本文将深入探讨一个让大语言模型(LLM)“开挂”的技巧——RAG:检索增强生成(Retrieval-Augmented Generation)。
在使用 ChatGPT 或其他大模型时,用户可能遇到以下问题:
- 知识过时:模型可能只知道训练数据截止前的信息。
- 无法访问私有资料:例如公司的内部文档或最新的 PDF 报告。
这些是LLM的天然局限。RAG 的目标是赋予大模型实时检索信息的能力,使其不仅依赖预训练的“记忆”,还能像人类一样查阅文档和数据库,从而生成更准确的回答。
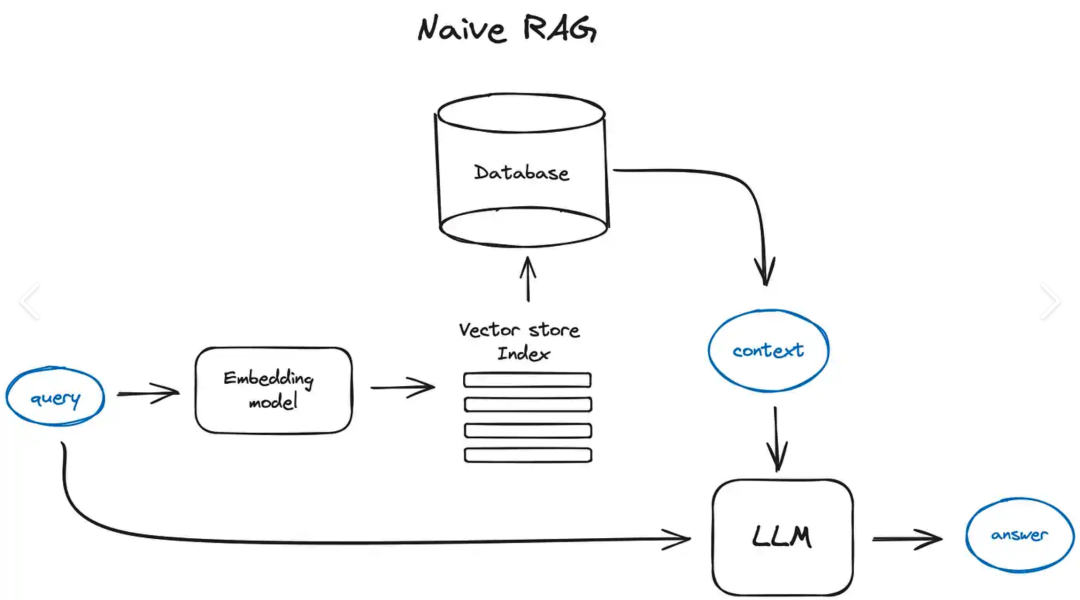
RAG 的工作原理
RAG 的工作流程可概括如下:
- 载入文档(PDF、Word、网页等),并切分成可处理的小块。
- 将每一小块文本转换成向量(Embedding),存储到专门的“向量数据库”中。
- 用户提出问题后,系统会首先在向量数据库中查找最相关的内容。
- 将找到的相关内容与用户问题一同发送给大模型,模型便能基于最新资料生成回答。
这可以理解为:结合大模型的“记忆”与“实时检索”能力,实现更准确、更专业的回答。
文档处理的关键技巧
在RAG实践中,文本切分是关键的第一步。不恰当的切分可能导致模型回答不完整或上下文缺失。常见问题包括:
- 粒度太大:模型一次无法读取完整信息,导致检索不精准。
- 粒度太小:上下文被打断,模型回答可能不连贯。
- 改进方法:采用定长与重叠切块相结合的方式。
例如,采用 chunk_size=500 字符、overlap_size=120 字符的设置,可确保文本块之间有部分重叠,从而帮助模型更完整地理解上下文。
chunks = split_text(paragraphs, chunk_size=500, overlap_size=120)
检索的两种主流方式
-
关键词检索(Keyword Search)
类似于传统搜索引擎,通过精确匹配词语进行查找,适合检索专有名词、缩写等。
-
向量检索(Vector Search)
通过将文本向量化后计算语义相似度,即使没有完全匹配的关键词,也能找到语义相近的内容。常用的相似度算法包括余弦相似度(cosine similarity)和欧氏距离。
在实际应用中,混合检索策略通常能取得最佳效果:关键词搜索提供精准性,而向量搜索提供语义智能,两者结合往往优于单独使用任一方法。
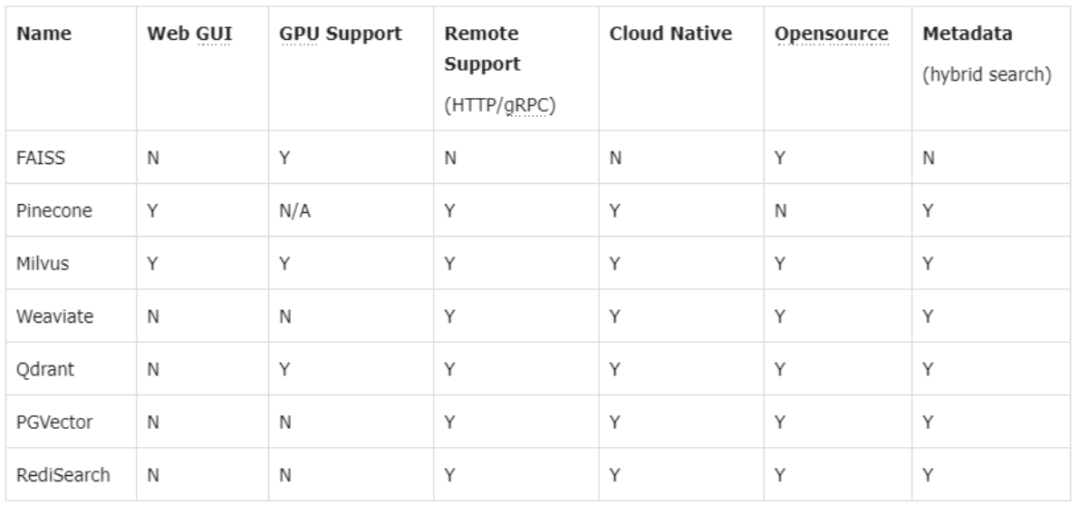
向量数据库的选择
向量数据库是 RAG 系统的“记忆库”,用于存储和检索文本向量。常见的向量数据库选择如下:
大模型接入
检索仅负责“查找资料”,最终的回答生成仍需依赖大模型。在示例代码中,作者使用了本地部署的 Ollama (llama3) 来处理中文问题:
answer = get_completion_ollama(prompt, model="llama3")
如果使用 OpenAI API,只需将模型替换为 gpt-4 或 gpt-4o 即可。
实战:ChatPDF 项目:构建PDF问答助手
为了便于理解,本文提供了一个完整的 RAG_ChatPDF.py 示例项目,该项目能够:
- 自动读取 PDF 文档。
- 采用“定长+重叠”的方式切分文本。
- 使用 ChromaDB 建立向量库。
- 利用本地 LLaMA3 模型回答问题。
项目启动后,用户只需输入问题,即可利用基于自身 PDF 文档训练的“知识型 ChatGPT”获取回答。
总结
RAG 技术赋予大模型“读取最新文档+实时查询知识”的能力,使其特别适用于企业内部知识库、论文问答、客户支持等场景。
其核心流程为:文本切分 → 向量化 → 建立知识库并检索 → 调用大模型生成回答。
通过合理的文本切块策略、混合检索方法以及选择合适的向量数据库,RAG 系统能够显著提升回答的准确性和实用性。
读者若想自行构建一个 PDF 问答助手,可直接参考以下完整代码实现。
# -*- coding: utf-8 -*-
"""
RAG_ChatPDF.py
- 读取 PDF -> 句子级 + 交叠式切块
- ChromaDB 建向量库
- 用 Ollama (llama3) 中文回答
"""
import os
import json
import re
import requests
import fitz # PyMuPDF
import chromadb
from chromadb.config import Settings
import torch
from transformers import AutoTokenizer, AutoModel
# ========== 1) 读取 PDF ==========
def extract_text_from_pdf(pdf_path: str) -> str:
doc = fitz.open(pdf_path)
text = []
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
text.append(page.get_text())
return "
".join(text)
# ========== 2) 更鲁棒的“定长+交叠”切块 ==========
# 英文句子切分(可选)
try:
from nltk.tokenize import sent_tokenize
except Exception:
sent_tokenize = None
def _fallback_sentence_split(p: str):
"""兜底的简单分句:英文按 .!?; 中文按。!?;,"""
# 先用英文界定
parts = re.split(r"(?<=[.!?;])s+", p.strip())
out = []
for seg in parts:
# 再粗分中文标点,防止太长
out.extend([s for s in re.split(r"(?<=[。!?;,])", seg) if s and s.strip()])
return [s.strip() for s in out if s.strip()]
def sentence_tokenize_paragraphs(paragraphs):
"""把多段文本切成句子列表。优先用 nltk.sent_tokenize(英文),否则用兜底。"""
sentences = []
for p in paragraphs:
p = p.strip()
if not p:
continue
if sent_tokenize:
try:
ss = sent_tokenize(p)
if ss and len(" ".join(ss)) >= 3:
sentences.extend([s.strip() for s in ss if s.strip()])
continue
except Exception:
pass
# 兜底
sentences.extend(_fallback_sentence_split(p))
return sentences
def split_text(paragraphs, chunk_size=300, overlap_size=100):
"""
- 先句子化
- 前向把句子拼到 chunk_size
- 追加时,从“上一个 chunk 的末尾”回溯 overlap_size 字符,作为 overlap
"""
sentences = [s.strip() for p in paragraphs for s in sentence_tokenize_paragraphs([p])]
chunks = []
i = 0
while i < len(sentences):
# 当前块,从第 i 个句子开始
chunk = sentences[i]
# 计算向前的重叠部分(从 i-1 往回拼)
overlap = ''
prev = i - 1
while prev >= 0 and len(sentences[prev]) + len(overlap) <= overlap_size:
overlap = sentences[prev] + ' ' + overlap
prev -= 1
chunk = overlap + chunk
# 再往后拼,直到到达 chunk_size
next_idx = i + 1
while next_idx < len(sentences) and len(sentences[next_idx]) + len(chunk) <= chunk_size:
chunk = chunk + ' ' + sentences[next_idx]
next_idx += 1
chunks.append(chunk.strip())
i = next_idx # 跳到下一个起点
return chunks
# ========== 3) ChromaDB 连接器 ==========
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
# 允许 reset,便于反复运行
self.chroma_client = chromadb.Client(Settings(allow_reset=True))
self.chroma_client.reset()
self.collection = self.chroma_client.get_or_create_collection(collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
self.collection.add(
embeddings=self.embedding_fn(documents),
documents=documents,
ids=[f"id{i}" for i in range(len(documents))]
)
def search(self, query, top_n=3):
return self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
# ========== 4) 向量(embedding) ==========
# 注:你本机已成功使用 all-MiniLM-L6-v2;中文也能用,但多语更好(若联网可换 paraphrase-multilingual-MiniLM-L12-v2)
_EMB_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
_tokenizer = None
_model = None
def _load_embedder():
global _tokenizer, _model
if _tokenizer is None or _model is None:
_model = AutoModel.from_pretrained(_EMB_MODEL)
_tokenizer = AutoTokenizer.from_pretrained(_EMB_MODEL)
def get_embeddings(texts):
_load_embedder()
inputs = _tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
embs = _model(**inputs).last_hidden_state.mean(dim=1).cpu().numpy()
return embs
# ========== 5) 调用 Ollama (与 get_completion_ollama.py 一致) ==========
def get_completion_ollama(prompt: str, model: str = "llama3"):
url = "http://localhost:11434/api/chat"
headers = {"Content-Type": "application/json"}
data = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
resp = requests.post(url, headers=headers, json=data, timeout=120)
resp.raise_for_status()
result = resp.json()
return result["message"]["content"]
# ========== 6) RAG 机器人(中文提示词) ==========
class RAG_Bot:
def __init__(self, vector_db, n_results=3):
self.vector_db = vector_db
self.n_results = n_results
def build_prompt(self, context_docs, query):
# 把检索到的若干片段做成中文提示词
ctx = "
".join([f"【片段{i+1}】
{doc}" for i, doc in enumerate(context_docs)])
prompt = (
"你是一个严谨的中文助手。请仅依据下面提供的参考片段,用简洁中文回答用户问题;"
"如果资料里没有答案,请明确说明“未在资料中找到直接答案”。
"
f"{ctx}
"
f"用户问题:{query}
"
"请用中文作答。"
)
return prompt
def chat(self, user_query: str):
search_results = self.vector_db.search(user_query, self.n_results)
docs = search_results.get("documents", [[]])[0]
prompt = self.build_prompt(docs, user_query)
try:
answer = get_completion_ollama(prompt, model="llama3")
except Exception as e:
answer = f"调用本地大模型失败:{e}"
return answer
# ========== 7) 主程序 ==========
if __name__ == "__main__":
# ---- 修改为你的 PDF 路径 ----
pdf_path = "/Users/axia/Documents/Alex/ai_2025/research_manufacturing_industry.pdf"
if not os.path.exists(pdf_path):
print(f"❌ 找不到 PDF:{pdf_path}")
exit(1)
print("正在读取 PDF ...")
text = extract_text_from_pdf(pdf_path)
print("正在切分文本 ...")
# 先按换行粗分为段;再做“定长+交叠”的切块
paragraphs = [p.strip() for p in text.split("
") if p.strip()]
chunks = split_text(paragraphs, chunk_size=500, overlap_size=120)
print(f"共得到切块:{len(chunks)}")
print("加载/构建向量库 ...")
vector_db = MyVectorDBConnector("pdf_collection_overlap", get_embeddings)
vector_db.add_documents(chunks)
# 交互式问答
print("✅ 准备就绪。开始提问吧!输入 q / quit / exit 退出。")
bot = RAG_Bot(vector_db, n_results=3)
while True:
try:
user_query = input("
你的问题> ").strip()
except (EOFError, KeyboardInterrupt):
print("
👋 已退出。")
break
if user_query.lower() in {"q", "quit", "exit"}:
print("👋 已退出。")
break
if not user_query:
continue
print("
—— 答复 ——")
resp = bot.chat(user_query)
print(resp)