Embedding 模型在信息检索、文本处理、检索增强生成(RAG)中具有重要应用。然而,当前主流的Embedding模型,如NV-Embed、Qwen3-Embedding,其训练往往需要上亿量级的数据进行对比学习加训,或依赖于昂贵且未开源的合成数据,这导致小型研究团队在复现及改进Embedding模型训练算法时面临巨大挑战。
F2LLM(Foundation to Feature Large Language Models)系列模型现已发布,包含0.6B、1.7B、4B等多种规模。该系列模型仅利用六百万数据对基座模型进行微调,便在MTEB榜单上取得了业界领先的表现,并实现了完全开源。
简介

F2LLM项目是蚂蚁集团与上海交通大学校企合作的成果,其模型、数据及训练代码已全面开源:
-
arXiv:https://arxiv.org/abs/2510.02294
-
GitHub:https://github.com/codefuse-ai/CodeFuse-Embeddings
-
HuggingFace:https://huggingface.co/collections/codefuse-ai/codefuse-embeddings-68d4b32da791bbba993f8d14
相较于其他业界领先的Embedding模型,F2LLM不仅实现了完全开源,而且仅通过六百万高质量的非合成数据进行训练,在模型规模、训练成本和Embedding性能之间实现了最佳平衡,是未来Embedding研究的理想基线选择:

数据
F2LLM的训练数据来源于60个开源数据集,这些数据被统一整理为三种标准化格式:检索(retrieval)、分类(classification)和聚类(clustering)。
在开源数据集中,每条检索类和聚类数据均包含一个查询(query)、一个段落(passage)及24个难负样本(hard negative)。分类数据则包含一个查询、一个段落和一个难负样本。
检索数据

检索数据包含开源的检索、摘要、自然语言推理(NLI)、语义相似度(STS)和复述(paraphrase)数据集。
-
对于摘要数据,每条数据的摘要被用作查询,对应原文作为段落;
-
对于NLI数据,前提(premis)被用作查询,蕴含的假设(entailed hypothesis)作为段落,而中立或矛盾的推理(neutral/contradictory hypothesis)则作为难负样本;
-
对于STS数据,相似度大于4分的文本对被分别构建为查询-段落和段落-查询,从而形成两对样本;
-
对于复述数据,研究人员从互为复述的文本对中构建查询-段落样本;
针对上述所有检索数据,研究团队利用Qwen3-Embedding-0.6B从各数据集中额外挖掘难负样本,并对整个过程进行严格把控,以确保数据质量:
-
首先计算查询与段落的相关性分数;
-
从源数据集中召回100条与查询最相关的段落作为候选负样本,但除去最相关的五条以避免假阴性的负样本;
-
除去相关性大于0.8的候选负样本;
-
除去相关性大于正样本相关性95%的候选负样本;
-
从剩余候选负样本中选择相关性最高的24条作为难负样本,若剩余候选负样本不足24条则删除该数据。
分类数据

分类数据仅包含5个开源二分类数据集。其中,每条数据的输入被用作查询,对应类的文本标签作为段落,而另一类的文本标签则作为负样本。
聚类数据

聚类数据涵盖开源的聚类数据及多分类数据。对于每条输入,系统会从同一类别中随机采样一条作为段落,并从所有其他类别中集中采样24条作为负样本。
训练
模型训练采用标准的对比学习损失,直接对Qwen3基座模型进行微调。损失函数由所有数据的难负样本对比损失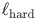 和检索类数据的批内对比损失
和检索类数据的批内对比损失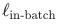 共同构成:
共同构成:
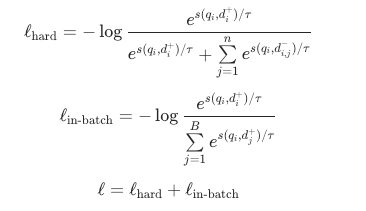
其中,代表温度参数,在训练过程中被设置为0.05;
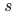 为相似度指标,采用余弦相似度计算。
为相似度指标,采用余弦相似度计算。
在训练阶段,所有数据集被混合在一起进行训练。然而,通过特殊设计的数据加载器,确保在每一步优化中,每个训练进程的数据均来源于单一数据集。对于检索类数据,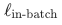 利用所有进程中样本的段落字段进行计算,从而提升样本学习效率;而对于分类和聚类数据,仅计算
利用所有进程中样本的段落字段进行计算,从而提升样本学习效率;而对于分类和聚类数据,仅计算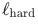 ,不涉及
,不涉及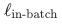 的计算。
的计算。
测评
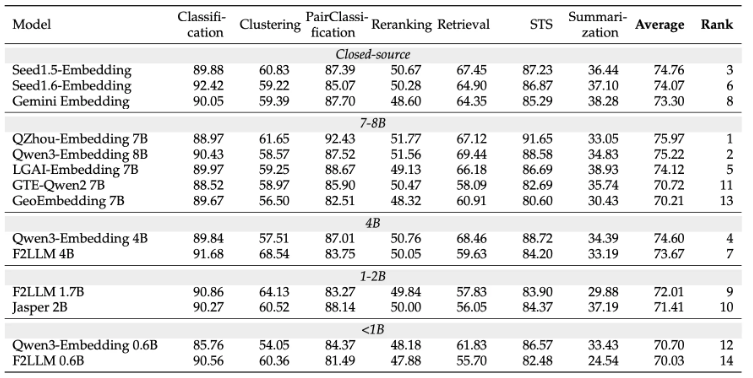
在MTEB英语榜单中,F2LLM-4B模型总体排名第7位,在4B规模的模型中,其性能仅次于使用亿级数据训练的Qwen3-Embedding 4B。值得一提的是,F2LLM-1.7B在1-2B模型中位列第一,使其成为算力受限应用场景下的优选方案。在榜单涵盖的七大类任务中,F2LLM系列在聚类任务上的表现尤为突出,其中4B模型的性能达到68.54,创下了所有模型中的新高。
关于团队
本研究团队隶属于蚂蚁集团智能平台工程的全模态代码算法团队。该团队成立三年来,已在ACL、ICLR、NeurIPS、KDD等顶级会议发表20余篇论文,并两次获得蚂蚁技术最高奖T-Star,一次蚂蚁集团最高奖SuperMA。团队长期招聘研究型实习生,欢迎对NLP、大模型、多模态、图神经网络领域感兴趣的同学发送简历至hyu.hugo@antgroup.com。
如需获取最新信息,欢迎加入团队的微信社群。

企业用户如有业务需求,可在加入群聊后私聊“CodeFuse服务助手”,与解决方案专家取得联系。