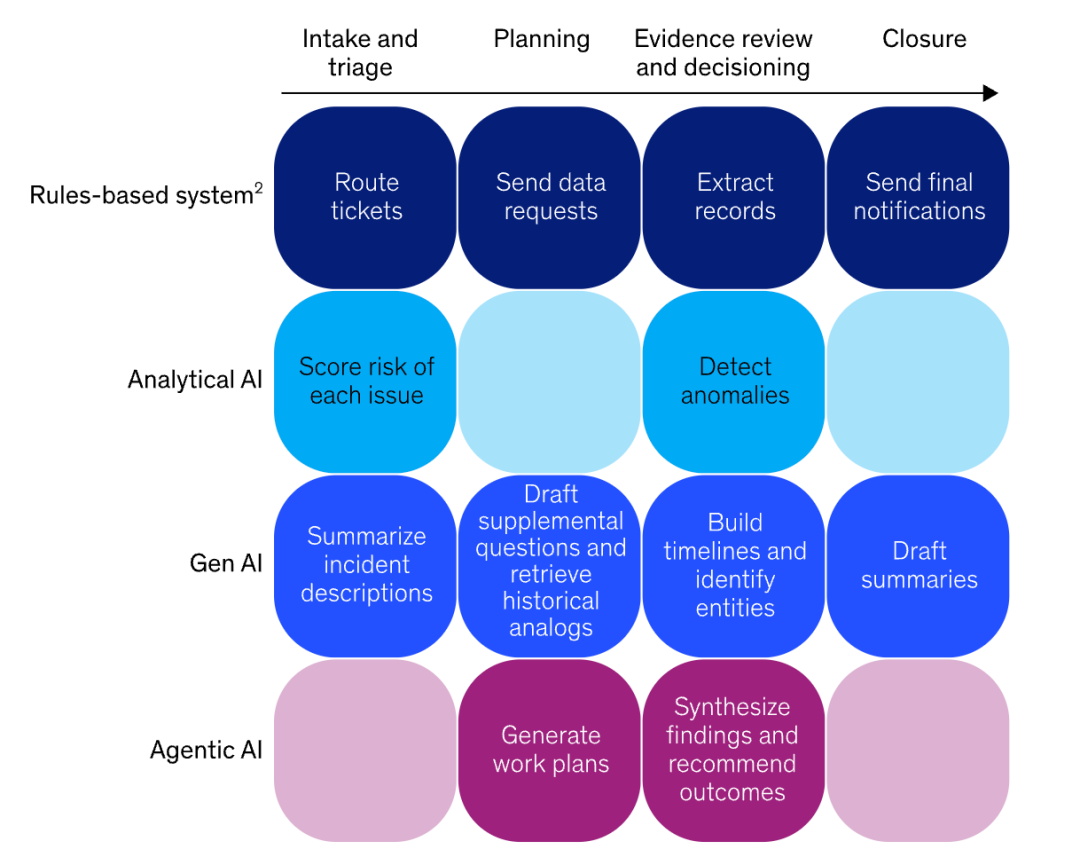
阿里通义翻译智能体:实现图片与文档翻译前后排版一致的深度解析
中英互译已不再是难题,但要在翻译前后保持排版一致,仍面临巨大挑战。即使是功能最强大的大模型,其翻译结果也往往仅限于纯文本输出,缺乏直观性。
经过一段时间的探索,我们发现了一款出色的翻译智能体——阿里通义翻译智能体,它能够实现以下效果:
该智能体能确保图片翻译前后排版高度一致,即便面对复杂的多文本框图片结构也能完美呈现。以下是具体操作步骤。
1. 图片翻译功能演示
访问阿里通义官网,在页面中点击“翻译”按钮,即可进入翻译界面:
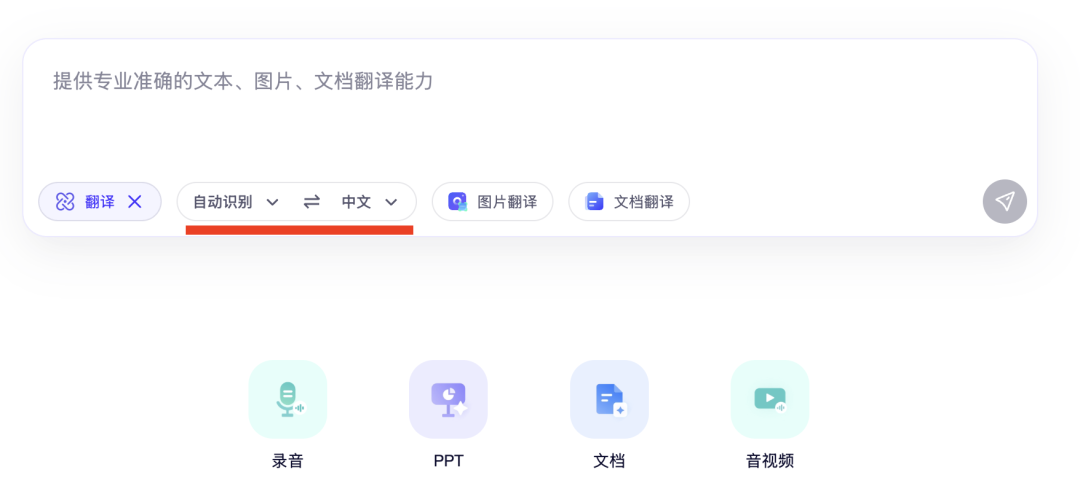
该智能体能自动识别源语言,默认目标语言为中文。如需翻译图片至中文,则无需进行额外调整:
将待翻译图片直接拖拽至聊天框:
点击发送按钮,即可获得保持原始排版的译文图片:
点击生成的图片,即可预览与原文排版一致的翻译结果:
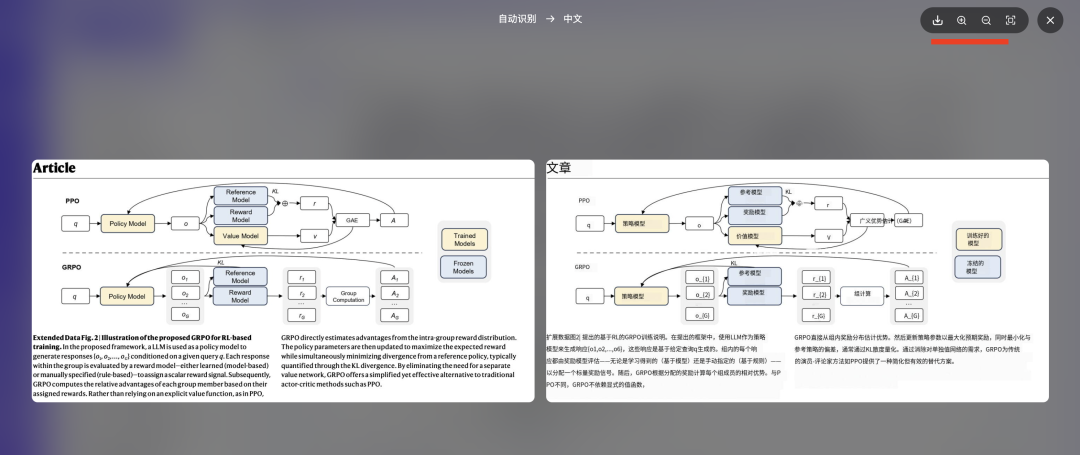
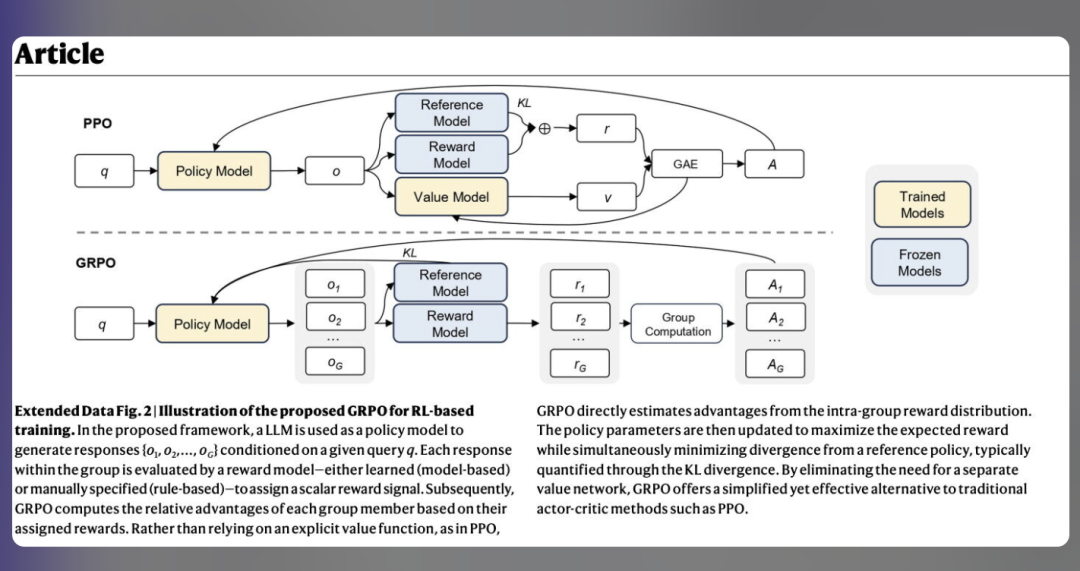
为更清晰地展示效果,以下将原文与译文截图分别呈现:
译文效果:
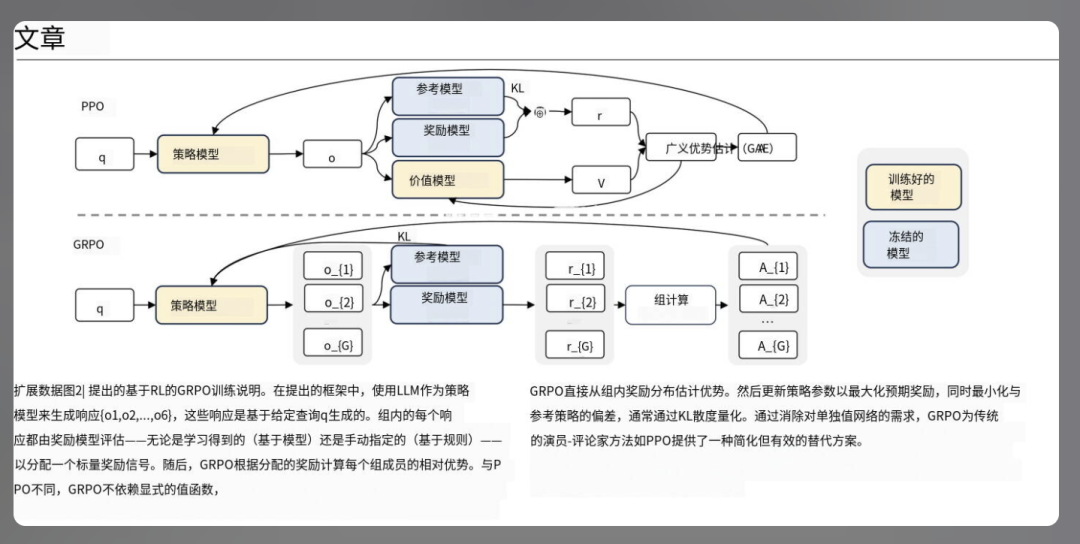
该智能体不仅翻译准确,更关键的是排版还原度极高,表现令人惊艳。对于有此需求的用户,强烈建议收藏使用。
2. 文档翻译功能演示
阿里通义翻译智能体不仅支持图片翻译,还能处理文档翻译,同样能保持排版一致性。以下将进行演示。
以一份35页的PDF文档为例:
其第一页内容如下:

该35页文档约在2-3分钟内完成处理。点击右上角的“还原排版”按钮,即可看到第一页的翻译结果:

首次使用时,其排版精准度令人印象深刻。实现如此精准的排版吻合度,实属不易。
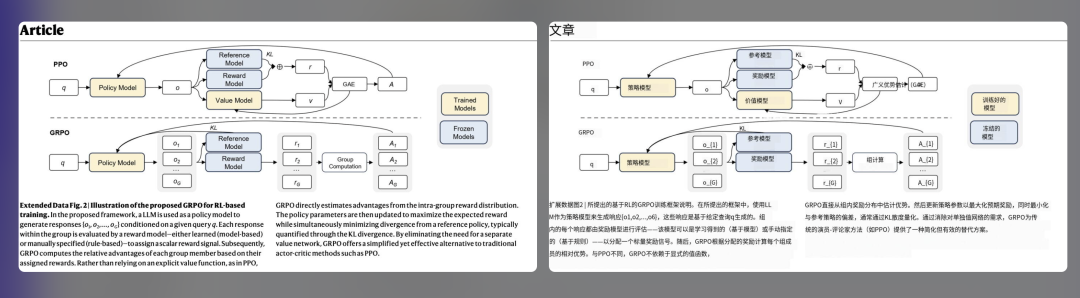
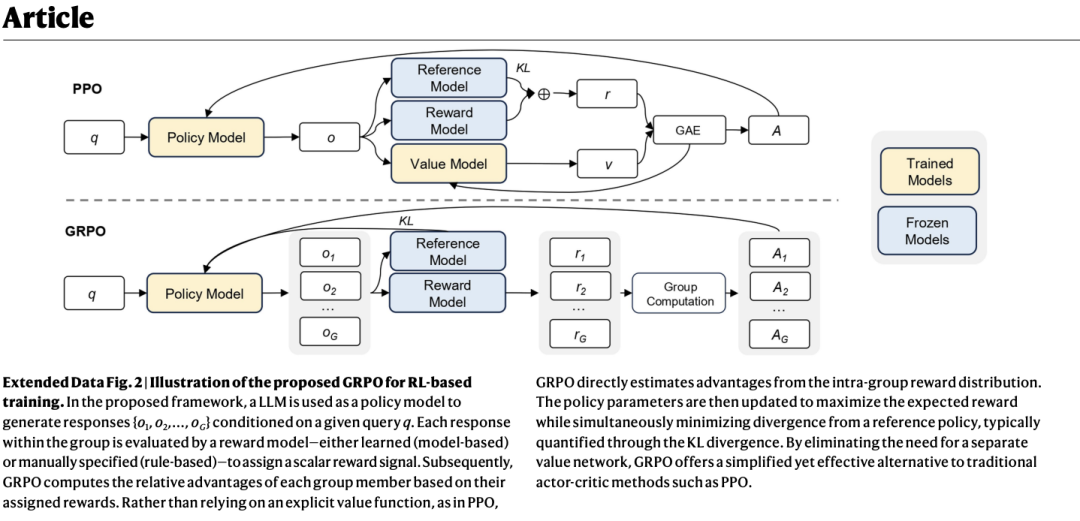
3. 翻译智能体排版技术原理
可以将PDF页面视为一个由众多“文字盒子”构成的画板:每一段文字、标题都被视为一个具有特定位置和尺寸的矩形框(bbox)。
通过Python库,例如PyMuPDF,可以逐一提取这些文字框的信息(包括坐标、宽高、原始文本、字体等),随后对每个文字框内的文本进行分段翻译,最终将其还原回原始位置。大致的实现代码如下:
import fitz
doc = fitz.open("input.pdf")
for page in doc:
blocks = page.get_text("blocks")
for b in blocks:
rect = fitz.Rect(b[:4])
src_text = b[4]
tgt_text = translate(src_text) # 你的翻译函数
page.insert_textbox(rect, tgt_text,
fontname="helv", fontsize=12,
color=(0,0,0), align=0)
doc.save("translated.pdf")
排版的主要难点在于,同一句子在翻译前后的长度往往存在差异,有时甚至非常显著。
通常情况下,若中英文文本长度差异较大,系统会通过自动换行、微调字号或字距等方式,确保文本在限定的文字框内恰好填充,避免溢出。
这项技术看似简单,但要真正实现并达到完美效果,需要反复的精细打磨。
总结
本文详细介绍了阿里通义翻译智能体在翻译后保持原始排版一致性的完整解决方案与实践体验,展示了其在该领域的卓越能力。
阿里通义翻译智能体在处理图片和多页PDF文档时,不仅能实现准确翻译,更能确保译文排版与原文高度匹配。
其背后的排版原理在于,将PDF文档中的每个页面视为由多个文字矩形框构成,通过精确提取每个框的坐标、字体信息和文本内容,然后逐块进行翻译,最终将译文智能回填至原位置。