DeepSeek,这家中国人工智能初创公司,以其惊人的崛起速度震惊了科技界。在 App Store 上超越 ChatGPT 后,DeepSeek 引发了市场狂潮。然而,随之而来的并非全是赞誉。DeepSeek 的网站遭到攻击,迫使公司暂停注册,一些质疑者甚至怀疑该公司是否使用了受出口限制的英伟达 H100 芯片,而不是其声称的 H800 芯片,引发了关于合规性和成本效益的担忧。
然而,加州大学伯克利分校的研究人员的一项突破,正在挑战这些假设。由博士生潘嘉怡领导的团队成功地以不到 30 美元(约合 200 元人民币)的成本复制了 DeepSeek R1-Zero 的核心功能,这甚至比一次夜宵的费用还要低。他们的研究可能会开启小型模型强化学习革命的新时代。
他们的发现表明,复杂的 AI 推理并不一定需要高昂的成本,这可能会改变 AI 研究与可及性之间的平衡。
伯克利研究人员以 30 美元复制 DeepSeek R1,挑战 H100 叙事
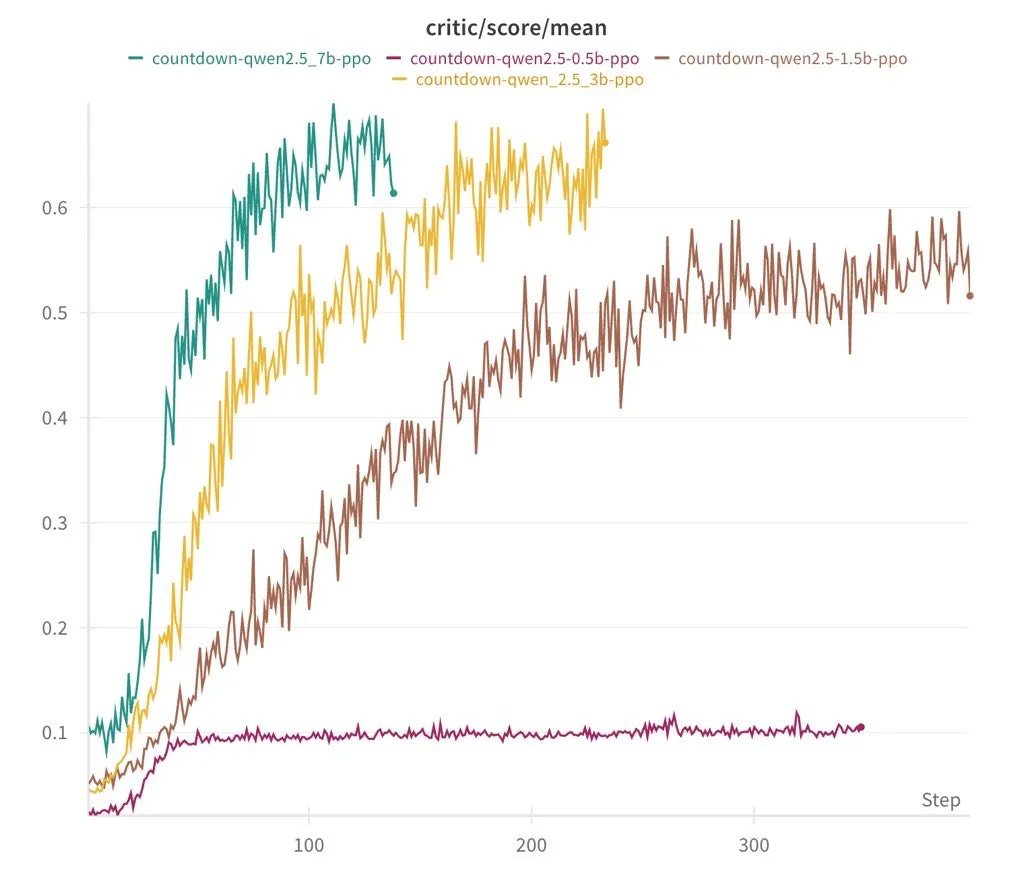
伯克利团队表示,他们使用 DeepSeek 的一个拥有 30 亿参数的语言模型,通过强化学习对其进行训练,使其具备自我验证和搜索能力。他们的目标是通过算术运算来解决达到目标数字的挑战,他们成功地以 30 美元完成了实验。相比之下,OpenAI 的 o1 API 每百万输入词元收费 15 美元,是 DeepSeek-R1 的 27 倍以上,DeepSeek-R1 每百万词元仅需 0.55 美元。潘嘉怡认为,这个项目是降低强化学习扩展研究门槛的一步,尤其是在其成本极低的情况下。
然而,并非所有人都认同。机器学习专家内森·兰伯特质疑 DeepSeek 声称其 6710 亿参数模型的训练成本仅为 500 万美元。他认为,这个数字可能排除了研究人员、基础设施和电力等关键支出。他估计,DeepSeek AI 的年度运营成本在 5 亿到 10 亿美元之间。尽管如此,这项成就仍然引人注目,尤其是考虑到美国顶尖的 AI 公司每年都在 AI 领域投入 100 亿美元。
根据潘嘉怡在 Nitter 上的帖子,该团队成功地使用一个拥有 30 亿参数的小型语言模型复制了 DeepSeek R1-Zero。在 Countdown 游戏中运行强化学习,该模型开发了自我验证和搜索策略,这是高级 AI 系统的关键能力。
他们的工作的主要收获:
- 他们成功地以不到 30 美元的价格复制了 DeepSeek R1-Zero 的方法。
- 他们拥有 15 亿参数的模型展示了先进的推理能力。
- 性能与更大的 AI 系统相当。
强化学习突破
研究人员从一个基础语言模型、一个结构化提示和一个真实奖励开始。然后,他们通过 **Countdown** 引入强化学习,这是一款改编自英国电视节目的逻辑游戏。在这个挑战中,玩家必须使用算术运算来达到目标数字,这种设置鼓励 AI 模型改进其推理能力。
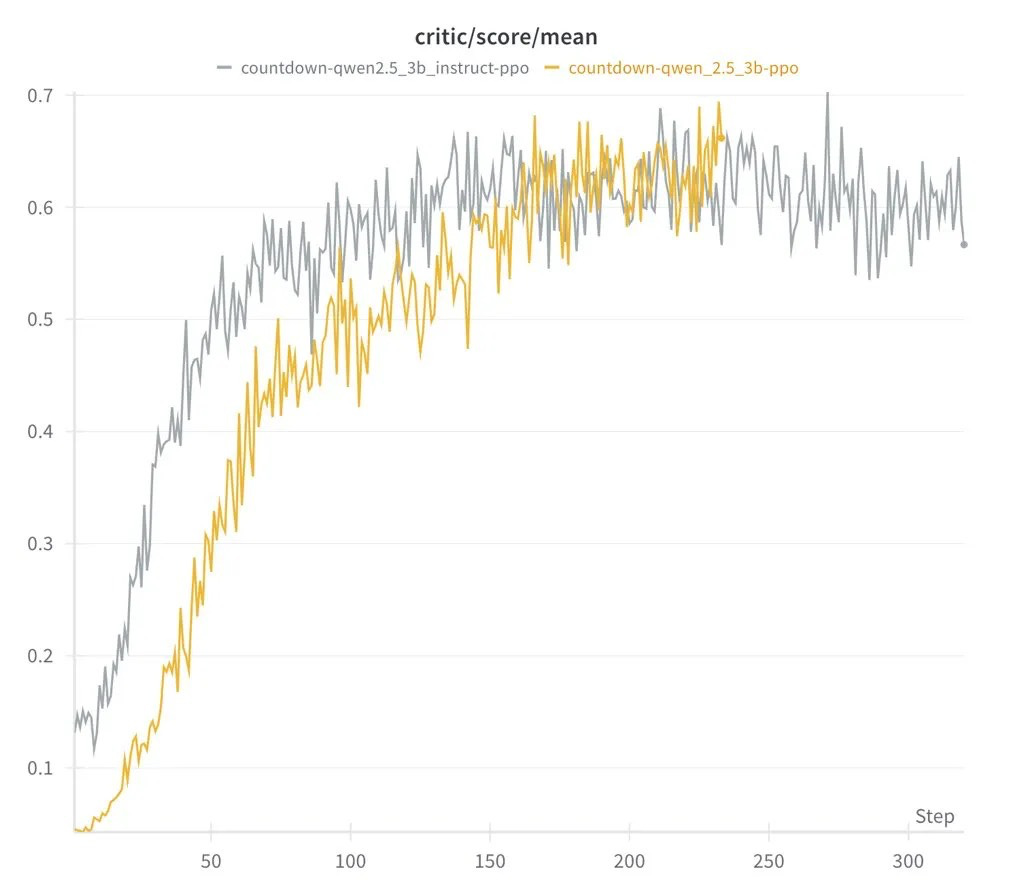
最初,AI 生成了随机答案。通过反复试验,它开始验证自己的答案,并在每次迭代中调整自己的方法,这与人类解决问题的方式类似。即使是最小的 5 亿参数模型也只能做出简单的猜测,但一旦扩展到 15 亿参数及以上,AI 就开始表现出更高级的推理能力。
“我们在 CountDown 游戏中复制了 DeepSeek R1-Zero,它真的有效。通过 RL,3B 基础 LM 自行开发了自我验证和搜索能力。你可以以不到 30 美元的价格体验这种顿悟时刻。”
https://github.com/Jiayi-Pan/TinyZero
“以下是我们学到的东西,”潘嘉怡在 Nitter 上的一篇帖子中说。

令人惊讶的发现
最有趣的发现之一是,不同的任务如何导致模型开发出不同的解决问题技巧。在 Countdown 中,它完善了其搜索和验证策略,学会了迭代并改进其答案。在解决乘法问题时,它应用了分配律,将数字分解成更小的部分,就像人类在心算复杂计算时所做的那样。
另一个值得注意的发现是,强化学习算法的选择——无论是 PPO、GRPO 还是 PRIME——对整体性能的影响很小。结果在不同的方法中是一致的,这表明结构化学习和模型规模在塑造 AI 能力方面比所使用的特定算法起着更大的作用。这挑战了复杂 AI 需要大量计算资源的观点,证明了复杂的推理可以从高效的训练技术和结构良好的模型中产生。
这项研究的一个关键收获是,模型如何根据手头的任务调整其解决问题技巧。
通过特定任务学习实现更智能的 AI
最有趣的收获之一是 AI 如何适应不同的挑战。对于 Countdown 游戏,该模型学习了搜索和自我验证技巧。当用乘法问题进行测试时,它采用了不同的方法——使用分配律将计算分解成更小的部分,然后再一步一步地解决它们。
AI 并没有盲目猜测,而是通过多次迭代完善了其方法,验证并修改自己的答案,直到找到正确的解决方案。这表明模型可以根据任务发展专门的技能,而不是依赖于一种通用的推理方法。
AI 可及性的转变
由于整个项目的成本不到 30 美元,并且代码在 GitHub 上公开可用,这项研究使更多开发者和研究人员能够接触到先进的 AI。它挑战了突破性进展需要数十亿美元预算的观点,强化了智能工程往往可以超越蛮力支出的理念。
这项工作反映了强化学习领域领军人物理查德·萨顿长期倡导的愿景,他认为简单的学习框架可以产生强大的结果。伯克利团队的发现表明他是正确的——复杂的 AI 能力并不一定需要大规模计算,只需要合适的训练环境。