



本文改编自Opus Clip投稿,该公司是全球领先的AI视频剪辑工具提供商。2024年,Opus Clip用户量突破1000万,生成视频总量超过1.7亿。今年二月,公司成功获得由软银愿景基金二期领投的新一轮融资。

01
需求分析
1.1 需求背景与问题提出
2025年1月,Opus Clip推出了基于Milvus RAG系统构建的OpusSearch语义搜索产品。该产品旨在帮助专业视频创作者从素材库中精准查找所需内容,并根据热门话题获取AI推荐的视频片段。
尽管OpusSearch在自然语言模糊查询场景(例如“查找关于约会的搞笑时刻”)中表现出色,但随着用户深入使用,核心用户群体(如视频编辑、剪辑师)的反馈揭示了产品的功能缺陷。
高效的搜索功能是实现视频内容复用与变现的关键支撑,然而,单纯的语义搜索无法满足精确匹配需求。
典型问题场景如下:
视频编辑需要从播客中查找“第281集”片段,但搜索系统返回的却是第280集、第282集,甚至是第218集等近似结果;当搜索“她说了什么”时,系统可能返回“他说了什么”等语义相近但关键词不符的结果。这严重影响了用户的工作效率,违背了视频编辑对特定内容精准定位的核心诉求。
1.2 核心需求拆解
1.2.1 功能需求
-
精确匹配功能:支持用户通过特定关键词(如“第281集”)或短语(如“她说了什么”)进行搜索,精准返回包含目标内容的结果,避免近似值干扰。
-
双模式搜索兼容:在保留原有语义搜索优势的基础上,新增关键词精确匹配模式,支持用户根据不同场景灵活切换检索模式。
-
结果智能排序:精确匹配结果需结合相关性进行排序,确保最符合需求的内容优先展示。
1.2.2 非功能需求
-
运维成本可控:作为初创企业,需避免因功能升级引入多套搜索系统,从而控制运营负担与系统复杂性。
-
性能稳定:新增功能后,系统查询响应速度与匹配准确率需满足生产环境要求,在大规模文本数据集场景下仍保持高效运行。
-
扩展性良好:支持后续语义搜索与精确匹配的融合查询开发,预留技术扩展空间。
1.3 需求优先级
精确匹配功能实现(高优先级,解决当前核心痛点)>双模式搜索兼容(高优先级,保障用户使用连续性)>结果智能排序(中优先级,提升用户体验)>扩展性设计(中优先级,支撑长期业务发展)
02
解决方案设计
2.1 方案选型依据
针对精确匹配需求,初步备选方案包括引入Elasticsearch或MongoDB等传统数据库,以实现精确匹配并与现有Milvus语义搜索系统互补。
然而,该方案存在核心缺陷:维护多套搜索系统将大幅增加初创企业的运维成本与系统复杂性。
此外,如果仅采用一套方案,先进行关键词过滤再排序,常常会导致索引的图结构断联,最终可能出现图搜索提前终止或结果遗漏(miss)。图索引通常期望候选节点越多越好(recall高),若bitset中符合条件的点过少,将导致图结构基本失联,搜索效率直接退化为暴力搜索(brute-force)。
详情可参考Milvus Week | 向量搜索遇上过滤筛选,如何选择最优索引组合?
基于以上背景,最终选择基于现有Milvus向量数据库进行功能升级,核心依据如下:
(1)强大的社区支持:Milvus在GitHub上拥有38k+星标,社区活跃度高,技术迭代有保障。
(2)优秀的功能适配性:Milvus最新发布的全文搜索功能支持精确匹配场景,经私有数据集测试,即使在未调优状态下表现也已超预期。
(3)单一系统优势:可在同一数据库内实现语义搜索与精确匹配,无需新增系统,有效降低运维成本。
(4)显著的性能优势:在部分匹配准确性上表现出色,例如“喝酒场景”查询可避免检索到“用餐场景”等无关结果,并且查询时能返回更全面的结果。
(5)独特的技术策略:Milvus采用Alpha策略、ACORN(Approximate Clustering with Over-connected Randomized Neighbors)方法、动态选择邻居、元数据感知索引(Metadata-Aware Indexing)等方式,有效避免了其他常见向量数据库在引入关键词检索后导致的索引断裂、搜索成本增加等问题。
详情可参考Milvus Week | 向量搜索遇上过滤筛选,如何选择最优索引组合?
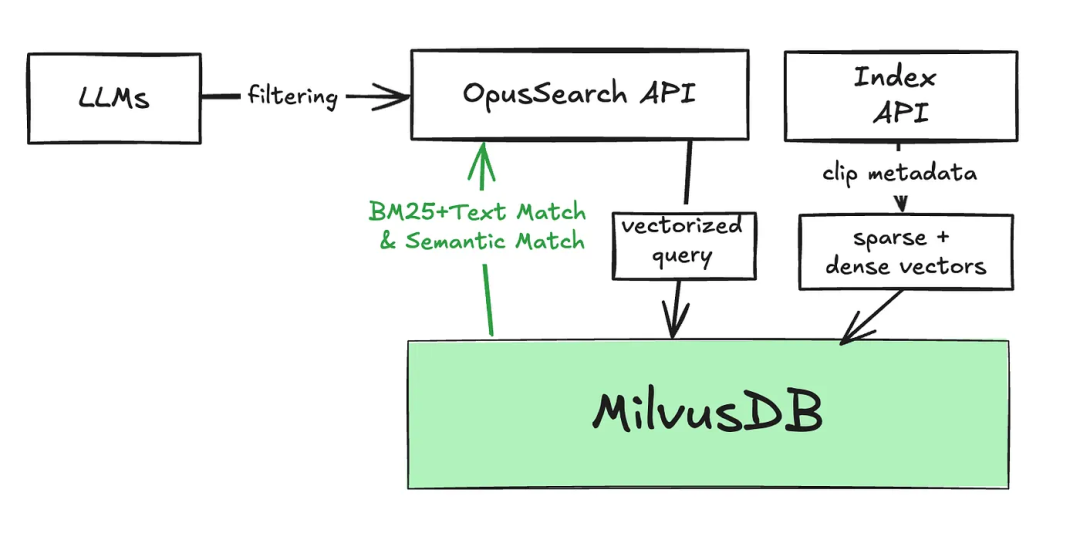
2.2 整体架构设计
以Milvus作为企业RAG架构的基础向量数据库,构建“BM25算法+TEXT_MATCH过滤器”的双核心精确匹配架构,并与原有语义搜索模块融合,形成双模式搜索系统。整体流程如下:
(1)过滤阶段:通过Milvus的TEXT_MATCH过滤器,精准筛选出包含用户查询关键词/短语的文档,实现精确匹配的基础筛选。
(2)排序阶段:基于BM25算法计算筛选后文档与查询的相关性,对精确匹配结果进行智能排序。
(3)模式融合:用户可自主选择“语义搜索模式”或“关键词检索模式”,系统将根据选择调用对应模块,实现双模式兼容。
架构核心优势:单一数据库系统同时支持语义搜索与精确匹配,简化运维架构,降低扩展成本;“先过滤后排序”的逻辑兼顾了精准性与相关性,有效提升用户体验。
2.3 核心技术实现
2.3.1 数据模式设计
关键设计要点包括:完全禁用停用词,因为在业务场景中“THE Office”与“Office”可能代表不同实体,需要保留所有词汇;启用TEXT_MATCH功能开关,以支持精确匹配过滤;配置词干提取器,实现“running”与“run”等词形还原匹配。具体代码实现如下:
export function getExactMatchFields(): FieldType[] { return [ { name: "id", data_type: DataType.VarChar, is_primary_key: true, max_length: 100, }, { name: "text", data_type: DataType.VarChar, max_length: 1000, enable_analyzer: true, enable_match: true, // This is the magic flag analyzer_params: { tokenizer: 'standard', filter: [ 'lowercase', { type: 'stemmer', language: 'english', // "running" matches "run" }, { type: 'stop', stop_words: [], // Keep ALL words (even "the", "a") }, ], }, }, { name: "sparse_vector", data_type: DataType.SparseFloatVector, }, ]}
2.3.2 BM25算法配置
BM25函数被配置为相关性排序的核心,负责将文本字段转换为稀疏向量用于计算。代码实现如下:
export const FUNCTIONS: FunctionObject[] = [ { name: 'text_bm25_embedding', type: FunctionType.BM25, input_field_names: ['text'], output_field_names: ['sparse_vector'], params: {}, },]
2.3.3 索引优化配置
针对生产数据集,对BM25关键参数进行了调优,以平衡术语频率与文档长度对结果的影响。同时,选用SPARSEINVERTEDINDEX索引类型以提升查询效率。
参数说明:
-
bm25_k1=1.2:适度重视术语频率,避免过度加权。
-
bm25_b=0.75:对较长文档施加适度惩罚,兼顾结果准确性与全面性。具体配置如下:
index_params: [ { field_name: 'sparse_vector', index_type: 'SPARSE_INVERTED_INDEX', metric_type: 'BM25', params: { inverted_index_algo: 'DAAT_MAXSCORE', bm25_k1: 1.2, // How much does term frequency matter? bm25_b: 0.75, // How much does document length matter? }, },],
2.3.4 搜索查询逻辑实现
通过“TEXT_MATCH过滤+BM25排序”的组合方式,实现了精确匹配查询,支持单关键词与多关键词组合场景。单关键词查询(例如“第281集”)与多关键词查询(例如“foo”和“bar”)的代码示例如下:
// 单关键词精确匹配查询await this.milvusClient.search({ collection_name: 'my_collection', limit: 30, output_fields: ['id', 'text'], filter: `TEXT_MATCH(text, "episode 281")`, // Exact match filter anns_field: 'sparse_vector', data: 'episode 281', // BM25 ranking query})// 多关键词精确匹配查询(同时包含多个关键词)await this.milvusClient.search({ collection_name: 'my_collection', limit: 30, output_fields: ['id', 'text'], filter: `TEXT_MATCH(text, "foo") and TEXT_MATCH(text, "bar")`, // 多条件精确匹配 anns_field: 'sparse_vector', data: 'foo bar', // BM25 ranking query})
03
实施效果与验证
3.1 实施时间线
2025年1月至5月:完成了Milvus全文搜索功能的调研、技术验证与方案设计;2025年6月:完成了精确匹配功能的开发、测试并成功部署上线。
3.2 核心成效
-
用户体验显著提升:精确匹配功能成功解决了视频编辑在查找特定集数、特定短语时的核心痛点,大幅减少了搜索相关的支持请求量。
-
双模式兼容达标:系统保留了原有语义搜索的优势,用户可以根据需求灵活切换模式,探索性查询与精准查询场景均得到了充分满足。
-
运维成本可控:基于单一Milvus数据库实现了功能升级,避免了引入多系统维护的额外负担,符合初创企业的资源约束要求。
-
业务价值强化支撑:高效的搜索功能进一步助力企业视频库内容复用与变现,为《All The Smoke》《KFC广播》《TFTC》等客户的成功案例提供了更坚实的技术支撑。
04
经验教训与注意事项
4.1 关键技术坑点规避
- 启用动态字段:
初期,未启用动态字段导致在生产环境中进行模式修改时,需要删除并重建集合,严重影响了系统稳定性。
解决方案:在创建集合时配置enable_dynamic_field: true,以保障模式修改的灵活性。
代码示例:
await this.milvusClient.createCollection({ collection_name: collectionName, fields: fields, enable_dynamic_field: true, // 关键配置:启用动态字段 // ... 其他配置})
-
集合设计模块化:采用每个功能域独立集合的设计思路,有效减少了模式变化对系统整体的影响,提升了可维护性。
-
内存优化:稀疏索引占用内存较高。在大规模文本数据集场景下,需要启用MMAP(内存映射文件)来利用磁盘存储,同时确保有足够的I/O带宽以维持性能。配置方式:在Milvus配置中设置
use_mmap: true。
05
未来规划
5.1 短期目标(1-3个月)
实现语义搜索与精确匹配的融合查询功能,支持用户在单一查询中同时包含精确匹配关键词与语义描述,例如“找到第281集的搞笑片段”(其中“第281集”使用精确匹配,“搞笑片段”使用语义搜索),以进一步提升搜索效率。
5.2 长期规划
构建“智能融合搜索”体系,使用户无需手动切换模式。系统将根据查询内容自动判断场景,智能选择精确匹配、语义搜索或融合模式,实现“用户无需思考模式,只关注需求本身”的极致体验,并持续强化企业视频库的货币化支撑能力。





