Zero-RAG:对冗余知识说“不”
一、LLM 知识渐满,RAG 负担渐重
图 1:知识冗余示意图
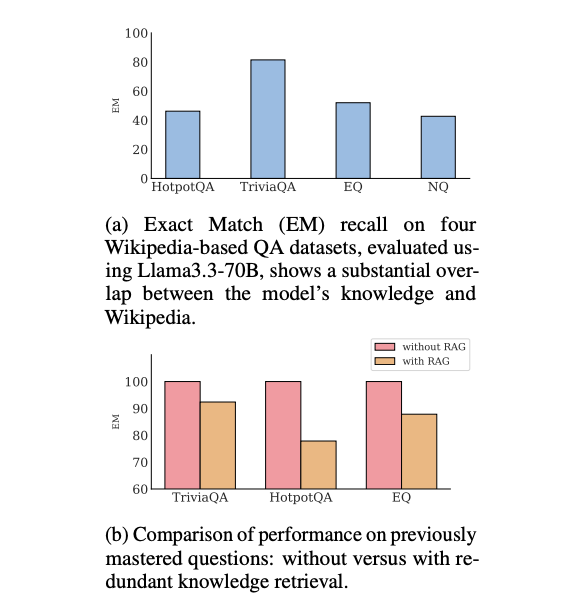
- (a) Llama3.3-70B 在四个 Wikipedia 风格 QA 数据集上,裸模型 Exact-Match 召回率达到或超过 40%——这表明近一半问题大模型本身就能够回答。
- (b) 将相应的维基百科段落再次送入上下文后,准确率反而下降了 20 个百分点——冗余知识在此成了“噪声”。
结论:外部知识库(corpus)与大模型内部知识存在高度重叠,继续进行“全量检索”无异于浪费成本、增加延迟并降低效果。
二、Zero-RAG 成效显著:30% 维基百科可删,22% 延迟立降,效果不减
复旦大学邱锡鹏团队提出了Zero-RAG技术,该技术通过“掌握度评分”指标,精准识别并剪除RAG知识库中的冗余知识。经过剪枝后,对于大模型已“掌握”的问题,其回答将主要依赖模型自身的内部知识。
表 1:Zero-RAG主实验汇总(Llama3-70B 与 Llama3.3-70B 性能对比)
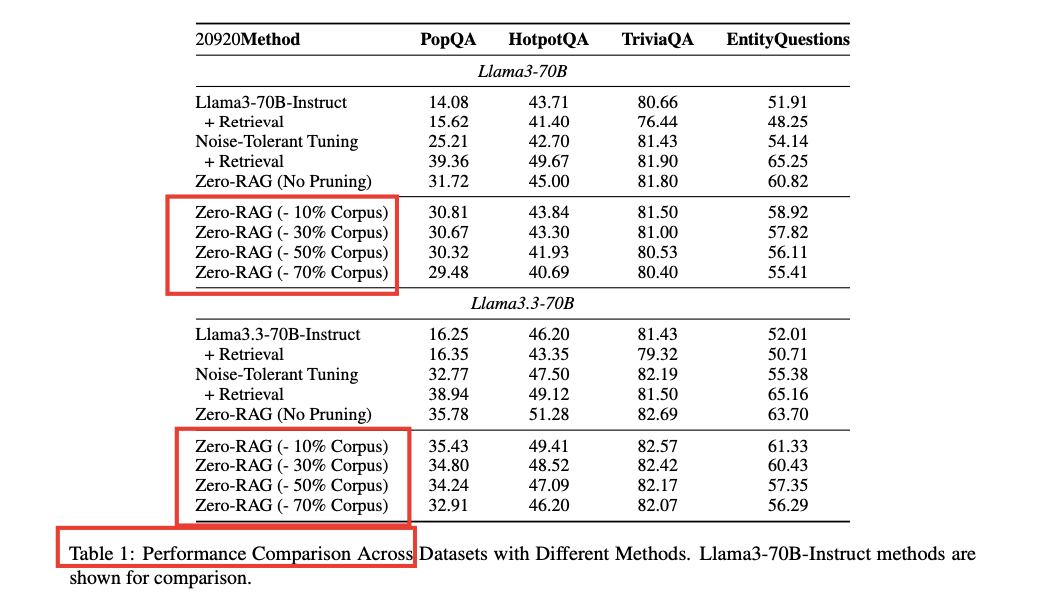
- 在 TriviaQA、EntityQuestions、PopQA、HotpotQA 等数据集上,剪除 30% 的知识库(corpus),Exact-Match (EM) 指标下降不到 2%;即使剪除 70%,也仅下降约 3 个百分点。
- 检索延迟平均降低 22%(参考表 4)。
- 经过 Noise-Tolerant Tuning 后,部分数据集的性能甚至超越了使用全库的传统 RAG 方案。
简而言之:Zero-RAG 实现了“零冗余”的目标,不仅能有效剪枝、显著加速,还能保持甚至提升模型效果。
三、Zero-RAG 技术方案详解
图 4:Zero-RAG 四阶段流水线
3.1 Mastery-Score —— 为每条句子打“掌握度”分数
图 3:Mastery-Score 计算流程
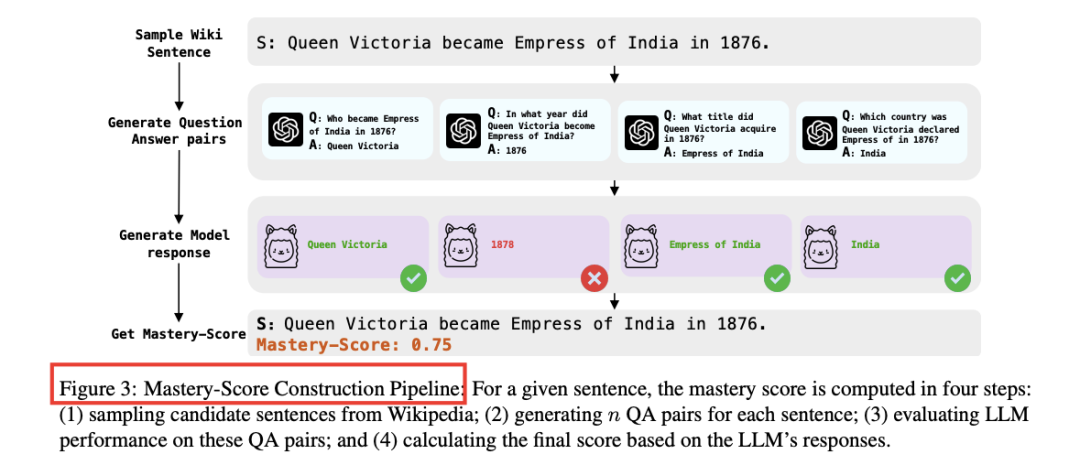
- 使用大型语言模型(LLM)对给定句子 s 生成 n 组问答对(QA)。
- 让同一 LLM 回答这 n 个问题,计算 Exact-Match (EM) 均值,从而得到 Mastery-Score M(s)。
- 训练一个小型回归模型来预测 M(s),并依据预设的百分位阈值 τ 直接删除 Mastery-Score 较高的句子(算法详见附录 A.1)。
结果显示:原始包含 1.38 亿句维基百科知识的索引,在剪枝 30% 后,其体积同比例缩小。
3.2 Query Router —— 查询前先判断模型是否“已知”
表 3:Zero-RAG消融实验结果
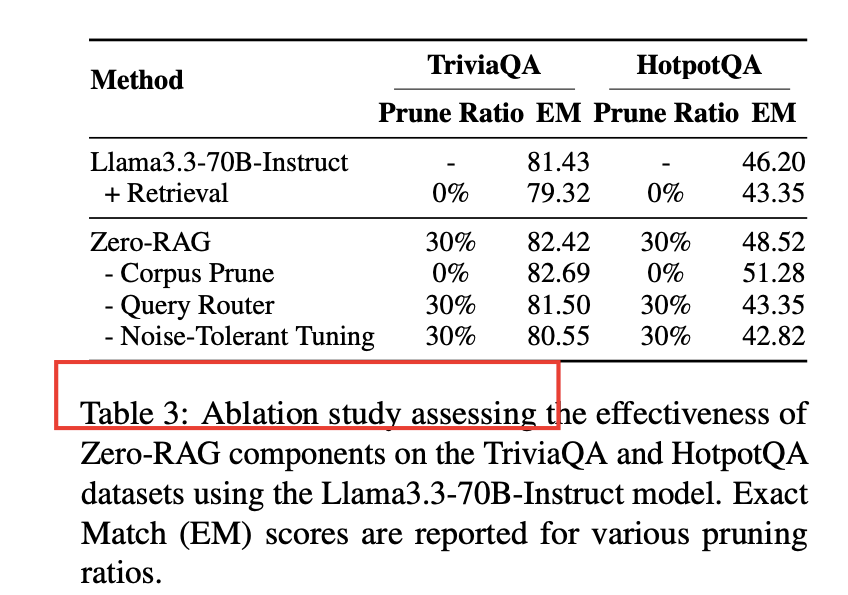
- 首先让经过 Noise-Tolerant 微调的模型回答训练集中的问题,将能正确回答的问题标记为“已掌握”(mastered)。
- 训练一个二分类器来判断问题是否“已掌握”。在推理时,对于“已掌握”的问题,直接跳过外部检索步骤,从而减少延迟并避免引入噪声。
消融实验结果表明:移除 Query Router 后,Exact-Match (EM) 性能显著下降,这证明了额外的检索有时反而会引入干扰。
3.3 Noise-Tolerant Tuning —— 即使检索到无用文档也能保持稳定
训练数据采用以下三种配方:
- 仅提供问题 → 答案(不使用 RAG)
- 提供问题 + 相关文档 → 答案
- 提供问题 + 随机噪声文档 → 答案
通过统一的损失函数训练模型,使其学会忽略无用信息片段,并主要依赖其内部知识进行回答。
经过此项微调,即使在剪枝后的知识库中偶尔检索到不相关的句子,模型也能够“视而不见”,保持回答的准确性。
四、Zero-RAG 如何剪除冗余知识?案例分析
表 6:Zero-RAG案例研究

句子:“Queen Victoria became Empress of India in 1876.”
Llama3-70B 模型能够直接回答生成的所有 4 个问答对 ⇒ Mastery-Score=1 ⇒ 该句子被直接剪除。
这类“教科书级别”的常识性知识,正是 Zero-RAG 旨在实现“零冗余”的剪除目标。
Zero-RAG: Towards Retrieval-Augmented Generation with ZeroRedundant Knowledgehttps://arxiv.org/pdf/2511.00505