

有人曾对使用ChatGPT审查第三季度业绩的结果表达失望,认为这并非真正的人工智能,而仅仅是一个搜索和总结工具。这种看法反映了许多人对AI,尤其是大型语言模型(LLMs)的普遍误解。
“前些天用ChatGPT审查第三季度业绩,结果令我大失所望。这根本不是人工智能——它不过是一个搜索和总结工具而已。”

人们常常谈论人工智能,脑海中浮现的却是90年代科幻电影中那种超凡的智能体。很容易让人联想到《终结者》中的天网(Skynet)或是《沙丘》中反乌托邦式的AI。通常与AI相关的话题插图,例如机器人、仿生人以及能将我们带往未来的星际传送门,都进一步误导了人们对AI的理解。

上图展示的是Unsplash上搜索“AI”的部分热门结果;从左到右依次为:1) julien Tromeur在Unsplash上的照片, 2) Luke Jones在Unsplash上的照片, 3) Xu Haiwei在Unsplash上的照片
然而,无论好坏,当前AI系统的运作方式与人类智能有着根本性的不同——至少目前是这样。现阶段,并不存在一个无所不能的超级智能体,能够解决人类所有看似无解的难题。因此,理解当前的AI模型究竟是什么、能做什么(和不能做什么)至关重要。只有这样,我们才能合理管理预期,并充分利用这项强大的新技术。
演绎式思维与归纳式思维
为了更好地理解当前AI的现状及其能力与局限,我们首先需要区分演绎式思维和归纳式思维。
心理学家丹尼尔·卡尼曼(Daniel Kahneman)毕生致力于研究人类思维如何运作,如何形成结论、做出决策,进而影响我们的行动和行为。这项开创性的研究最终为他赢得了诺贝尔经济学奖。他的工作成果在《思考,快与慢》(Thinking, Fast and Slow)一书中为普通读者做了精彩的总结,书中他描述了人类思维的两种模式:
- 系统1:快速、直观、自动化,本质上是无意识的。
- 系统2:缓慢、深思熟虑、费力,需要有意识的努力。
从演化角度看,人类倾向于使用系统1,因为它能节省时间和精力——就像生活在自动驾驶模式下,无需过多思考。然而,系统1的高效性往往伴随着较低的准确性,从而导致错误。
类似地,归纳式推理与卡尼曼的系统1思维模式紧密相关。它从具体的观察出发,得出普遍性的结论。这种思维方式是基于模式的,因此具有随机性。换句话说,其结论总是带有一定程度的不确定性,即使人们并未有意识地意识到这一点。
例如:
模式:在人类的经验中,太阳每天都会升起。
结论:因此,太阳明天也会升起。
可以想见,这种思维方式容易产生偏见和错误,因为它从有限的数据中进行概括。也就是说,太阳明天很可能会升起,因为在人类的生命中它每天都升起了,但这并非必然。
要得出这个结论,人们默默地假设“所有的日子都会遵循我们所经历的模式”,而这可能并非总是真实的。换句话说,人们隐含地假设在小样本中观察到的模式将适用于所有情况。
正是这种为得出结论而作出的无声假设,使得归纳式推理得出的结果高度合理,但永远无法确定。这类似于用几个数据点来拟合一个函数,我们可能会假设其潜在的关系,但永远无法确定,出错的可能性总是存在的。我们构建了一个关于观察到的现象的合理模型——然后只希望它是一个好模型。
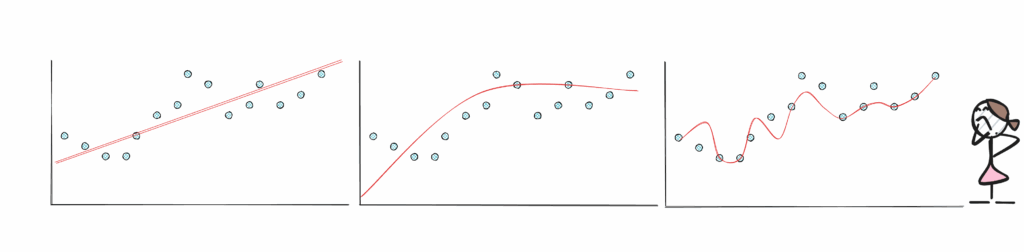
换句话说,不同的人在不同数据或不同条件下使用归纳法时,会产生不同的结果。
另一方面,演绎式推理从一般性原则出发,得出具体结论——这本质上是卡尼曼的系统2思维。它是基于规则的、确定性的、逻辑性的,遵循“如果A,那么B必然成立”的结构。
例如:
前提1:所有人都会死亡。
前提2:苏格拉底是人。
结论:因此,苏格拉底会死亡。
这种思维方式较少出错,因为推理的每一步都是确定性的。没有无声的假设;由于前提是真实的,结论必然是真实的。
回到函数拟合的类比,我们可以将演绎视为逆向过程:给定函数,计算一个数据点。由于我们知道函数,我们就能确定地计算出数据点,并且不像多个曲线可能以不同程度拟合相同的数据点那样,对于这个数据点,将只有一个确定的正确答案。最重要的是,演绎式推理具有一致性和鲁棒性。我们可以对函数的某个特定点进行百万次重新计算,结果总是完全相同。
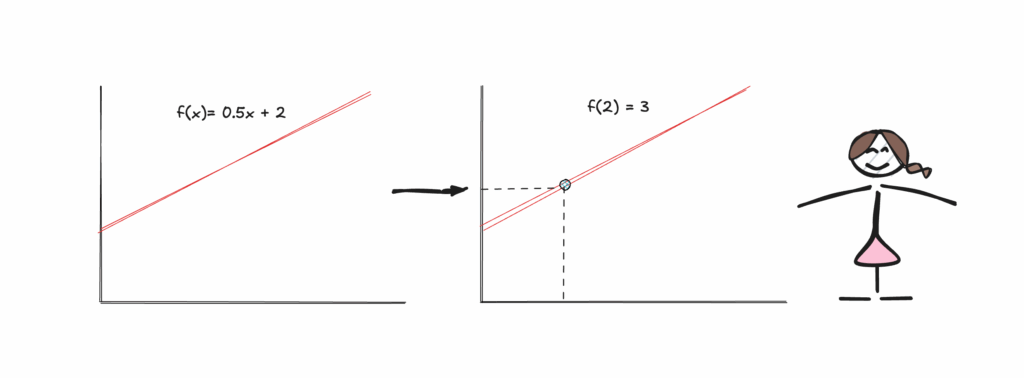
显然,即使使用演绎式推理,人类也可能犯错。例如,我们可能会搞错特定函数值的计算,从而得出错误的结果。但这只是一个随机误差。相反,归纳式推理中的误差是系统性的。推理过程本身就容易出错,因为我们在没有完全了解这些无声假设真实程度的情况下就将它们纳入了考量。
那么,大型语言模型是如何运作的?
人们,尤其是那些没有技术或计算机科学背景的人,很容易将当今的AI模型想象成一种外星的、神一般的智能,能够为人类的所有问题提供智慧的答案。然而,这并非(尚未)是实际情况。当今的AI模型,无论多么令人印象深刻和先进,仍然受限于其运作的原则。
大型语言模型(LLMs)并不像人类那样“思考”或“理解”。相反,它们依赖于训练数据中的模式,这与卡尼曼的系统1或归纳式推理非常相似。简而言之,它们的工作原理是预测给定输入之后最可能出现的下一个词。
可以将LLM想象成一个非常勤奋的学生,他记住了大量的文本,并学会了复现那些听起来正确,但未必理解其正确原因的模式。大多数情况下,这种方法是有效的,因为听起来正确的句子更有可能确实是正确的。这意味着这些模型能够生成质量令人印象深刻的类人文本和语音,听起来就像一个非常聪明的人。然而,生成类人文本和产生听起来正确的论证和结论,并不能保证它们确实是正确的。即使LLM生成的内容听起来像是演绎式推理,它也不是。通过观察ChatGPT等AI工具偶尔产生的荒谬内容,人们可以轻易地发现这一点。
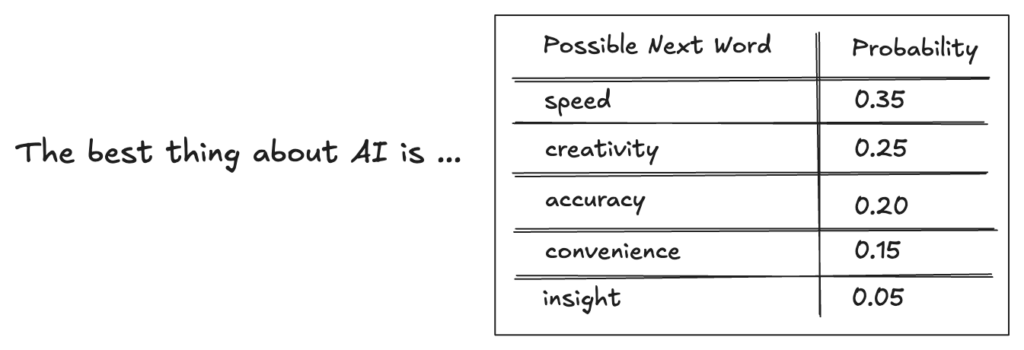
同样重要的是要理解LLM是如何获得这些最有可能的词的。天真地想,人们可能会认为这些模型只是计算现有文本中词语的频率,然后以某种方式重现这些频率来生成新文本。但事实并非如此。英语中大约有50,000个常用词,这导致了实际上无限可能的词语组合。例如,即使是一个由10个词组成的短句,其组合数也将达到50,000的10次方,这是一个天文数字。另一方面,现有书籍和互联网中的所有英文文本加起来只有几千亿个词(大约10的12次方)。因此,现有的文本甚至不足以覆盖所有可能的短语,这种方法无法生成文本。
相反,LLM利用从现有文本构建的统计模型来估计可能从未出现过的词语和短语的概率。然而,就像任何现实模型一样,这是一种简化的近似,从而导致AI犯错或编造信息。
关于“思维链”又如何?
那么,“模型正在思考”或“思维链(CoT)推理”又是什么意思呢?如果LLMs不能像人类一样真正思考,这些花哨的术语意味着什么?这仅仅是营销手段吗?嗯,有点像,但又不完全是。
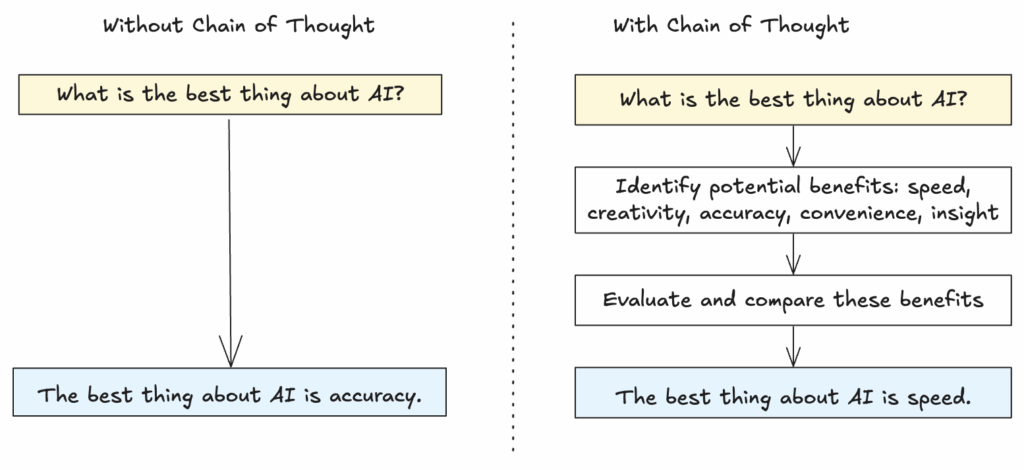
思维链(CoT)主要是一种提示技术,通过将问题分解成更小的、逐步的推理序列,使LLM能够回答问题。通过这种方式,模型不再一步到位地对用户问题进行一个大的假设,从而降低了产生错误答案的风险,而是进行多个生成步骤,具有更高的置信度。本质上,用户通过将初始问题分解为多个提示,然后LLM逐一回答,从而“引导”LLM。例如,一个非常简单的CoT提示形式可以通过在提示末尾添加“让我们一步一步地思考”来实现。
更进一步地,一些具有“长思考”能力的模型,无需用户将初始问题分解为更小的问题,它们可以自行完成这个过程。具体来说,这类推理模型可以将用户的查询分解为一系列逐步的、更小的查询,从而产生更好的答案。CoT是AI领域最大的进展之一,它使模型能够有效处理复杂的推理任务。OpenAI的o1模型是展示CoT推理能力的首个重要案例。
核心观点
理解支撑当今AI模型运作的底层原理至关重要,这有助于对它们的能与不能有现实的预期,并优化其使用。神经网络和AI模型本质上基于归纳式推理运作,即使它们很多时候听起来像是执行演绎。即使是像思维链推理这样的技术,虽然能产生令人印象深刻的结果,但其根本仍是归纳法,并且仍然可能产生听起来正确但实际上并非如此的信息。




