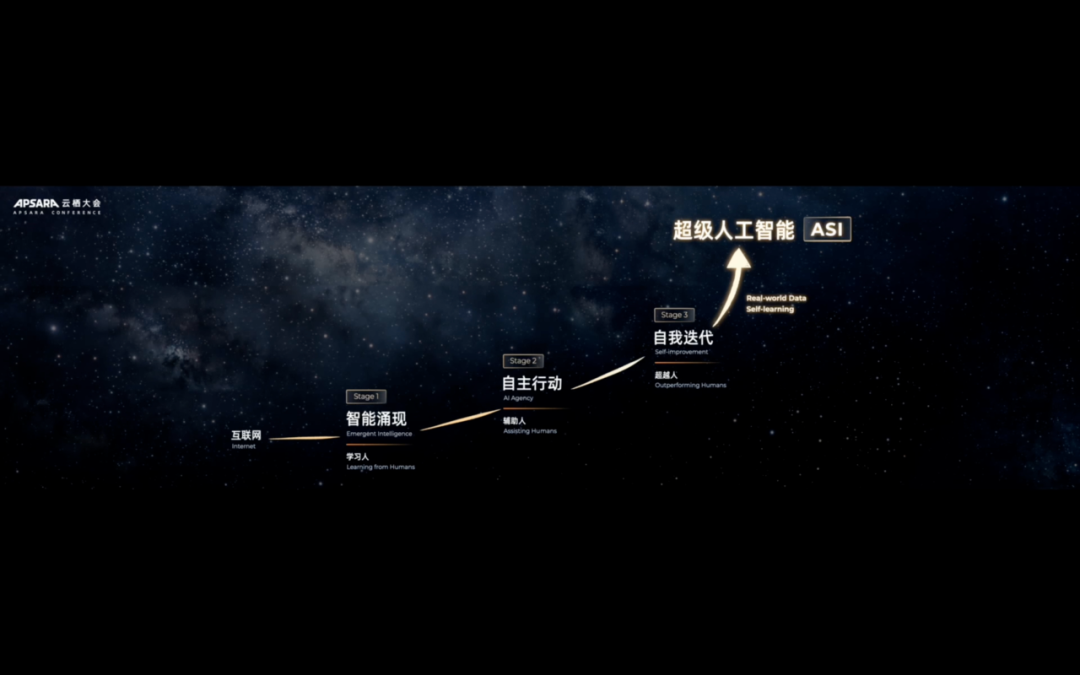
在传统的视觉模型中,图像理解与生成、编辑功能往往分离,例如在Qwen模型中,用户可能需要切换不同的模型来完成多项任务,显得较为繁琐。现在,蚂蚁金服开源的Ming-UniVision模型提供了一体化解决方案,将所有功能整合到一个模型中。这款Ming-UniVision-16B-A3B模型,拥有16B参数规模和3B激活,预计将提供快速的运行体验。
Ming-UniVision模型首次在连续统一表示空间中实现了图像理解与生成的原生融合,并同步开源了配套的统一连续视觉标记器MingTok。这意味着该模型不仅支持看图说话、文生图、图修图等基础功能,还能进行更深入的图像推理。

图像生成示例

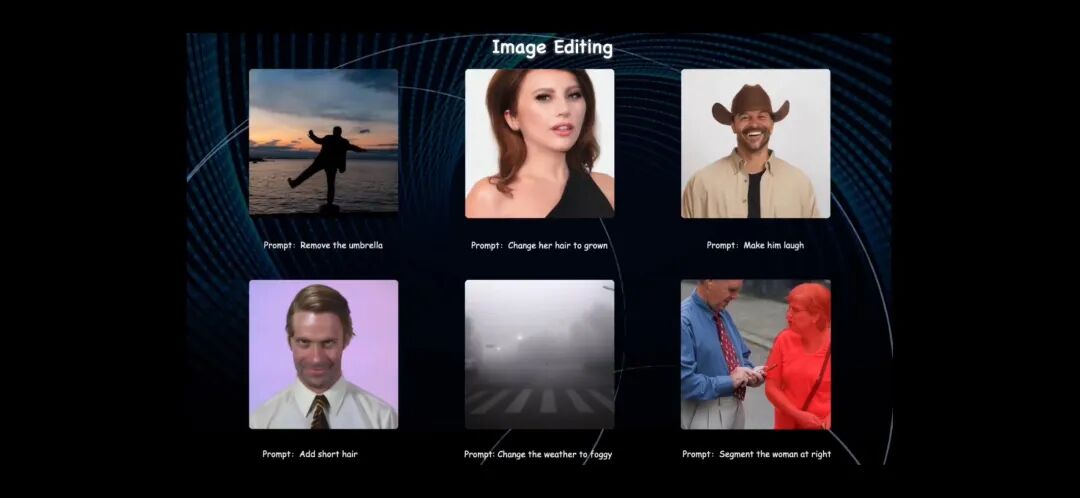
在可视化推理过程中,例如将人物变为笑脸,模型会首先推理并定位到需要编辑的嘴部区域,然后对相应部位进行编辑。

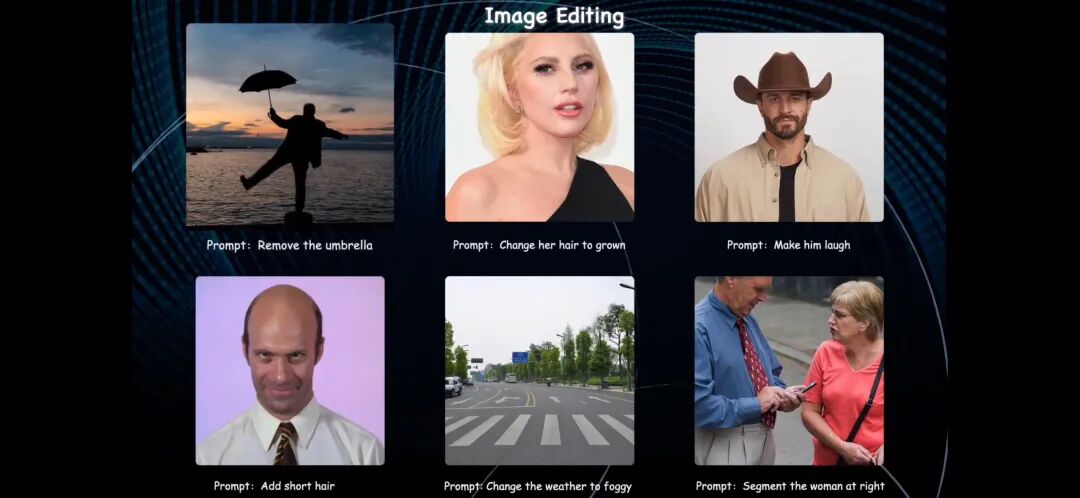
其图像编辑功能能够在保持图像整体一致性的同时,对特定部位进行精准编辑。
技术亮点
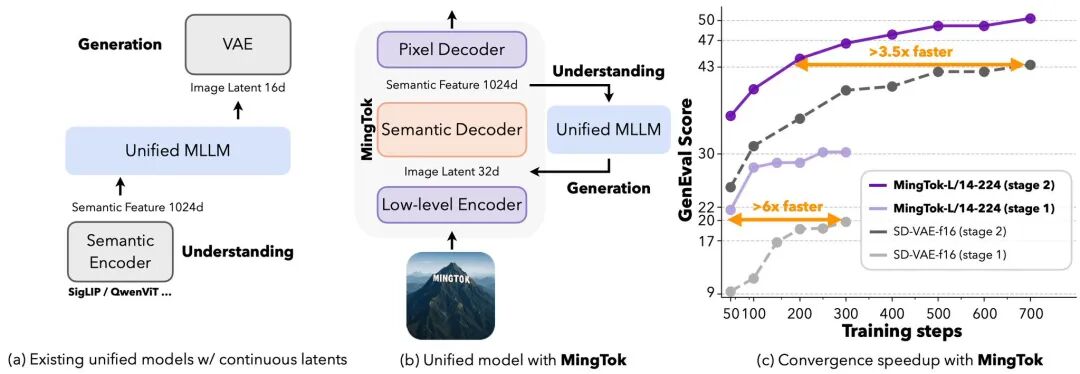
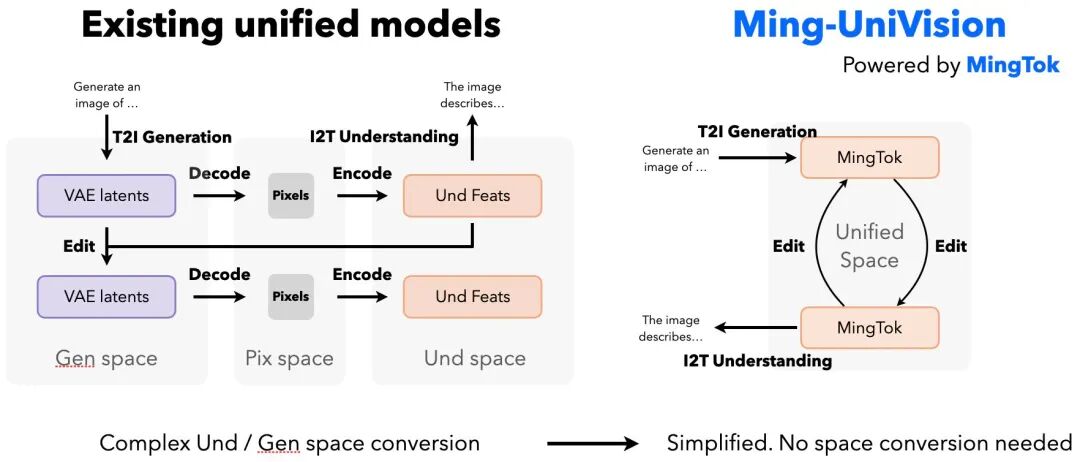
1. 统一空间:加速训练效率
Ming-UniVision通过减轻视觉与绘画之间的“表征竞争”,显著提升了文本到图像任务的收敛速度,实现了超过3.5倍的加速。这意味着在相同的性能下,模型所需计算资源更少。
2. 多轮互动:实现无缝视觉对话
传统的视觉模型在每次编辑时,常陷入耗时的“潜在空间→像素空间→特征空间”循环。而Ming-UniVision则实现了直接的“特征空间→特征空间”循环。这一突破带来了无缝且有状态的视觉对话体验,用户可以在高保真环境中进行生成、编辑、再生成的连贯操作。
开源信息
欢迎开发者探索代码,尝试模型,并积极参与社区共建!
GitHub:
https://github.com/inclusionAI/Ming-UniVision
HuggingFace:
- MingTok Tokenizer:
https://huggingface.co/inclusionAI/MingTok
- VisionMing-UniVision:
https://huggingface.co/inclusionAI/Ming-UniVision-16B-A3B