

当RAG遭遇分析瓶颈:问题的根源
想象这样一个场景:在一次关键的季度复盘会上,一位决策者向公司的AI知识助手提问:“我们所有子公司中,上一财年资本支出最高的是哪家?具体金额是多少?” AI助手或许能流畅地生成一段文本,但其内容可能只是相关报告的摘要,甚至包含错误信息。
这暴露了当前广泛应用的检索增强生成(RAG)技术在企业实际应用中的一个核心困境。当问题从简单的“信息查找”转向复杂的“分析推理”时,传统RAG开始显现其局限性。
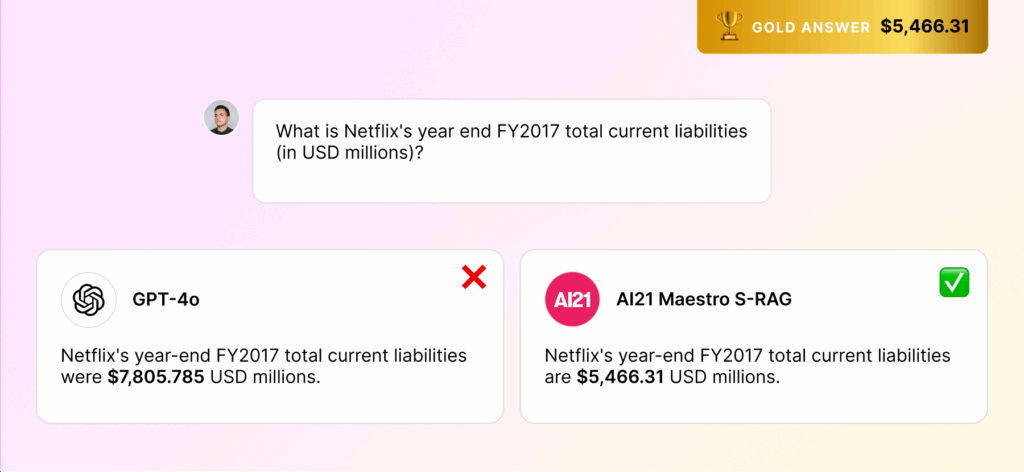 图1:一个典型的金融查询场景,传统RAG难以直接从文本中计算出精确答案,而S-RAG通过SQL查询可直接获得结果。
图1:一个典型的金融查询场景,传统RAG难以直接从文本中计算出精确答案,而S-RAG通过SQL查询可直接获得结果。
这种局限性主要源于其底层机制,并体现在三个关键方面:
- 1.无法有效处理聚合问题:传统RAG通过向量相似度检索文本片段。但面对“计算所有项目的平均成本”或“找出销售额最高的五个区域”这类需要跨多个文档进行数学运算的查询时,它无能为力。大语言模型(LLM)本身并不擅长在有限的上下文中对零散的文本进行精确计算。
- 2.难以保证结果的完整性:在合规、审计等领域,“列出所有符合特定条件的合同”是常见需求,答案的完整性至关重要。基于相似度检索的RAG本质上是概率性的,旨在寻找“最相关”而非“所有相关”的文档。这种机制无法保证100%的召回率,任何遗漏都可能带来风险。
- 3.在密集信息语料库中表现不佳:在金融财报、法律文书、技术手册等内容中,文档的格式、术语和行文风格高度统一。这使得向量模型难以区分细微但关键的差异,导致检索结果充斥着大量语义相近但信息无效的“噪音”,干扰LLM生成准确答案。
S-RAG:用数据库思维重塑AI问答
为了克服这些瓶颈,一种名为Structured RAG (S-RAG)的新范式应运而生。其核心思想是回归经典的数据处理原则:在进行复杂查询之前,先将非结构化信息转化为结构化数据。
这个过程主要分为两个阶段:离线的信息摄取和在线的查询推理。
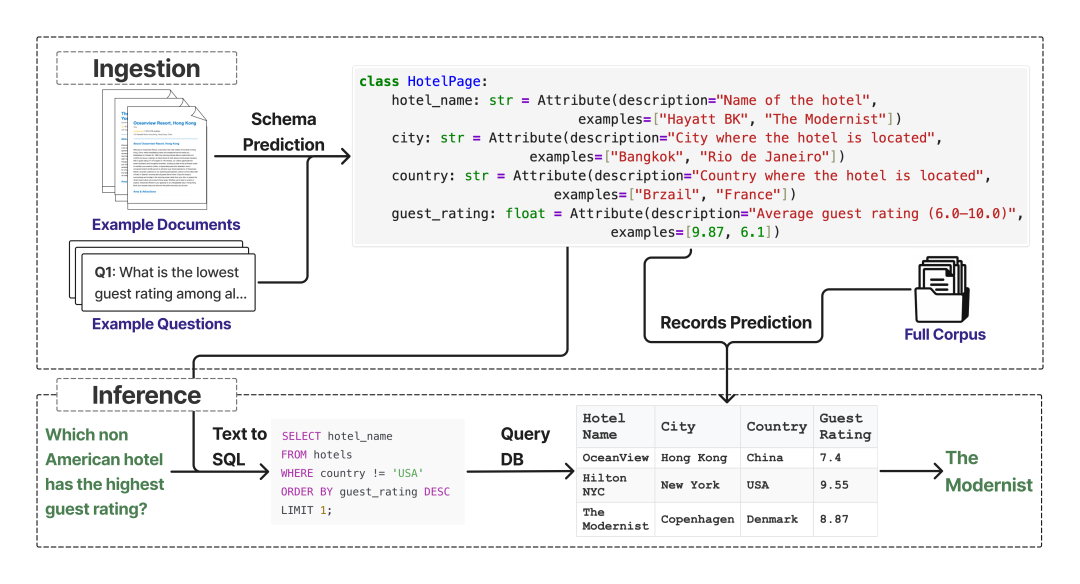 图2:S-RAG系统工作流程,分为离线摄取(上)和在线推理(下)两个阶段。
图2:S-RAG系统工作流程,分为离线摄取(上)和在线推理(下)两个阶段。
第一步:离线摄取 (Ingestion) – 构建结构化知识库
这一阶段在后台自动完成,旨在将原始文档转化为可供精确查询的数据库。
- •模式预测 (Schema Prediction):系统首先分析少量样本文档和代表性问题,利用LLM的理解能力,智能推断出文档集共同的数据“模式”(Schema)。例如,对于一系列财报,系统能自动识别出“公司名”、“财年”、“总收入”等关键字段及其数据类型。
- •记录预测 (Record Prediction):定义好模式后,S-RAG会遍历整个文档库,从每份文档中精确抽取出对应模式的数值。同时,它会进行关键的标准化处理,例如,将文本中的“一百万”、“1M”和“1,000,000”都统一为数字
1000000。这些规整、标准化的信息最终被存入一个结构化数据库表中。
图3:S-RAG概念示例,将一组非结构化的简历(Corpus)根据预定义模式(Schema)转换为结构化的记录(Record)。
第二步:在线推理 (Inference) – 从自然语言到精确查询
当用户提出问题时,S-RAG的运行机制与传统RAG截然不同。
- • 它不再进行模糊的语义搜索,而是将用户的自然语言问题,精准地翻译成一条数据库查询语句(如SQL)。
- • 数据库执行这条确定性的指令后,返回一个或一组精确的数据。最后,LLM将这些数据结果组织成通顺、自然的语言呈现给用户。整个过程逻辑清晰、结果精确且可验证。
实证检验:S-RAG的性能表现
为了客观评估S-RAG的有效性,研究人员构建了两个新的数据集(Hotels、World Cup)并结合已有的金融分析基准(FinanceBench)进行了全面测试。
- •数据集概况
为了更好地模拟需要多文档聚合的真实场景,研究人员创建了两个新数据集。Hotels数据集完全由AI生成,以确保模型无法利用先验知识;World Cup数据集则基于真实的维基百科页面。
| Dataset | #Docs | #Questions | Doc Length (avg) | Answer Length (avg) | Requires Aggregation |
| — | — | — | — | — | — |
| FinanceBench | 10,798 | 1,023 | 25,603 | 114 | Partial |
| World Cup | 22 | 83 | 2,752 | 19 | Yes |
| Hotels | 350 | 193 | 1,180 | 12 | Yes |
-
表1: 实验使用的数据集统计与特性。
-
•基线模型的挑战
在评估前,研究人员测试了强大的LLM(如GPT-o3)在没有外部知识(Zero-shot)的情况下回答这些问题的能力。结果显示,模型对于Hotels这类全新数据几乎无法回答,而对World Cup这类基于公共知识的数据则表现较好。这证明了对于私有、非公开数据,一个强大的RAG系统是不可或缺的。
| Dataset | Answer Comparison | Answer Recall |
| — | — | — |
| FinanceBench-Agg | 0.08 | 0.09 |
| World Cup | 0.71 | 0.72 |
| Hotels | 0.00 | 0.01 |
-
表2: LLM在无外部知识(Zero-shot)情况下的表现。
-
•核心性能对比
在聚合类问题的基准测试中,S-RAG相较于传统方法表现出明显优势。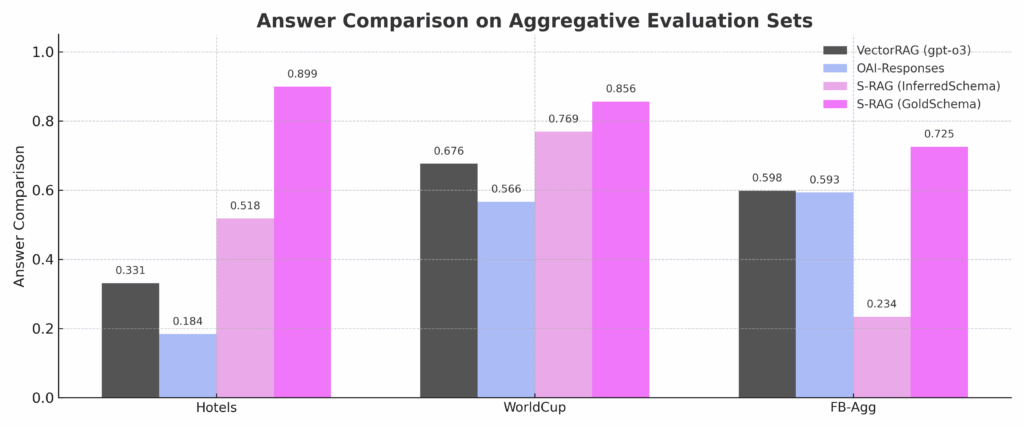
图4:在聚合问题基准测试中,S-RAG(Structured RAG)的准确率显著高于基于向量的RAG(Embedder-based RAG)和OpenAI Responses API。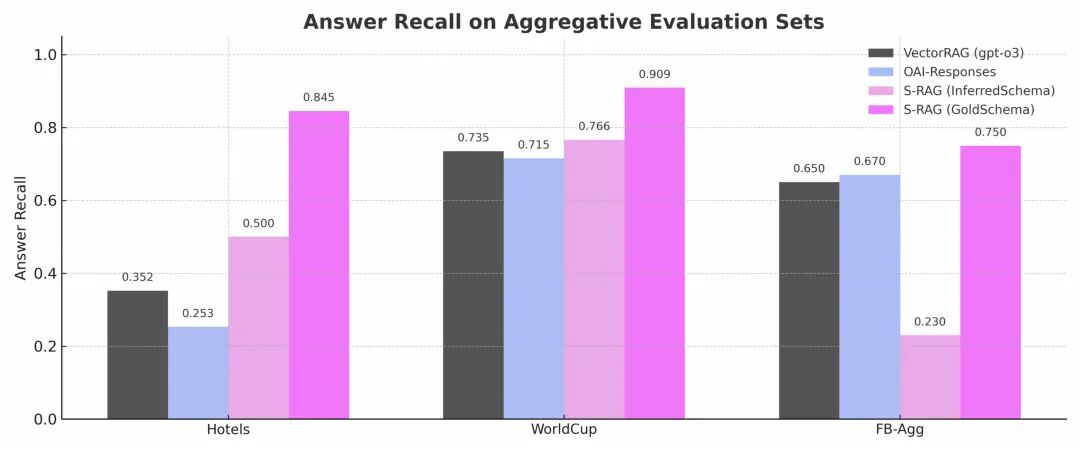
- 图5:对于要求完整性的穷举类问题,S-RAG的召回率(Answer Recall)接近完美(1.0),远超其他方法。
下表提供了更详细的数值结果,展示了不同S-RAG变体(使用黄金标准模式或自动推断模式)与基线系统的对比。即使是模式需要自动推断的S-RAG,在Hotels和World Cup上也表现出色。
| System | Metric | FinanceBench-Agg | World Cup | Hotels |
| — | — | — | — | — |
| S-RAG-GoldSchema | AnswerComparison | 0.86 | 0.95 | 0.94 |
| | AnswerRecall | 0.88 | 0.97 | 0.96 |
| S-RAG-InferredSchema | AnswerComparison | 0.08 | 0.89 | 0.90 |
| | AnswerRecall | 0.10 | 0.92 | 0.92 |
| OpenAI-Responses | AnswerComparison | 0.60 | 0.81 | 0.35 |
| | AnswerRecall | 0.61 | 0.84 | 0.36 |
| VectorRAG | AnswerComparison | 0.62 | 0.80 | 0.44 |
| | AnswerRecall | 0.67 | 0.81 | 0.45 |
| FullCorpus | AnswerComparison | 0.08 | 0.77 | 0.70 |
| | AnswerRecall | 0.11 | 0.81 | 0.73 |
-
表3: 各系统在聚合问题评估集上的详细结果。
-
•一个直观的例子
为了更具体地感受差异,请看下面这个来自World Cup数据集的例子。
| | |
| — | — |
| Question | What is the average number of total goals scored across all World Cups in this dataset? |
| Expected Answer | The average number of total goals scored across all World Cups in this dataset is 119.59. |
| VectorRAG | …Based on the context, the total number of goals in the 1998 World Cup was 171. In the 2002 World Cup, it was 161… It seems I don’t have enough data to calculate the average… |
| FullCorpus | I will calculate the average number of goals. The total goals are 70 + 84 + … + 145 = 1188. There are 10 tournaments… The average is 118.8. |
| S-RAG | The average number of total goals scored across all World Cups in this dataset is 119.59. |
表4: 不同系统对“世界杯平均总进球数”这一问题的回答示例。
可以看到,传统RAG由于上下文不完整,无法给出正确答案,而S-RAG则直接、准确地完成了计算。
演进与启示:混合模式与深层思考
S-RAG并非要完全取代传统RAG,二者结合的“混合模式”展现了更广阔的应用前景。
混合检索:精确性与灵活性的结合
对于同时包含结构化和非结构化查询要素的复杂问题,可以采用混合检索策略:
- 1.精确筛选:首先,利用S-RAG的结构化查询能力,从海量文档中迅速定位到一小批高度相关的文档。
- 2.深度理解:然后,在这个高质量、小范围的文档集上,再使用传统向量RAG进行深度的语义理解和答案生成。
这种“先精后广”的策略,兼顾了准确性与灵活性。在包含各类问题的完整FinanceBench测试集上,混合模式的S-RAG表现优于纯粹的向量RAG系统。
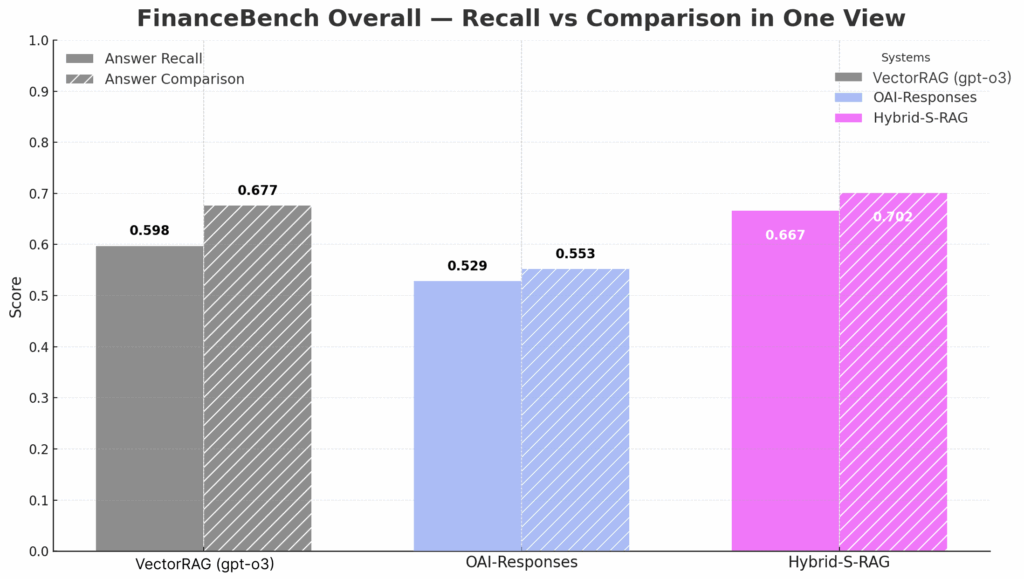 图6:在完整的FinanceBench基准测试中,结合了结构化和向量检索的混合RAG(Maestro Hybrid RAG)表现最佳。
图6:在完整的FinanceBench基准测试中,结合了结构化和向量检索的混合RAG(Maestro Hybrid RAG)表现最佳。
| System | Answer Comparison | Answer Recall |
| — | — | — |
| HYBRID-S-RAG | 0.78 | 0.80 |
| OpenAI-Responses | 0.67 | 0.68 |
| VectorRAG | 0.64 | 0.69 |
表5: 在完整的FinanceBench评估集上的性能对比。
S-RAG带来的深层启示
S-RAG的成功,也为我们思考AI发展路径提供了两个重要启示:
- 1.新旧技术的融合:LLM的强大能力并不意味着要抛弃所有传统技术。S-RAG证明,将LLM的自然语言处理能力与经过数十年验证的数据库技术相结合,可以创造出远超单一技术范式的强大系统。AI的进步在于智慧的融合,而非颠覆一切。
- 2.重塑RAG的核心瓶颈:过去,许多研究聚焦于优化LLM的“生成(Generation)”环节。S-RAG则指出,对于分析类任务,真正的瓶颈在于“检索(Retrieval)”。通过将检索从“寻找相关文本”转变为“执行精确计算”,从根本上提升了系统的可靠性和确定性。
结论:迈向可信赖的企业智能
S-RAG的出现,标志着企业AI正从一个提供文本摘要和简单问答的辅助工具,向一个能够支撑严肃决策、可信赖的分析引擎进化。
- •可信赖与可审计:由于其核心推理基于可验证的数据库查询,S-RAG的输出不再是黑箱,为金融、法务等高风险行业的AI应用提供了信任基石。
- •规模化应用潜力:面对海量、复杂的专业语料库,S-RAG的自动化模式构建和数据提取能力,展现了强大的规模化应用潜力。
最终,通过将企业内部庞大、混乱的非结构化数据,转化为结构清晰、随时待命的决策引擎,S-RAG为企业智能化转型铺平了道路。这不仅是一次技术的革新,更是一场关于企业如何利用AI创造核心价值的深刻变革。
 图7: 为测试S-RAG而创建的Hotels数据集中的一个文档页面示例。
图7: 为测试S-RAG而创建的Hotels数据集中的一个文档页面示例。





