

OpenAI 再次开源!安全分类模型 gpt-oss-safeguard 准确率超越 GPT-5
OpenAI 近期对外开源了两款专为安全分类设计的推理模型。

此次发布的 gpt-oss-safeguard 包含 120B 和 20B 两个参数量版本,均基于 gpt-oss 开源模型微调而成。
该模型采用 Apache 2.0 许可证,这意味着开发者可以自由使用、修改和部署。
告别传统分类器的束缚
传统的安全分类器如何运作?通过收集大量安全与不安全内容的示例,并从中训练模型学习区分规律。然而,这种方法的固有缺陷在于分类器未能直接“理解”安全策略本身,其判断多基于对标注背后逻辑的推测。
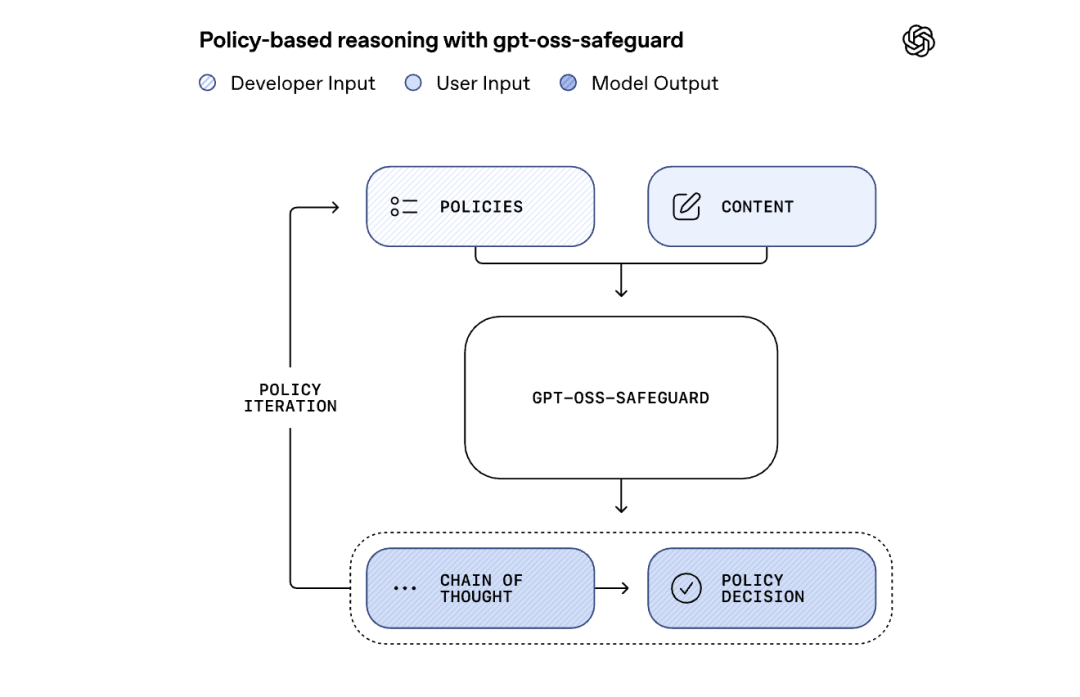
与此不同,gpt-oss-safeguard 能够直接理解开发者提供的策略文档,并据此对内容进行分类。这如同赋予 AI 一本实时可查阅的规则手册,使其能够依据规则做出判断。更重要的是,开发者可以随时修改策略,而无需重新训练模型。无论是游戏论坛需识别作弊言论,还是产品评论网站欲筛查虚假评价,只需编写相应的策略文档即可实现。
推理能力超越 GPT-5
OpenAI 在内部评估中进行了一项实验:同时向模型提供多个策略,以测试其准确分类能力。只有在所有策略上均判断正确才被视为成功。结果显示,gpt-oss-safeguard 的表现超越了 GPT-5-thinking 和基础的 gpt-oss 模型。鉴于 gpt-oss-safeguard 的参数量远小于 GPT-5,这种“以小博大”的胜利尤为引人注目。
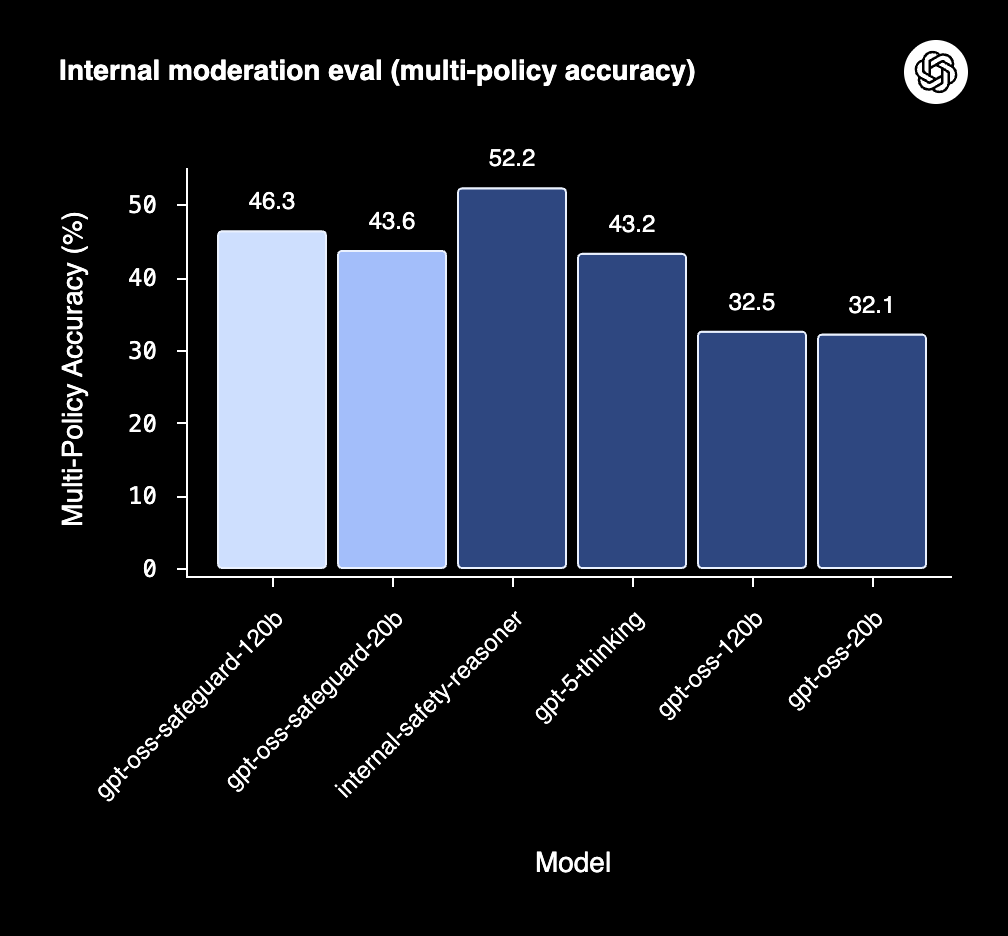
在 2022 年内容审核评估集中,gpt-oss-safeguard 的性能略微领先于所有测试模型,包括 OpenAI 内部的 Safety Reasoner 和 GPT-5-thinking。尽管在 ToxicChat 数据集上,GPT-5-thinking 和 Safety Reasoner 略占优势,但考虑到 gpt-oss-safeguard 的模型规模,其展现出更高的性价比。
内部秘密武器
事实上,OpenAI 内部已长期采用此方法。其名为 Safety Reasoner 的工具正是 gpt-oss-safeguard 的原型。OpenAI 透露,在近期部分产品发布中,用于安全推理的算力占比高达 16%。在图像生成和 Sora 2 等应用中,Safety Reasoner 能够动态评估输出,实时拦截不安全的生成内容。针对生物学和自残等敏感领域,该系统首先通过快速小模型进行初步筛选,再由 Safety Reasoner 进行详细审查。这种“先快速过滤,再精准判断”的分层架构,已成为 OpenAI 安全系统的核心组件,覆盖 GPT-5 和 ChatGPT Agent 等所有系统。
开发者的新机遇
Hugging Face 的 Vaibhav (VB) Srivastav (@reach_vb) 对此表示兴奋,并第一时间分享道:
Wohoooo! 恭喜发布 🔥 Love the weights on the hub 🤗

该模型已上传至 Hugging Face,开发者可立即下载使用。
OpenAI 还提供了详细的开发文档,指导用户如何编写策略提示词、选择合适的策略长度,以及将推理输出集成到生产环境的信任与安全系统中。

Mark 마크 (@Makuh90) 则对 OpenAI 表达了支持:
欣赏这种精神。坚持到底,绝不放弃。安全至上,必须面对。
与社区共建
OpenAI 此次选择与 ROOST 合作,共同完善此开源版本。双方共同确定了开发者的关键需求,测试了模型,并编写了开发者文档。同时,他们发布了 cookbook,详细阐述了如何编写策略提示以最大化 gpt-oss-safeguard 的推理能力,如何选择合适的策略长度进行深度分析,以及如何将 oss-safeguard 的推理输出集成到生产信任与安全系统中。

ROOST 首席技术官 Vinay Rao 评价道:
gpt-oss-safeguard 是首个采用“自带策略和危害定义”设计的开源推理模型。在我们的测试中,它在理解不同策略、解释推理过程及应用策略细微差别方面均表现出色。
ROOST 还建立了一个模型社区,旨在探索如何利用开源 AI 模型保护网络空间。该社区将汇集安全从业者和研究人员,分享在安全工作流程中实施开源 AI 模型的最佳实践。
然而,gpt-oss-safeguard 亦存在其局限性。对于极其复杂的风险,基于数万个高质量标注样本训练的专用分类器可能表现更佳。此外,推理模型需要较多的计算资源和时间,这使其难以扩展到所有平台内容。尽管如此,这些局限性并不妨碍 gpt-oss-safeguard 成为开发者工具箱中的强大工具。当需要快速适应新出现的风险、处理高度细分的领域,或缺乏足够样本训练专用分类器时,gpt-oss-safeguard 仍是理想选择。




