

LangChain团队在两个月前提出了“深度智能体”(Deep Agents)的概念,旨在描述那些能够执行复杂、开放式任务并长期运行的AI智能体。此类智能体通常需要规划工具、文件系统访问、子智能体以及详细的提示词这四个关键要素。
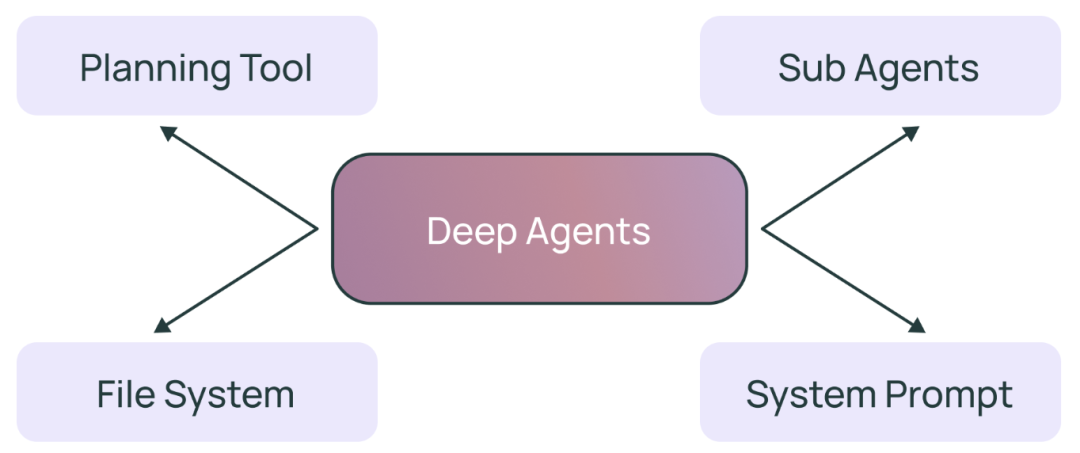
随后,LangChain团队推出了deepagents Python包,其内置了上述所有基础组件。开发者只需提供自定义工具和提示词,便能轻松构建深度智能体。该项目一经推出即获得了广泛关注和应用。
如今,LangChain团队发布了deepagents 0.2版本,进一步加大了对该项目的投入。本文将探讨此次更新带来的新功能,并阐明在何种场景下应优先选择deepagents而非langchain或langgraph。
可插拔后端:灵活的文件系统管理
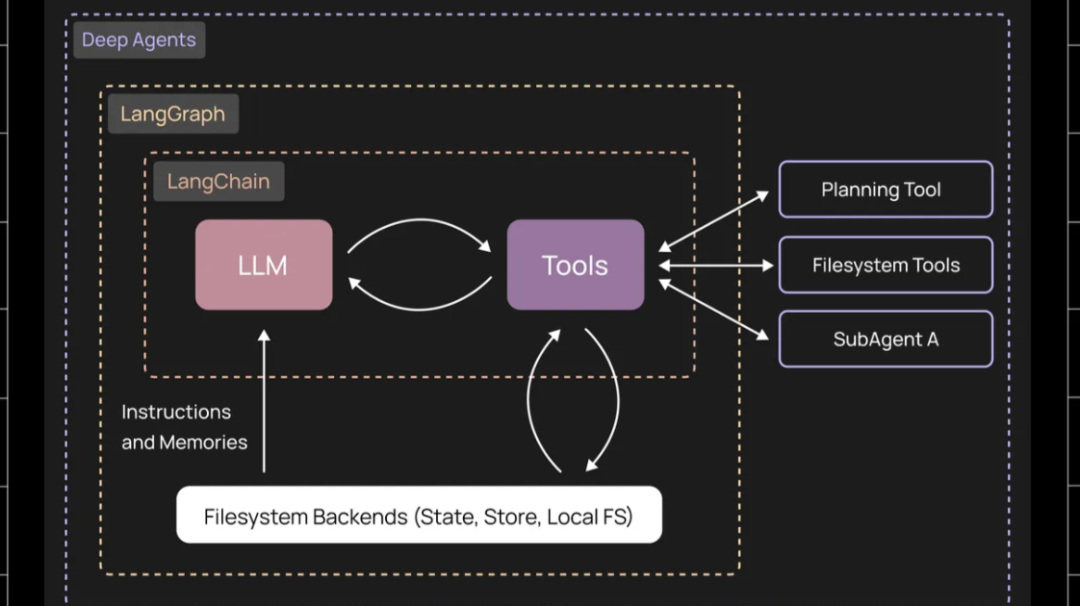
deepagents 0.2版本最重要的新功能是引入了可插拔后端(Pluggable Backends)。在此之前,deepagents所使用的“文件系统”实际上是利用LangGraph状态存储的“虚拟文件系统”。
现在,全新的Backend抽象层允许将任何存储系统作为“文件系统”使用。内置的实现包括:
- LangGraph State – 原有的状态存储方式
- LangGraph Store – 支持跨线程持久化
- 本地文件系统 – 直接使用真实的文件系统
更值得关注的是,deepagents还引入了“组合后端”(composite backend)的概念。开发者可以设置一个基础后端(例如本地文件系统),然后在特定的子目录上映射其他后端。此功能的一个典型应用场景是长期记忆存储。
例如:可以利用本地文件系统作为基础后端,同时将所有文件操作映射到/memories/目录,使其使用S3支持的“虚拟文件系统”。如此一来,智能体便可将重要信息存储于此,即使设备关闭,这些记忆也能永久保存。
开发者甚至可以基于任何数据库或数据存储创建自定义后端,打造专属的“虚拟文件系统”。如有需要,还可以继承现有后端,并添加文件写入权限控制、格式检查等安全护栏功能。
deepagents 0.2版本的其他优化
除了可插拔后端,deepagents 0.2版本还引入了以下几项实用优化:
- 大工具结果自动清理 – 当工具返回结果超出特定token限制时,系统会自动将其转储到文件系统中,从而避免内存占用过大。
- 对话历史自动摘要 – 当token使用量过高时,系统会自动压缩旧的对话历史,以维持上下文管理的效率。
- 悬空工具调用修复 – 当工具调用在执行前被中断或取消时,系统会自动修复消息历史记录,从而避免状态不一致问题。
deepagents、LangChain与LangGraph:应用场景辨析
目前,LangChain生态系统已包含三个开源库,每个库均服务于不同的目标。
为更清晰地区分这三者,LangChain团队提出了以下定位:
- deepagents被定位为“智能体框架”(agent harness)
- langchain是“智能体工具包”(agent framework)
- langgraph则为“智能体运行时”(agent runtime)。
这三个库是相互依存并逐层构建的:deepagents基于langchain的智能体抽象层构建,而langchain又构建在langgraph的智能体运行时之上。
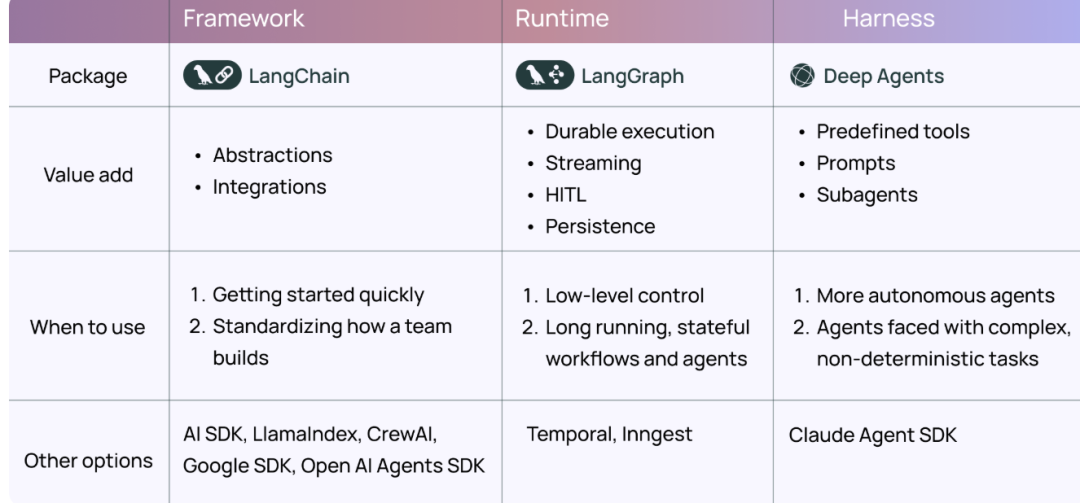
具体而言:
- LangGraph适用于需要构建工作流和智能体组合应用的场景。对于需要灵活控制流程和状态管理的开发者,LangGraph是理想选择。
- LangChain适用于希望使用核心智能体循环,但不需要任何内置功能,并希望从头开始构建所有提示词和工具的开发者。它提供了最大的控制权和灵活性。
- DeepAgents最适合构建更自主、长期运行的智能体,尤其是在需要利用其内置规划工具、文件系统等高级功能时。它能够处理许多底层复杂性,使开发者能更专注于智能体的核心逻辑。
随着AI智能体应用的日益复杂,这种分层架构设计理念正有效地帮助开发者根据具体需求选择最合适的工具。
deepagents 0.2版本的发布,特别是可插拔后端的引入,显著增强了deepagents在长期记忆和状态持久化方面的能力与灵活性。对于正在探索AI智能体开发的开发者而言,这无疑是一项值得密切关注的更新。





