

如何构建AI原生应用?从大模型到知识中台,从数据到规则逻辑。AI原生=模型原生+知识原生+价值原生
 本文将探讨AI原生应用的核心概念与构建方法,并借助AI大模型自身的阐释,深入解析如何打造真正意义上的AI原生系统。
本文将探讨AI原生应用的核心概念与构建方法,并借助AI大模型自身的阐释,深入解析如何打造真正意义上的AI原生系统。
AI原生是指从设计之初就将AI能力作为核心架构和功能基础来构建的系统或应用,而不是在传统系统上后期添加AI功能。
一个真正的AI原生系统通常具备以下特点:
- 架构层面
-
AI优先设计:架构围绕AI模型的训练、推理和持续学习来设计
-
数据驱动核心:数据流和AI模型是系统的中枢,而非辅助组件
-
动态适应性:系统能够根据AI模型的输出自动调整行为和决策
- 功能层面
-
智能是主要价值:核心功能依赖AI实现,去掉AI后价值大幅降低
-
持续学习能力:系统能够从用户交互和新数据中不断学习优化
-
个性化体验:基于AI为每个用户提供定制化的服务
- 用户体验层面
-
自然交互:支持对话式、语音、视觉等AI驱动的交互方式
-
预测性服务:主动预测用户需求而非被动响应
-
智能自动化:自动完成复杂任务,减少人工干预
类似ChatGPT、Claude、GitHub Copilot、Midjourney等可被理解为AI原生应用。然而,对于传统IT系统仅通过增加AI知识库、AI智能报表、AI智能排产或图像识别等功能,通常只能称之为AI赋能或AI集成,而非AI原生。
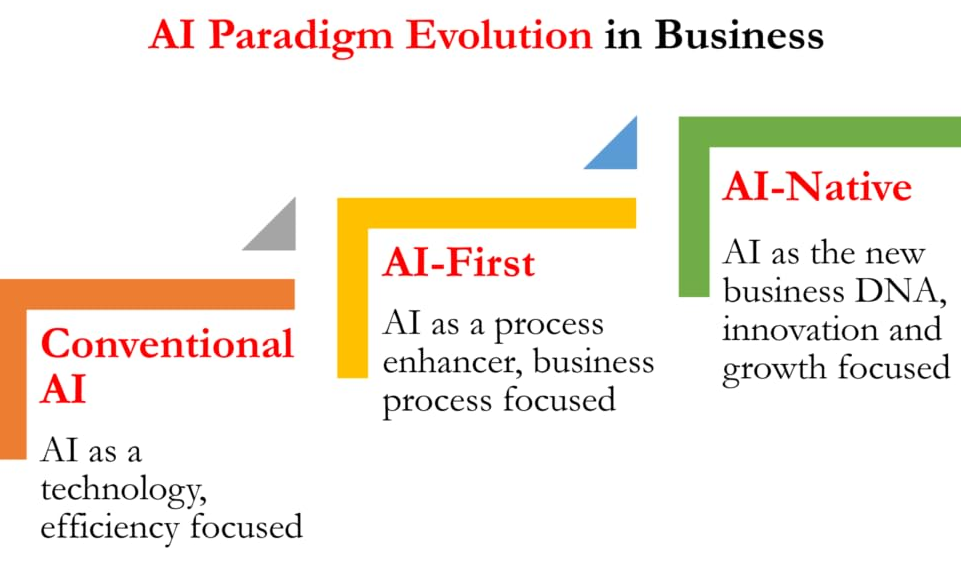
因此,从AI大模型自身给出的回答可见,其已基本阐明了AI原生的关键要点。AI原生系统必须是“土生土长”的,即其能力从系统构建之初就内置其中,而非后期简单嫁接或集成AI大模型能力。将传统IT系统改造后简单冠以“AI原生”之名,实属误解。
AI原生:大模型原生+知识原生+价值原生
一个系统能否称之为AI原生系统,其核心关键在于整个系统核心能力是否架构在底层的AI大模型和知识层之上。若满足此条件,则可称之为AI原生系统。
在探讨AI原生时,曾提及AI原生核心是知识原生。企业当前拥有数据库数据和资料文档,为何不能快速构建AI原生应用?其关键在于数据到智能的转化过程,中间需要构建知识层。
因此,针对此问题,可能会有疑问:基于AI大模型能力及现有数据开发的诸多AI Agent智能体应用,是否属于AI原生应用?
在此需进一步说明:
当前业界另有一种说法,认为AI原生应用就是基于AI大模型能力开发的应用,其特征在于区别于传统应用的核心。AI原生应用基于大模型开发,这些大模型具备强大的计算能力和丰富的训练数据,如GPT-4、百度文心一言等,它们构成应用的核心驱动力。大模型不仅是完成特定任务的工具,更是AI原生应用创新的基石。
然而,这种说法仅解决了AI原生应用的大模型原生问题,并未解决知识原生问题。若按此说法,所有AI智能体应用都将是AI原生应用。但普遍认为,AI原生应用的核心重点应在于知识原生。
可以审视或复盘所开发的AI智能体,会发现其中仍存在大量业务规则逻辑处理或相关业务流编排,这些内容并未内置到底层大模型中。
即便是底层有相关数据支持,但涉及业务处理规则逻辑及个人处理经验的内容,仍停留在上层,未融入底层大模型。因此,对于AI智能体应用,也难以被完全定义为AI原生应用。
知识本体论:从数据到信息,从信息到知识
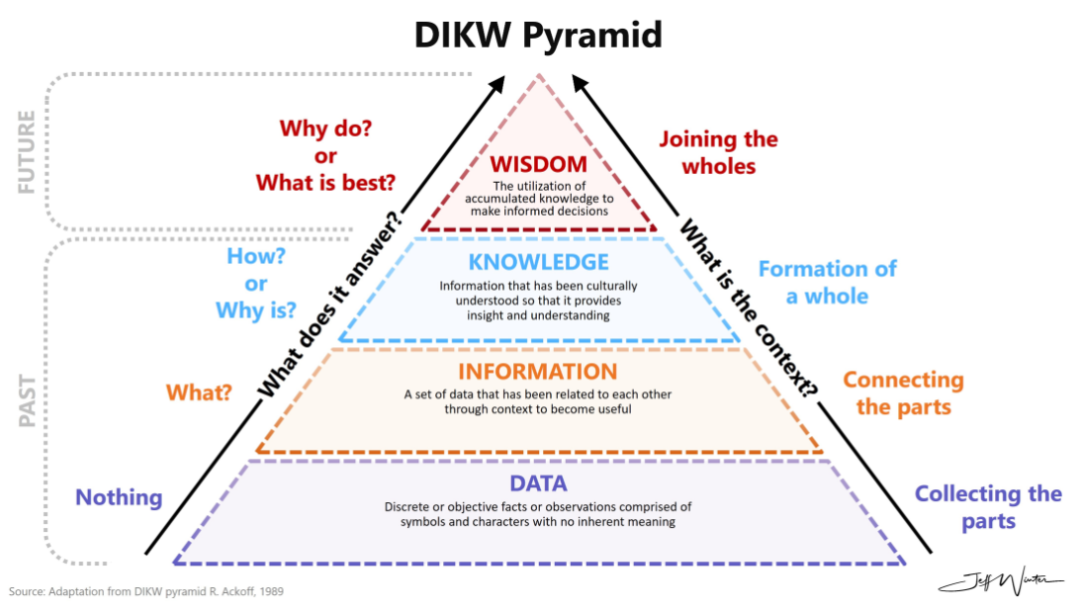
DIKW知识管理金字塔模型中,知识从下到上依次为数据-信息-知识-智慧。需要注意的是,数据不能直接产生智慧,知识才是产生智慧的基础。
经过加工、清晰且有用的数据可以转化为信息,而经过大量实践验证的信息最终才能转变为知识和经验。知识即是大量实践经验的高度显性化表达。
在知识管理领域,曾有例子指出,知识并非最终形成的文档结果,而是思考并形成文档的过程。这个过程才是核心的知识或经验,也是构建AI原生的关键基础能力。
那么,当前企业在数字化转型或构建AI原生时面临的实际情况是什么呢?首先是数据层面尚未理清,数据不标准、不一致、重复等问题严重,难以真正实现数据驱动;其次是应用数据或应用系统的经验未能浓缩为知识沉淀下来,或者说缺少知识这一重要分层。
因此,在之前曾提及Palantir这家公司。曾有观点认为,其仅仅是大模型赋能下的一个数据中台和提供数据服务的公司。但实际上,该公司的核心是基于Ontology本体系统构建了一个核心的知识中台。
Palantir 的核心架构是基于Ontology(业务本体),它不仅整合数据,更定义了企业中的“决策逻辑”。AI 模型被嵌入到这个本体中,成为可复用、可治理的“决策函数”,从而实现:
-
AI+规则混合决策:既可用 AI 预测需求,也可用业务规则设定库存阈值,系统会自动协调两者
-
实时反馈闭环:AI 的预测结果会写回 Ontology,成为下一次决策的输入,形成持续优化的闭环。
本体=对象+属性+关系
知识本体类似于常见的知识图谱,其重要性不仅在于实体本身,更在于实体间的关系。只有建立了关系,才能形成完整的推理能力。这类似于面向对象分析建模,除了对象和对象属性,更重要的是方法和行为。方法和行为构建了对象间的关系连接。在整个本体建模中,真正重要的是行为建模和关系建模。有了关系,才能形成相应大模型推理的逻辑基础。
以医疗供应链业务为例,在建模时可将相关数据映射到 Ontology 的三类元素:
-
对象(Objects):口罩生产线、供应商、仓库、客户订单、运输路线……
-
属性(Properties):每条产线的当前产能、每个仓库的库存量、订单的交付截止日期。
-
关系(Links):供应商 A为生产线 B提供熔喷布;订单 C由仓库 D履行。
传统IT系统构建方式的变革

此前文章曾探讨AI软件工程3.0,包括AI时代对软件构建方式的影响,如AI编程和VibeCoding。然而,这些内容更多是从技术层面讨论AI时代软件开发模式的变革。
基于前述本体论思想,AI原生时代更大的变革在于AI应用模型构建上的变化,以及数据和知识构建模式的变革。
回顾传统的IT系统构建模式,通常包括需求分析、架构设计、开发实现,最终部署为完整的IT系统。这类系统一般包含底层数据库和上层应用。即使到微服务架构阶段,上层应用也进一步实现了前后端分离。
知识=对象+属性+行为关系
然而,传统IT系统仍存在上层应用和底层数据库的两层划分。底层数据库、数据架构和数据模型沉淀了相关数据及数据间的关系,但这些数据难以称之为完整的知识。那么,对于IT系统而言,这些知识究竟何在?
这些知识实际上沉淀在上层应用中,具体体现在上层应用实现的代码里,包括数据如何处理和流转、相关业务规则如何处理等。这些内容都存在于代码中,并未沉淀到下层数据库里。
正如前面所述,尽管在面向对象分析建模时构建了完整的对象、属性和行为关系,但转到IT系统构建实现时,这两部分内容实际是分离的。对象和属性落地到数据库模型中,而行为和关系逻辑则体现在上层应用的代码里。
这意味着当前的传统IT系统,仅通过底层数据库和数据,无法构成完整意义上的知识。它缺乏数据形成的知识,以及数据之间的关系和行为逻辑,因为这些逻辑未进行模型化沉淀,而是存在于上层应用代码中。
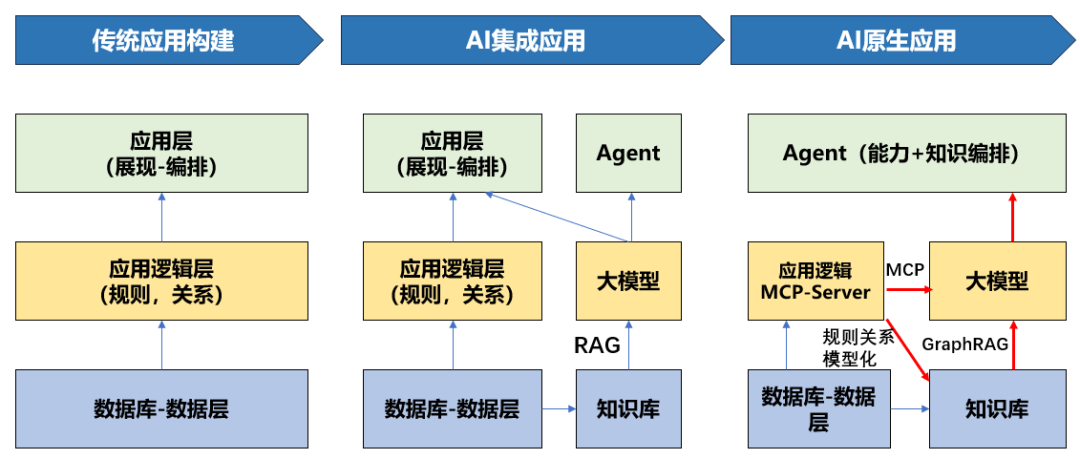
因此,要构建一个AI原生系统,包含两个相当重要的核心内容:第一,将原有数据库数据及信息,经过进一步加工和提炼,转移到核心知识库中;第二,将原本构建在上层应用中的相关处理规则和逻辑,进一步下沉为相关模型,沉淀到知识库里。只有这样,才能逐步形成一个关键的知识中台。
只有这样,才能形成完整意义上的知识层。有了知识这一内容,再加上AI大模型的能力,才能真正构建AI原生应用。
这正是文章一直强调的,我们距离真正的AI原生应用还有相当长的距离。有观点指出,至少在3-5年内都很难真正达到AI原生应用的理想状态。其中一个核心原因是,AI大模型天生擅长处理模糊信息,而非精确规则。即使前期对相关精确规则进行了定义,并将其通过提示语和上下文工程落地到大模型中,大模型在使用这些精确规则时仍可能出现“幻觉”现象,这个问题短期内难以克服。
最后,重新审视AI原生应用时,可从以下三个问题入手,或许能得出该应用是否AI原生的正确答案:
-
去掉AI后,这个系统还能实现其核心价值吗?
-
AI是后期添加的功能,还是从第一天就是系统基础?
-
系统的竞争力主要来自AI能力,还是传统软件工程?
AI原生代表了软件开发的新范式,它改变了思考和构建应用的方式,使智能成为软件的基因而非附加功能。





