

AI Infra的演进与挑战:从OpenAI生产事故到未来展望
本文基于早期文稿整理而成,探讨AI Infra的演进与挑战,其深刻洞察力至今仍具参考价值。
OpenAI生产事故回顾
2024 年 11 月,ChatGPT 突发故障,导致服务中断近半小时,超过 19,000 人受到影响。
仅仅一个月后,2024年12月19日又发生了全球性服务中断事件。
这次中断与OpenAI使用的Kubernetes (k8s)集群有关。
作为一个拥有约7000个节点的超大规模集群,它在面对突发流量时出现了不稳定。
这暴露出了在构建和管理如此庞大的AI基础设施时所面临的挑战。
OpenAI 在事后报告中写道:
“监控服务覆盖的范围非常广泛,因此这项新服务的配置无意间导致……资源密集的 Kubernetes API 操作。
我们的 Kubernetes API 服务器不堪重负,导致我们的大多数规模 Kubernets 集群中的控制平面陷入瘫痪。”
OpenAI 提到,在客户感受到影响的“几分钟”内,公司就检测到了该问题;
但由于必须绕过不堪重负的 Kubernetes 服务器,因此无法快速实施修复。
于是,一个惨痛的生产事故就此发生。
再来说一个SRE技术岗位工程师都知道的基本事实。
一个k8s集群的总节点数最大上限建议为5000个。
为什么是这个数字?
k8s控制面底层依赖etcd存储元数据,etcd本身底层基于Raft算法来保证分布式数据的一致性。
Kubernetes官方文档指出,单个集群支持的最大节点数为5000,
这是谷歌基于对大规模集群性能的测试和经验得出的。K8S作为谷歌开源项目,5000这个数字并非随意给出。
如果大于5000节点(中小厂会限制在100个左右),一般会使用多集群方案。然而,k8s多集群之间的通讯、存储、计算一致性又是一个难题。为了将购买的性能强劲的GPU算力压榨到极致,AI大厂往往不愿拆分多个k8s集群。
当然,也可以突破限制让k8s支撑5000节点以上,但这需要投入更多精力在集群稳定性、监控、数据流传递等方面,这也是OpenAI这次事故发生的必然性。后续一定还会发生更多类似的事故。
AI Infra包括之前的Cloud Infra在大多数时候都默默无闻,就像一个低头拉磨的老黄牛,一般不太会有存在感。
但凡出了事就是大事儿,比如前几年的某宝网络电缆被挖断,某云的OSS权限认证失败导致存储访问被拒绝等等。这些基础设施是基石,它十分考验搭建技巧,一块摆的不对,整个大厦瞬间宕机。
Kubernetes(k8s): AI Infra的基石
在OpenAI事故中,Kubernetes(k8s)作为核心基础设施组件备受关注。
那么,k8s在AI基础设施中究竟扮演着什么角色?它的关键组件有哪些?
Kubernetes是一个开源的容器编排平台,它为大规模分布式系统提供了强大的管理和调度能力。
在AI领域,k8s的作用更加凸显。
它不仅可以管理运行AI模型的容器,还能协调GPU等硬件资源的分配,实现负载均衡和自动扩缩容。
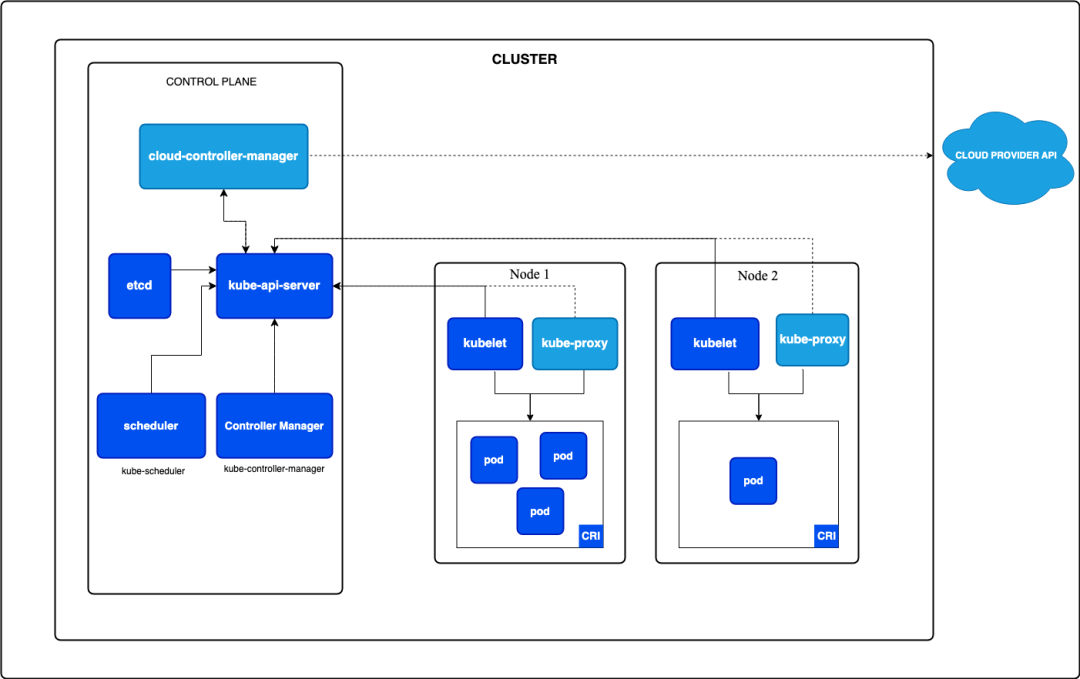
k8s的架构主要分为控制平面(Control Plane)和数据平面(Data Plane)。
控制平面负责整个集群的管理和决策,包括API Server、Scheduler、Controller Manager等组件。
数据平面则由众多Worker节点组成,负责实际运行工作负载。
在控制平面中,API Server是整个系统的入口,负责接收和处理各种请求。
Scheduler负责将新创建的Pod分配到合适的节点上。
Controller Manager则包含多个控制器,负责维护集群的期望状态。
数据平面的核心是kubelet,它运行在每个Worker节点上,负责管理该节点上的容器。
kube-proxy则负责维护网络规则,实现服务的负载均衡。
在AI工作负载中,k8s还需要与GPU管理插件(如NVIDIA的GPU Operator)协同工作,以实现GPU资源的高效调度和利用。
正如OpenAI的事故所示,当集群规模达到数千个节点时,k8s的管理难度也大大增加。
控制平面的性能、网络通信的效率、存储系统的吞吐量等都将面临巨大挑战。
因此,在构建超大规模AI集群时,需要AI Infra专家对k8s进行深度优化和定制。
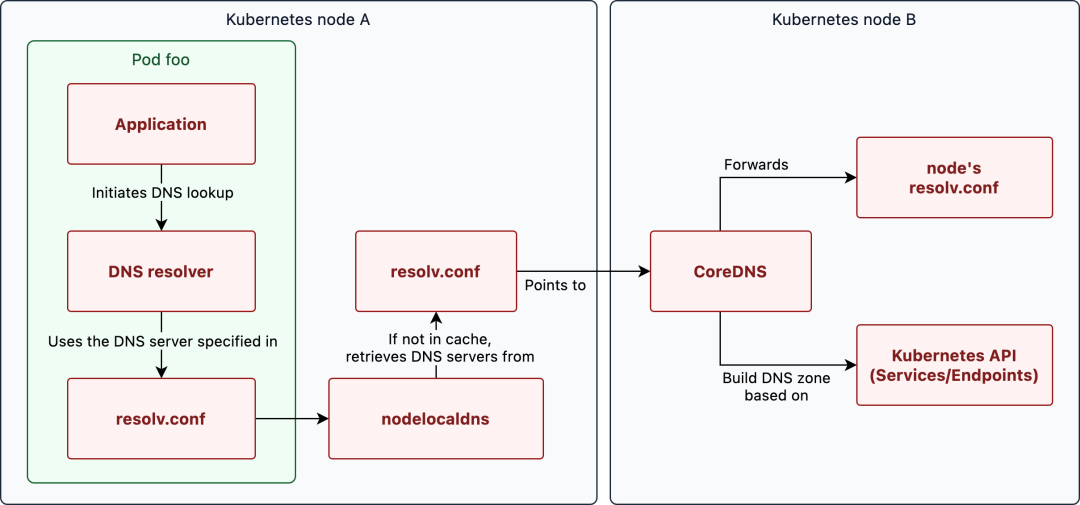
超大规模AI集群:挑战与准备
构建一个拥有7000个节点的超大规模AI集群,这绝非易事。
它需要在硬件、软件、网络、存储等多个层面做好充分准备,并具备应对各种挑战的能力。
硬件方面需要搭建大量高性能的GPU服务器。
考虑到AI模型的计算密集特性,每个节点可能配备多块NVIDIA A100或H100 GPU。同时,高速网络互联(如InfiniBand或100GbE+)也是必不可少的,以支持节点间的高效通信。
专门的GPU管理和调度系统是必需的。
例如,NVIDIA的NCCL(NVIDIA Collective Communications Library)可以大幅提升多GPU、多节点训练的效率。同时,分布式训练框架(如Horovod)的选择和优化也至关重要。
网络架构
在如此大规模的集群中,网络拓扑的选择(如Spine-Leaf架构)直接影响着整体性能。此外,智能的流量管理和负载均衡策略也不可或缺。
存储系统
面对海量的训练数据和模型参数,传统存储方案可能力不从心。这就需要引入高性能分布式存储系统,如Ceph或Lustre,并针对AI工作负载进行优化。国内常用的云原生存储方案是JuiceFS,基本上类似的解决方案勉强可以满足当前AI形态的业务需要。
AI Infra的运营运维
管理和运维如此庞大的集群也是一项艰巨任务。自动化运维、故障检测与恢复、资源利用优化等都需要先进的工具和经验丰富的团队支持。
能源消耗和散热
大规模GPU集群的功耗巨大,需要先进的电力供应和冷却系统。
一些公司甚至选择将数据中心建在寒冷地区或水源丰富的地方,以降低冷却成本。
例如,Azure尝试将数据中心建在海底。
“我们在水中的故障率是我们在陆地上的八分之一,”
Ben Cutler 领导了微软所谓的 Project Natick。该团队推测,更高的可靠性可能与数据中心没有人类干扰,以及没有氧气被泵入有关。
测试结束后,白色的圆柱体从寒冷的水域中出现,上面覆着一层藻类、藤壶和海葵。
但在内部,数据中心运作良好。
因此,拥有多少H200、H300等硬件并非关键,
关键在于有多少AI Infra专家能够确保基础设施支撑算力线性扩展。
在Scaling-law失效之前,AI Infra的能力正是大模型这个木桶上的一块短板。
Grok的超级AI中心:更大的挑战
谈及超大规模AI基础设施,不得不提到Elon Musk雄心勃勃的计划——Grok的超级AI中心。
这个项目旨在打造一个前所未有的AI计算设施,其规模和复杂度可能远超OpenAI的集群。
Grok的超级AI中心在AI基础设施方面会面临哪些新的挑战呢?
规模带来的挑战将更加严峻。
如果说OpenAI的7000节点集群已经令人望而生畏,那么Grok的超级AI中心可能会将这个数字推向新的高度。这意味着需要重新思考集群管理的方式。传统的中心化管理模式可能难以应对,可能需要引入更加分布式和自治的管理架构。
异构计算将成为一大挑战。
Grok可能会采用多种类型的计算单元,包括传统GPU、专用AI芯片,甚至量子计算单元。如何在一个统一的平台上管理和调度这些异构资源,将是一个巨大的技术难题。
网络互联也将面临新的挑战。
随着规模的增长,传统的网络架构可能难以满足需求。可能需要探索新的网络拓扑和协议,甚至考虑光学互联或其他新兴技术,以实现更高的带宽和更低的延迟。
数据管理和存储同样是一个重要问题。
面对可能达到EB级的数据规模,如何实现高效的数据存取、移动和处理?分布式存储系统需要进一步优化,可能还需要引入新的数据管理范式,如近数据计算(Near-Data Processing)。
能源效率将是另一个关键挑战。
如此庞大的计算设施必然会消耗大量能源。如何提高能源利用效率,降低碳排放,将是Grok项目必须面对的问题。这可能涉及到新的冷却技术、可再生能源的使用,甚至是计算任务的智能调度以优化能耗。
AI系统的安全性和隐私保护
作为一个超大规模的AI系统,Grok将处理海量的敏感数据。如何在保证性能的同时,实现强大的安全防护和隐私保障,这是一个复杂而关键的问题。
计算机领域的发展规律与AI基础设施
在探讨AI基础设施的未来之前,回顾一下计算机领域的几个重要发展规律,以及它们对AI基础设施的影响。
摩尔定律
摩尔定律是由英特尔联合创始人戈登·摩尔在1965年提出的,它预测了集成电路上的晶体管数量大约每两年翻一番,这直接关联到计算能力的提升和成本的降低。
然而,随着技术的发展,特别是当芯片工艺进入10nm以下时,晶体管密度的增速放缓,摩尔定律的预测不再那么准确。物理极限、成本上升和高温漏电问题使得摩尔定律在传统硅材料技术上的应用受到了挑战。
尽管近年来有人质疑其是否仍然适用,但不可否认的是,计算能力的持续提升为AI的发展提供了坚实基础。
从早期的CPU到现在的GPU和专用AI芯片,硬件性能的飞跃直接推动了AI模型的规模和复杂度的增长。
Scaling-law定律
Scaling-law定律,也称为缩放定律,是人工智能和机器学习领域中描述模型性能如何随着模型规模(如参数数量)、训练数据量和计算资源增加而提升的一组经验法则。
这个定律表明,大模型的Loss与模型参数规模、训练数据规模之间存在幂律关系。
清华刘知远团队甚至提出了“密度定律”,强调模型能力密度随时间呈指数级增长,即大模型的能力密度大约每100天翻一倍。
云原生容器技术诞生于摩尔定律之后、Scaling-law定律之前。
通过容器化技术,可以更加高效地管理和调度计算资源。
而云原生的思想则使得AI系统能够更好地利用云计算的优势,实现弹性伸缩和故障恢复。
随着AI模型规模的不断增长和应用场景的日益复杂,现有的解决方案也面临着诸多挑战。
如何更好地利用GPU资源?
如何优化大规模分布式训练的效率?
如何处理日益增长的数据规模?
最关键的,如何保证AI Infra可以随着Scaling-law定律的曲线从基础设施层面保证AI算力的线性扩展?
AI基础设施的理想方案
大胆设想一下理想的AI基础设施方案。
首先,需要打破当前GPU、CUDA和Kubernetes GPU调度的限制。
虽然NVIDIA的GPU和CUDA生态系统极大地推动了AI的发展,但也在某种程度上限制了创新。
需要探索更开放、更灵活的GPU计算方案。例如,开放的GPU指令集架构可能会带来更多的创新机会。同时,也需要改进GPU的调度机制,使其能更好地适应AI工作负载的特点。
其次,为大模型提供更适合的网络方案。
当前的网络架构在面对大规模分布式训练时,往往会成为性能瓶颈。未来的AI网络可能需要更高的带宽、更低的延迟,甚至可能需要专门为AI工作负载优化的网络协议和拓扑结构。
在存储方面,需要更高效的解决方案来支持大模型的预训练和推理。
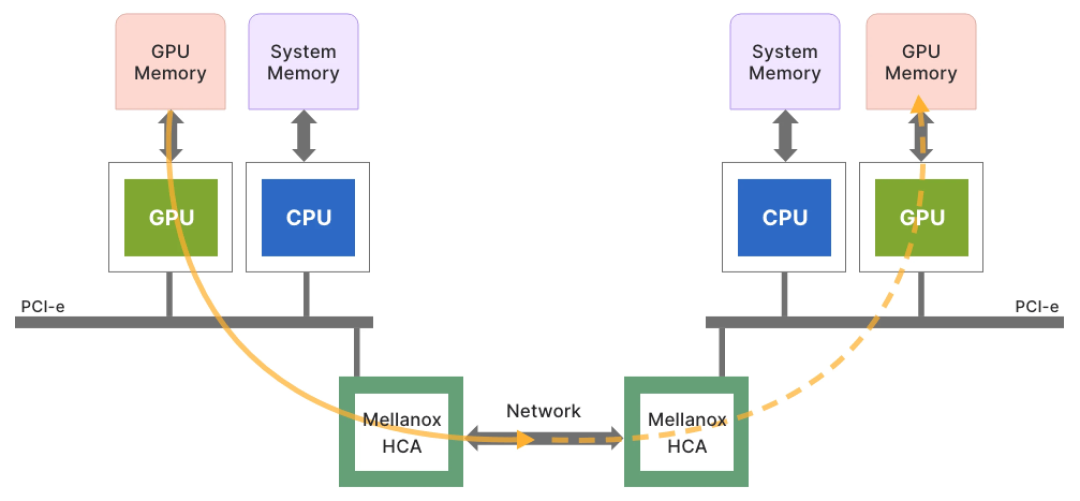
eRDMA(Enhanced Remote Direct Memory Access)技术在这方面显示出了巨大潜力。
它可以大幅降低数据移动的开销,提高内存访问效率。结合Kubernetes的CSI(Container Storage Interface)机制,可以实现更灵活、更高效的存储管理。
此外,还需考虑如何更好地支持异构计算。
随着专用AI芯片、FPGA等新型计算单元的出现,未来的AI基础设施需要能够无缝集成和管理这些异构资源。
这可能需要新的资源抽象和调度算法。
安全性和可解释性
随着AI系统变得越来越复杂和强大,如何确保其行为可控、结果可解释,将成为一个关键问题。这可能需要在基础设施层面引入新的机制和工具,超越目前k8s Metrics纯资源视角的监控标准。
突破Kubernetes的局限性?
K8s是AI Infra目前一个绕不开的问题:
是否可以突破Kubernetes的局限性?
毕竟,Kubernetes最初并非为AI工作负载设计。
然而,短期内完全抛弃Kubernetes似乎并不现实。
预计至少在未来5年内,Kubernetes很可能仍将是AI基础设施的核心组件。
这是因为Kubernetes已经在云原生生态系统中占据了主导地位,拥有庞大的用户群和丰富的工具链。
完全重新设计一个新的系统不仅成本高昂,而且风险巨大。
相反,可能会看到Kubernetes的持续演进和优化,以更好地适应AI工作负载的需求。
例如,可能会看到针对大规模GPU集群的专门调度器、更高效的网络插件,以及为AI工作负载优化的存储解决方案。同时,Kubernetes的插件机制也为引入新功能提供了灵活性。
尽管如此,仍然需要保持开放的心态,积极探索新的架构和范式。
随着AI模型和应用的不断发展,可能会遇到Kubernetes难以解决的问题。
在这种情况下,需要勇于创新,甚至重新思考分布式系统的设计原则。
可以预见,未来几年内,类似OpenAI事故的情况可能会越来越多。
这并不意味着Kubernetes或其他现有技术是失败的,而是表明正在不断挑战技术的极限。每一次事故都是一次学习的机会,推动AI基础设施的改进和优化。
事实上,AI基础设施的优化过程在某种程度上类似于云计算的发展历程。
早期的云计算同样面临着诸多挑战,如可靠性、性能、安全性等。
但通过持续的创新和改进,云计算最终成为了一个成熟而强大的技术生态系统。AI基础设施很可能会经历类似的发展轨迹。
AI Infra专家的角色与挑战
在AI基础设施快速发展的背景下,顶尖的AI基础设施专家正扮演着越来越重要的角色。
目前,这些专家主要集中在AWS、Google、阿里云等传统云计算巨头中。
这并不奇怪,因为这些公司拥有丰富的大规模分布式系统经验,以及强大的技术积累。
这意味着专门的AI公司在短期内可能会在AI基础设施能力上受到限制。
尽管他们在AI算法和应用方面可能领先,但在处理大规模基础设施的经验上可能不及传统云厂商。
这种情况可能会导致一些有趣的合作和竞争动态。
可能会看到更多的AI公司与云厂商建立深度合作关系,以弥补自身在基础设施方面的不足。
同时,一些大型AI公司可能会加大对基础设施人才的投资和培养,试图建立自己的核心竞争力。
对于那些有志于成为AI基础设施专家的人来说,这无疑是一个充满机遇的时代。
他们需要具备跨学科的知识和技能,包括分布式系统、高性能计算、网络架构、存储技术,
以及对AI算法和工作负载特性的深入理解。
同时,他们还需要具备系统思维和创新精神,能够在复杂的技术生态中找到平衡点,并不断推动技术的边界。




