用以前工作无需将所有内容保留在上下文中
- • ❌ 一个智能体试图在整个项目中维护状态
- • ✅ 专门化的子智能体用干净上下文窗口处理聚焦任务
- • 用高层计划协调
- • 执行深度技术工作
- • 使用工具查找相关信息
- • 可能广泛探索(数万个token或更多)
- • 只返回浓缩、精炼摘要(通常1,000-2,000个token)
- • 详细搜索上下文 → 保持在子智能体内隔离
- • 主智能体 → 专注于合成和分析结果
- • 制作完美提示词
- • 在每一步选择什么信息进入模型的有限注意力预算
- • 为长期任务实施压缩
- • 设计token高效工具
- • 使智能体即时探索环境
- • 更智能的模型需要更少规定性工程
- • 允许智能体以更大自主性运行
用户体验:获得连续性,无需担心上下文窗口限制。
压缩的艺术:平衡取舍
核心挑战:选择保留什么和丢弃什么。
风险:过于激进的压缩 → 丢失微妙但关键的上下文 → 后续才发现重要性。
优化建议
对实施压缩系统的工程师:
步骤1:最大化召回率
步骤2:提高精度
快速见效:清除工具结果
低垂果实示例:清除工具调用和结果
最安全的压缩形式:工具结果清除。
方案2:结构化笔记(Structured Note-taking)
什么是结构化笔记?
也叫:智能体记忆。
机制:
好处
以最小开销提供持久记忆。
例子:
效果:
案例:Claude玩宝可梦
展示:记忆如何在非编码领域转变智能体能力。
智能体的记忆能力:
关键价值:这种跨总结步骤的连贯性实现长期策略,仅靠LLM上下文窗口无法实现。
官方工具:记忆功能
作为Sonnet 4.5发布的一部分,Claude开发者平台推出:
记忆工具(公开beta)
允许智能体:
方案3:子智能体架构(Multi-agent Architectures)
核心思想
不是:
而是:
工作方式
主智能体:
子智能体:
核心优势
清晰的关注点分离:
实际效果
这种模式在《Anthropic如何构建多智能体研究系统》中讨论过:
在复杂研究任务上显示对单智能体系统的显著改进。
如何选择方案?
这些方法间的选择取决于任务特征:
| 方案 | 适合场景 | 典型例子 |
|---|---|---|
| 压缩 | 需要大量来回的任务 | 维护对话流 |
| 笔记 | 有明确里程碑的迭代开发 | 长期项目跟踪 |
| 多智能体架构 | 复杂研究和分析 | 并行探索带来红利 |
核心洞察:
即使模型继续改进,在扩展交互中维持连贯性的挑战仍将是构建更有效智能体的核心。
结论
从提示词工程到上下文工程
上下文工程代表我们如何使用LLM构建的根本转变。
过去:
现在:
不变的指导原则
无论:
指导原则不变:
💡找到最大化期望结果可能性的最小高信号token集合。
未来趋势
技术演化:本文概述的技术将随模型改进继续演化。
模型能力提升:
核心不变:即使能力扩展,将上下文视为有限资源仍将是构建可靠、有效智能体的核心。





