最近,DeepSeek 发布了 DeepSeek-OCR 视觉-语言模型(VLM),其名称虽含“OCR”,但与传统OCR技术存在本质区别。传统的OCR旨在将图片中的文字识别并提取为文本,而DeepSeek-OCR则将长篇文本内容压缩成信息密度极高的“视觉快照”,使得大模型能够直接通过“看图”来理解内容。此方法通过更少的上下文窗口容纳更多、更丰富的信息,同时实现计算成本的指数级下降及处理速度的显著提升。深度分析表明,除了论文中提及的视觉记忆衰减机制,这项技术预计将为智能体的上下文工程和RAG带来新的思路。本文将从产品经理的视角,深入探讨以下关键问题:
- DeepSeek-OCR 究竟是什么?
- 它如何在信息量不变的情况下保持信息不过载?
- 为什么要专门设计模型而不是直接让多模态模型处理图片?
- 它为智能体的记忆管理带来了什么新思路?
- 它会取代 RAG 吗?
官方论文:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
DeepSeek-OCR 是什么?
大模型普遍存在上下文窗口限制,即其一次性记忆和处理的信息量有限。AI 助手或 Agent 需要感知大量且形态丰富的输入,例如用户输入、历史聊天、知识库、网页。当前主流做法是将这些信息转化为文字存储,并在需要时作为上下文输入给大模型。然而,这种“上下文工程”方式不仅会占用大量上下文长度,还可能在信息形态转化过程中产生损耗。
DeepSeek-OCR的核心思路在于用高度压缩的视觉形态管理上下文,在极致压缩的同时保留更多信息量。
它首先是一个端到端的视觉-语言多模态模型,这意味着它可以直接接收图片形态的输入,并理解包含的信息,最后生成文本信息。
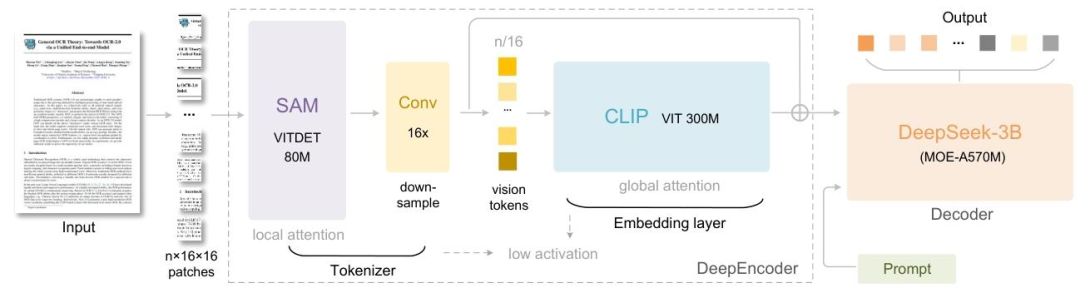 它由两部分组成:
它由两部分组成:
-
编码器(DeepEncoder):负责拆解和压缩文档为图像,其包含三个核心步骤:
- 细节扫描(SAM):将文档拆解为小像素块(例如 1024×1024 的图拆成 4096 个小块),逐块捕捉细节,例如文字笔画、小图标边缘及表格线条等。
- 打包(Conv):将前一步骤拆解的4096个小像素块,压缩为256个视觉包裹(16 倍)。如同快递站点将众多小包裹打包成大包裹,减少后续运输和处理的数量。在压缩过程中,关键信息如文字顺序、表格结构等得以保留,仅去除重复或非重要像素。
- 全局理解(CLIP):将“视觉包裹” 整合起来,理解整个文档的 “全局逻辑”,例如文本与标题的层级关系、表格与文字的相对位置、公式所属的内容段落等。
-
解码器(DeepSeek3B-MoE):负责翻译,即将编码器输出内容,翻译为人类可理解的信息。该解码器支持多专家协同工作,并可指定输出纯文本或带排版文本。
如何在信息量不变的情况下不过载?
一个常见的疑问是:尽管压缩能将更多信息塞进上下文窗口,但要理解的信息量并未改变,如何确保在处理时不发生过载?
这可以从以下两方面进行解读:
-
大模型的过载并非认知过载,而是计算过载。注意力机制的计算量与Token数量的平方成正比,因此,计算量能实现指数级下降。
- 传统长文本 (假设2万个Token)其计算复杂度约为4亿次交互计算;
- DeepSeek-OCR 压缩后 (2千个视觉 Token)其计算复杂度约为4百万次交互计算。
-
处理单元从字母级别升级到视觉模式,模型不再逐字逐句地“阅读”,而是在更高维度上直接“感知”整个文档的布局和内容模式。这如同人类速读文档,大脑能够并行、整体地处理信息。
还有一个问题:文字之间具有逻辑关联,通过像素块去理解,是否会忽略这些逻辑?抑或其最终仍需转化为文本进行理解?
对此,可从以下两方面分析:
-
像素本身不体现逻辑,但由像素构成的、人类文明几千年来沉淀下来的排版规范(标题、缩进、列表、表格),本身就是一种强大的、标准化的视觉逻辑语言。
-
视觉语言大模型并非在像素层面“拼凑”字母,而是建立起从“文字视觉模式”直达“语义概念”的快捷路径。
- 在其庞大的训练数据中,它已无数次接触单词 “Apple” 的各种字体、各种大小的视觉形态。
- 当它处理文本时,能够识别 Token “Apple”。
- 当它处理图像时,能够识别由像素构成的视觉模式 “Apple”。
- 在其庞大的神经网络中,这两种不同来源的输入,最终都将映射至同一个抽象的、内在的“苹果”概念上。
为什么要专门设计模型处理图片?
既然多模态模型能看图,PDF本质上是由一页页“图像”构成,为何不能直接将PDF截图(或渲染成图片)后输入给模型?
理论上可行,但实际效果会极其糟糕,且成本高昂到难以接受。
问题一:质量与清晰度的灾难。要保证文档上的小字都能被清晰识别,需采用高分辨率图片。然而,高分辨率又会导致Token数量激增。
问题二:信息编码效率极其低下。在文档图片中,白色背景是完全无用的冗余信息,而黑色文字笔画则是信息密度最高的部分。若采用通用图像处理方式编码文档图片,会浪费大量算力去处理无意义的白纸,效率极低。
DeepSeek-OCR 不是一个简单的截图工具,它是一个为 AI 的视觉系统量身定制的、信息密度极高的文档渲染引擎。其核心创新体现在两方面:
1 创造了一种“AI友好”的特殊字体/字符集。该模型设计了一套全新的、极其紧凑的字符表示方法。在此方法中,每个字符都以最少且最易被AI视觉模块区分的视觉模式进行表示。
2 智能化的版面压缩与重建。
在渲染过程中,该模型会智能地分析原始PDF布局,并丢弃所有不必要的空白区域。
它将原始文档结构(段落、表格、列表)以最优化的方式重新排列组合,并将其嵌入到一张尺寸虽小但信息密度极高的“视觉快照”中。
整个过程是可逆的,模型在“读取”这张压缩图时,可以通过训练好的解码能力,完美还原出原始的文档结构和所有文字。
智能体记忆管理新思路
遗忘机制是人类记忆最基本的特征之一。上下文光学压缩方法可以模拟这种机制:先将前几轮的历史文本渲染为图像进行初步压缩,然后逐步调整旧图像的尺寸以实现多级压缩。在此过程中,标记数量逐渐减少,文本变得越来越模糊,从而实现文本的遗忘。
这种方法固然是一种思路,但人类记忆机制的复杂性及其并非全然完美。这种记忆模式更适用于非重要的叙事性记忆,而对于经验沉淀、终身难忘的记忆,可学习推理记忆或许更为恰当。
它会取代 RAG 吗?
DeepSeek-OCR并不会取代RAG。恰恰相反,它将RAG从一个受限于上下文成本和信息碎片化的“瘸腿巨人”中解放出来,使其真正具备了处理海量、完整、复杂文档的“火眼金睛”。
首先,回顾RAG的核心流程:
- 检索 (Retrieval):当用户提问时,系统首先从一个庞大的知识库(向量数据库)中,检索出与问题最相关的几个文本片段。
- 增强 (Augmentation):系统将这些检索到的文本片段,连同用户原始的问题,一起塞进大模型的上下文窗口里。
- 生成 (Generation):大模型基于被增强了的Prompt,生成最终的答案。
这里面有几个瓶颈:
- 知识库向量化成本巨大。
- 文档结构与多模态信息的缺失。(当前多模态RAG方案正旨在解决此问题)
- 以及上下文长度的限制。
DeepSeek-OCR如何赋能RAG:
- 检索:初期仅将知识库文档的元数据向量化,并把文档内容压缩成视觉快照,搜索时返回Top-K篇相关文档的索引。
- 增强:直接加载这几篇完整文档的视觉快照。
- 模型状态:模型如同在快速翻阅几份完整的原始报告,对所有内容和结构了如指掌。
对于产品经理而言,这将使得产品经理能够构建出回答质量、处理效率和成本效益都远超当前所有 RAG 产品的下一代知识管理和分析工具。
总结
对于企业而言,DeepSeek-OCR的核心作用是将处理海量文档的成本中心,转变为企业的效率中心和智能中心。
对于AI Agent而言,DeepSeek-OCR 为上下文工程提供了新的发展方向。
对于产品经理而言,当下或许正是抓住机遇、构建真正自主智能体的最佳时机。