RAG优化技巧
本文将继续探讨RAG(Retrieval Augmented Generation)过程中高效召回以及提高召回准确率的方法。
RAG介绍
君君 AI,公众号:君君AIRAG技术与应用
RAG的基本过程是:接收用户Query,将其转换成向量,在知识库中检索出相似度高的Chunk,然后将Chunk和原始问题一同提供给大型语言模型(LLM),由LLM结合Chunk回答问题。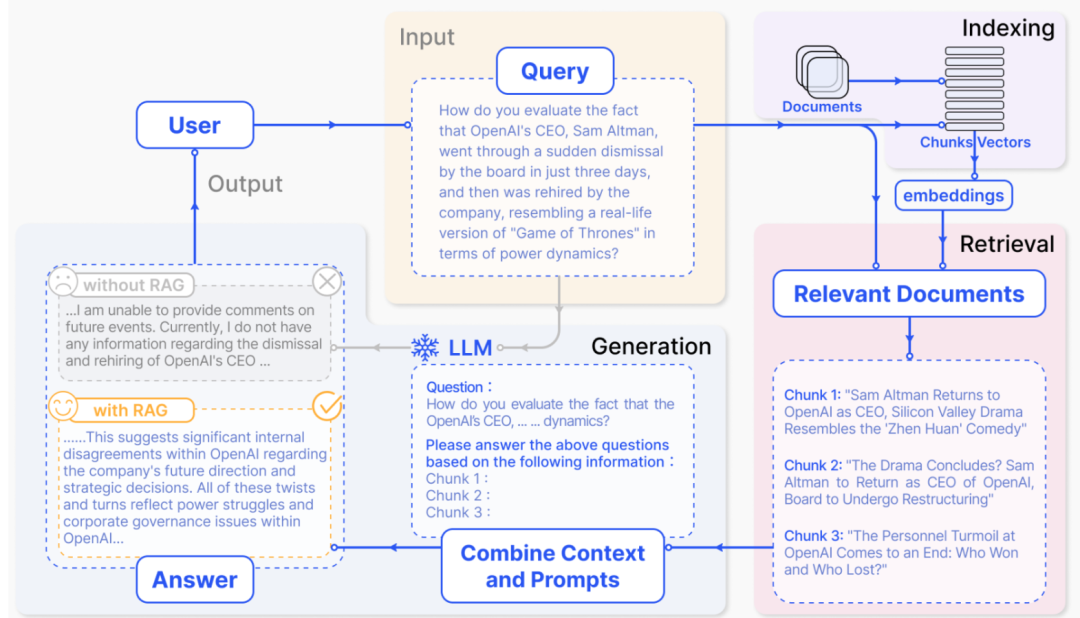 因此,提高RAG高效召回的方法可以从Query、知识库检索和知识库处理三个方面着手优化。
因此,提高RAG高效召回的方法可以从Query、知识库检索和知识库处理三个方面着手优化。
Query改写
Query改写的原因在于RAG的核心是“检索-生成”。如果检索阶段无法提供准确的答案,生成阶段的质量必然会降低。用户提出的问题往往是口语化、承接上下文、模糊甚至包含情绪的,而知识库中的内容通常是客观陈述性的。因此,需要将用户提问转换成书面化、精确的检索语句。改写过程可以通过精心设计Prompt,让大型语言模型辅助完成。Query改写主要有以下几种类型:
- 上下文依赖型 Prompt
instruction = """``你是一个智能的查询优化助手。请分析用户的当前问题以及前序对话历史,判断当前问题是否依赖于上下文。``如果依赖,请将当前问题改写成一个独立的、包含所有必要上下文信息的完整问题。``如果不依赖,直接返回原问题。``"""``prompt = f"""``### 指令 ###``{instruction}``### 对话历史 ###``{conversation_history}``### 当前问题 ###``{current_query}``### 改写后的问题 ###``"""
- 对比型 Prompt
instruction = """``你是一个查询分析专家。请分析用户的输入和相关的对话上下文,识别出问题中需要进行比较的多个对象。``然后,将原始问题改写成一个更明确、更适合在知识库中检索的对比性查询。``"""
- 模糊指代型 Prompt
instruction = """``你是一个消除语言歧义的专家。请分析用户的当前问题和对话历史,找出问题中"都"、"它"、"这个" 等模糊指代词具体指向的对象。``然后,将这些指代词替换为明确的对象名称,生成一个清晰、无歧义的新问题。``"""
- 多意图型 Prompt
instruction = """``你是一个任务分解机器人。请将用户的复杂问题分解成多个独立的、可以单独回答的简单问题。以JSON数组格式输出。``"""``prompt = f"""``### 指令 ###``{instruction}``### 原始问题 ###``{query}``### 分解后的问题列表 ###``请以JSON数组格式输出,例如:["问题1", "问题2", "问题3"]``"""``#原始查询: 门票多少钱?需要提前预约吗?停车费怎么收?``#分解结果: ['门票多少钱?', '需要提前预约吗?', '停车费怎么收?']
- 反问型 Prompt
instruction = """``你是一个沟通理解大师。请分析用户的反问或带有情绪的陈述,识别其背后真实的意图和问题。``然后,将这个反问改写成一个中立、客观、可以直接用于知识库检索的问题。``"""
判断何时使用哪种改写类型,同样可以利用大型语言模型。通过以下Prompt,模型可以识别查询类型并给出分析结果:
instruction = """``你是一个智能的查询分析专家。请分析用户的查询,识别其属``于以下哪种类型:``1. 上下文依赖型- 包含'还有'、'其他'等需要上下文理解的词汇``2. 对比型- 包含'哪个'、'比较'、'更'、'哪个更好'、'哪个更'等``比较词汇``3. 模糊指代型- 包含"它"、"他们"、"都"、"这个"等指代词``4. 多意图型- 包含多个独立问题,用"、"或"?"分隔``5. 反问型- 包含"不会"、"难道"等反问语气``说明:如果同时存在多意图型、模糊指代型,优先级为多意图``型>模糊指代型``请返回JSON格式:``{``"query_type": "查询类型",``"rewritten_query": "改写后的查询",``"confidence": "置信度(0-1)"``}``"""``prompt = f"""``### 指令 ###``{instruction}``### 对话历史 ###``{conversation_history}``### 上下文信息 ###``{context_info}``### 原始查询 ###``{query}``### 分析结果 ###``"""
Small to Big 索引策略
Small to Big 索引策略是一种高效的检索方法,特别适用于处理长文档或多文档场景。其核心思想是通过小规模内容(如摘要、关键字或段落)建立索引,并链接到大规模内容主体中。
小规模内容检索:用户输入查询后,系统首先在小规模内容(如摘要、关键句或段落)中检索匹配的内容。小规模内容通常是通过摘要生成、关键句提取等技术从大规模内容中提取的,并建立索引。
链接到大规模内容:当小规模内容匹配到用户的查询后,系统会通过预定义的链接(如文档 ID、URL 或指针)找到对应的大规模内容(如完整的文档、文章)。大规模内容包含更详细的上下文信息,为 RAG 提供丰富的背景知识。
上下文补充:将大规模内容作为 RAG 系统的上下文输入,结合用户查询和小规模内容,生成更准确和连贯的答案。
知识库处理
知识库问题生成与检索优化Prompt
将大段知识输入大型语言模型,让模型根据文本生成多个问题。再将这些生成的问题和原始知识一同作为Chunk存入知识库,从而提升知识库的丰富度和检索效率。
instruction = """``你是一个专业的问答系统专家。给定的知识内容能回答哪些多``样化的问题,这些问题可以:``1. 使用不同的问法(直接问、间接问、对比问等)``2. 避免重复和相似的问题``3. 确保问题不超出知识内容范围``"""
对话知识沉淀Prompt
产品上线后,日常产生的大量对话可以作为宝贵的知识来源。从这些对话中提取和沉淀有价值的知识,可以持续丰富知识库。这一过程同样可以由大型语言模型辅助完成。
首先,提取知识:
instruction = """``你是一个专业的知识提取专家。请从给定的对话中提取有价``值的知识点,包括:``1. 事实性信息(地点、时间、价格、规则等)``2. 用户需求和偏好``3. 常见问题和解答``4. 操作流程和步骤``5. 注意事项和提醒``"""
然后,对知识进行整理:
prompt = f"""``你是一个专业的知识整理专家。请将以下知识点进行智能合并,``生成一个更完整、准确的知识点。``### 合并要求:``1. 保留所有重要信息,避免信息丢失``2. 消除重复内容,整合相似表述``3. 提高内容的准确性和完整性``4. 保持逻辑清晰,结构合理``5. 合并后的置信度取所有知识点中的最高值``### 待合并的知识点:xxxxx``"""
最后,将整理后的知识作为Chunk放入知识库。
以上便是关于RAG提高召回率的一些优化技巧。欢迎在评论区分享您的更多想法,共同探讨。