

锦秋基金已完成 Pokee AI 的投资。
锦秋基金作为一家12年期的AI基金,始终秉持长期主义的投资理念,积极寻找具有突破性技术和创新商业模式的通用人工智能初创企业。
在大模型普遍追求规模化的背景下,锦秋基金被投企业Pokee AI选择了一条不同的发展路径,推出了研究智能体PokeeResearch,旨在让AI学会如何像研究员一样思考与验证。
Pokee AI最新发布了一款面向“深度研究”场景的7B参数智能体。该智能体采用“来自AI的反馈强化学习”(RLAIF)与链式思维的多轮自校验推理脚手架,旨在解决浅层检索、对齐度量薄弱和工具使用脆弱这三大痛点。

PokeeResearch是一款专为“深度研究”场景打造的智能体模型,它不依赖更大的参数规模,而是在“推理稳定性”和“事实可靠性”上实现了新的突破。
根据团队实验结果,PokeeResearch在10项深度研究/开放域问答基准上取得了同规模(7B)模型中的最佳平均表现。
➡️项目已在 GitHub 以 Apache 2.0 协议开源推理与模型代码
➡️ https://github.com/Pokee-AI/PokeeResearchOSS

核心看点
训练范式
PokeeResearch基于RLAIF + RLOO的统一强化学习框架,不依赖人工标注,直接围绕事实正确性、引文忠实度和指令遵循等“人类关注指标”优化策略。
推理稳健性
PokeeResearch引入了“研究—验证”双模式循环与多调用自纠错机制。当遇到工具调用失败时,它能诊断并恢复,并对候选答案进行自我核验以过滤显性错误。
7B模型量级中表现最佳
在HLE、GAIA、BrowseComp以及NQ、TriviaQA、HotpotQA、2Wiki、Musique、Bamboogle、PopQA共10项权威基准上,PokeeResearch均取得了7B量级同类最优平均成绩(mean@4)。

开源与复现
PokeeResearch基于MIT许可协议开源,提供了可复现的实验设置与推断代码,便于社区进行复评与落地集成。
技术要点
RLAIF 奖励设计
以外部LLM作为“客观评审”,对生成答案的语义正确性进行判定,避免F1/EM等纯词汇重合指标的偏差;训练中采用RLOO获得更稳健、几乎无偏的策略梯度估计。
研究—验证循环
研究模式中执行“分解问题—检索—阅读—综合”,并允许多次工具调用与自我修正;验证模式对答案做一致性与可用性检查,不通过则回到研究模式继续迭代。
工具链
PokeeResearch提供了面向互联网检索与网页内容提要的标准化工具接口,服务于证据收集、证据综合和结论生成的闭环。
数据与结果
信息寻址/网页浏览能力
在HLE、GAIA、BrowseComp等基准上,PokeeResearch取得了7B规模最优均值表现。
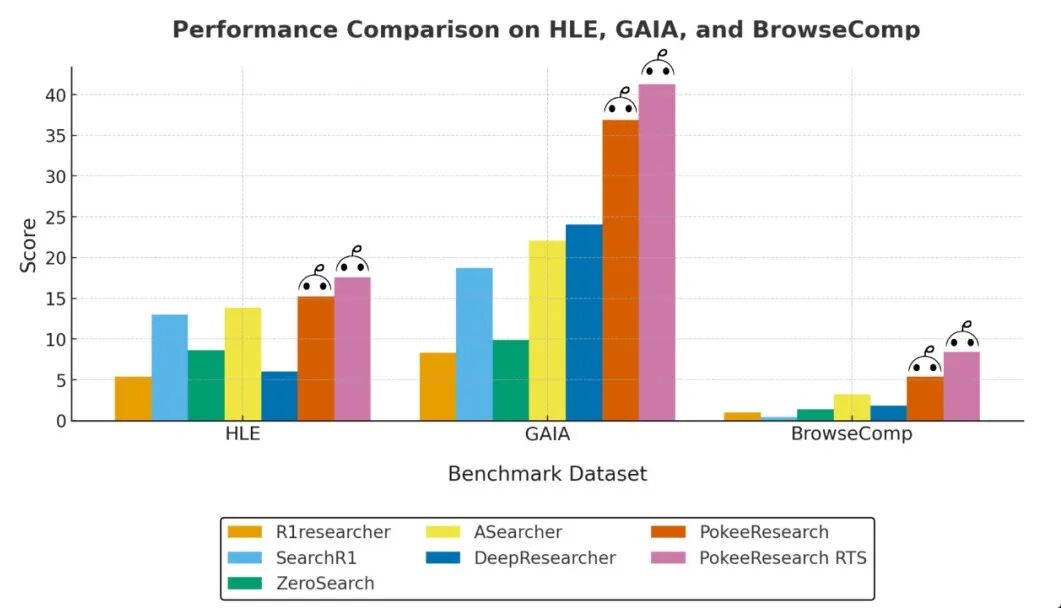
开放域/多跳问答
在NQ、TriviaQA、HotpotQA、2Wiki、Musique、Bamboogle、PopQA等基准上,PokeeResearch均取得了同等规模下的最佳表现。
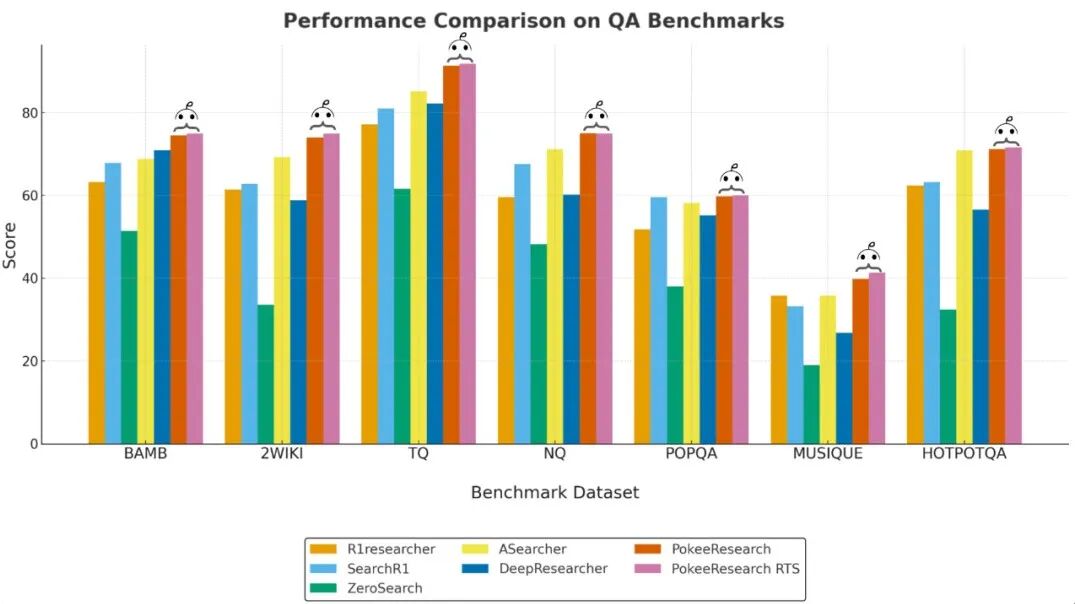
注:完整分数、评测设定与样本量详见论文正文与附录表格/图示。
典型场景
深度检索与事实核查
PokeeResearch支持多源证据汇聚,并提供可追溯的引用。
复杂长链路问答
PokeeResearch能够处理跨文档、多跳推理,并具备过程自校验能力。
研究写作与情报分析
PokeeResearch面向报告、备忘与策略建议,提供结构化输出。
研究团队与论文信息
论文题目
PokeeResearch: Effective Deep Research via Reinforcement Learning from AI Feedback and Robust Reasoning Scaffold
作者
Yi Wan, Jiuqi Wang, Liam Li, Jinsong Liu, Ruihao Zhu, Zheqing Zhu(Pokee AI)
开源地址:https://github.com/Pokee-AI/PokeeResearchOSS
(*为共同一作)
关于 Pokee AI
Pokee AI 专注于打造面向真实业务场景的 研究级智能体 与 自动化工作流,以开放、稳健的技术路线推动生产力工具的下一代体验。
作为全球首个可连接数千种工具的通用基础 AI 智能体,Pokee 无需定制集成、MCP 服务器或重新训练,便能将最热门的AI工具与最常用的互联网平台整合,为用户实现日常工作的全自动化。Pokee AI真正做到了“一个智能体,上千工具,丝滑体验”。当前,Pokee AI已在数十个互联网平台上线,并提供无缝衔接的安全登录方式。




