

光学字符识别(OCR)模型正日益受到重视。在Hugging Face等平台上,不断涌现出新的开源模型,它们刷新了以往的基准测试记录,提供了更强大、更智能、更轻量化的解决方案。
过去,上传PDF文件往往只能得到充满问题的纯文本。如今,情况已彻底改变。我们拥有了能够理解文档、表格、图表、章节和多种语言的AI模型,它们可以将这些内容转换为高度精确的Markdown格式文本,从而创建出文本的真正一比一数字副本。
本文将深入评测七款顶尖的OCR模型,它们都能在本地顺畅运行,帮你将图像、PDF甚至照片完美地解析为数字副本。
#1. olmOCR 2 7B 1025
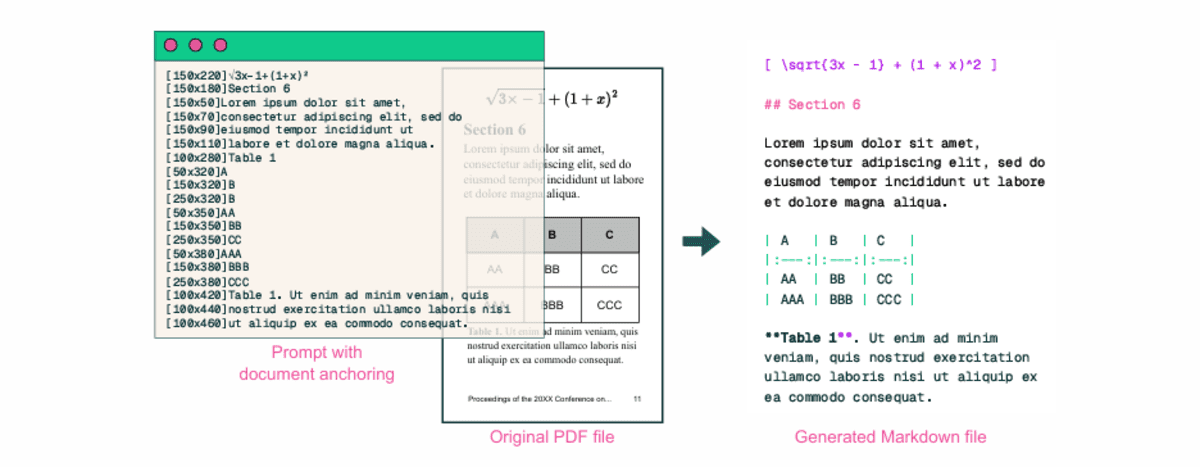
olmOCR-2-7B-1025 是一款专为文档光学字符识别优化的视觉语言模型。
该模型由艾伦人工智能研究所发布,基于Qwen2.5-VL-7B-Instruct微调而来,使用了olmOCR-mix-1025数据集,并进一步通过GRPO强化学习训练进行了增强。
该模型在olmOCR-bench评估中获得了82.4的综合得分,在处理数学公式、表格和复杂文档布局等具有挑战性的OCR任务上表现出色。
它专为高效的大规模处理而设计,与olmOCR工具包配合使用效果最佳,该工具包提供了自动化渲染、旋转和重试功能,可处理数百万份文档。
以下是其五大核心特性:
- 自适应内容感知处理:自动分类文档内容类型(包括表格、图表和数学公式),并应用专门的OCR策略以提高准确性。
- 强化学习优化:GRPO强化学习训练专门提升了在数学公式、表格和其他困难OCR案例上的准确性。
- 卓越的基准测试性能:在olmOCR-bench上获得82.4的综合得分,在arXiv文档、老旧扫描件、页眉页脚和多栏布局等任务上表现强劲。
- 专业化文档处理:针对最长边为1288像素的文档图像进行了优化,需要特定的元数据提示才能获得最佳效果。
- 可扩展的工具包支持:设计用于与olmOCR工具包协同工作,支持基于VLLM的高效推理,能够处理数百万份文档。
#2. PP OCR v5 Server Det
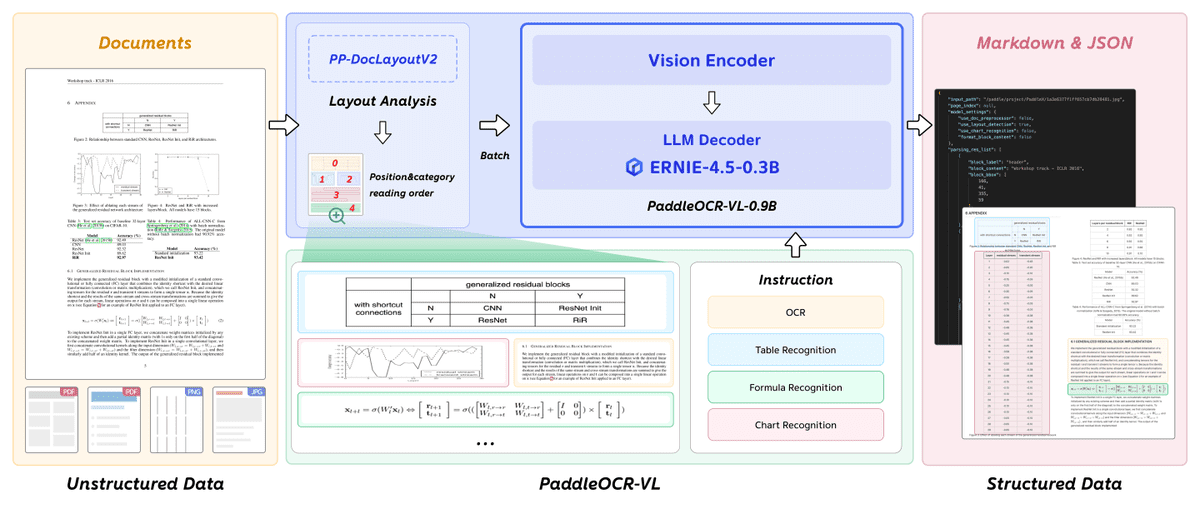
PaddleOCR VL 是一款超紧凑的视觉语言模型,专为高效的多语言文档解析而设计。
其核心组件PaddleOCR-VL-0.9B,集成了NaViT风格的动态分辨率视觉编码器与轻量级的ERNIE-4.5-0.3B语言模型,在保持最低资源消耗的同时实现了最先进的性能。
该模型支持包括中文、英文、日文、阿拉伯文、印地文和泰文在内的109种语言,擅长识别文本、表格、公式和图表等复杂文档元素。
通过在OmniDocBench和内部基准测试上的全面评估,PaddleOCR-VL展示了卓越的准确性和快速的推理速度,使其非常适合实际部署场景。
以下是其五大核心特性:
- 超紧凑的0.9B架构:结合NaViT风格动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型,实现资源高效推理,同时保持高精度。
- 最先进的文档解析能力:在OmniDocBench v1.5和v1.0的整体文档解析、文本识别、公式提取、表格理解和阅读顺序检测方面均取得领先性能。
- 广泛的多语言支持:识别109种语言,涵盖全球主要语言和多样化的文字体系,包括西里尔字母、阿拉伯文、天城文和泰文,实现真正的全球化文档处理。
- 全面的元素识别:擅长识别和提取文本、表格、数学公式和图表,包括复杂布局和具有挑战性的内容,如手写文本和历史文档。
- 灵活的部署选项:支持多种推理后端,包括原生PaddleOCR工具包、transformers库和vLLM服务器,可在不同部署场景下实现优化性能。
#3. OCRFlux 3B
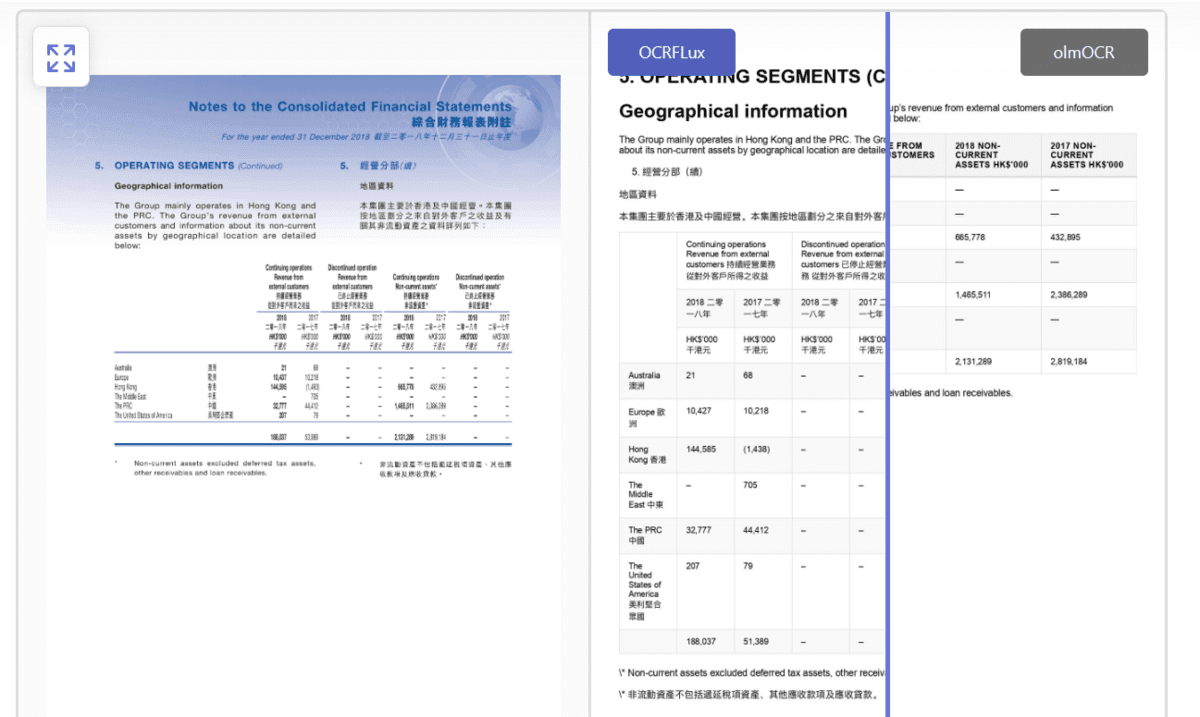
OCRFlux-3B 是一款多模态大语言模型的预览版,基于Qwen2.5-VL-3B-Instruct微调,用于将PDF和图像转换为干净、可读的Markdown文本。
该模型利用私有文档数据集和olmOCR-mix-0225数据集,实现了卓越的解析质量。
凭借其紧凑的30亿参数架构,OCRFlux-3B可以在GTX 3090等消费级硬件上高效运行,同时支持跨页表格和段落原生合并等高级功能。
该模型在综合基准测试中达到了最先进的性能,并设计为可通过OCRFlux工具包和vLLM推理支持进行可扩展部署。
以下是其五大核心特性:
- 卓越的单页解析精度:在OCRFlux-bench-single上获得0.967的编辑距离相似度,显著优于olmOCR-7B-0225-preview、Nanonets-OCR-s和MonkeyOCR。
- 原生跨页结构合并:首个原生支持检测和合并跨越多页的表格和段落的开源项目,在跨页检测上达到0.986的F1分数。
- 高效的30亿参数架构:紧凑的模型设计使其能够部署在GTX 3090 GPU上,同时通过vLLM优化的推理保持高性能,可处理数百万份文档。
- 全面的基准测试套件:提供广泛的评估框架,包括OCRFlux-bench-single和跨页基准测试,并带有手动标注的真实数据,用于可靠的性能测量。
- 可扩展的生产就绪工具包:包含Docker支持、Python API以及用于批处理的完整流水线,具有可配置的工作线程、重试和错误处理功能,适合企业部署。
#4. MiniCPM-V 4.5
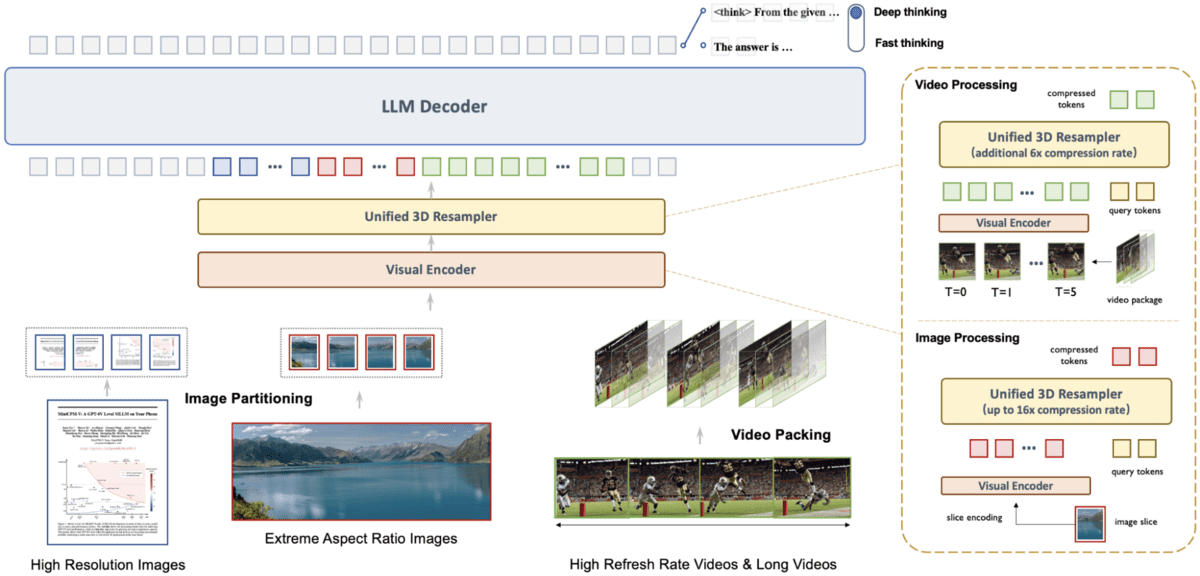
MiniCPM-V 4.5 是MiniCPM-V系列的最新模型,提供先进的光学字符识别和多模态理解能力。
该模型基于Qwen3-8B和SigLIP2-400M构建,拥有80亿参数,在移动设备上直接处理图像、文档、视频和多重图像中的文本方面表现卓越。
它在综合基准测试中取得了最先进的结果,同时为日常应用保持了实用的效率。
以下是其五大核心特性:
- 卓越的基准测试性能:在OpenCompass上获得77.0的平均分,实现了最先进的视觉语言性能,超越了GPT-4o-latest和Gemini-2.0 Pro等更大模型。
- 革命性的视频处理:使用统一的3D-Resampler进行高效视频理解,可将视频令牌压缩96倍,实现高达每秒10帧的高帧率处理。
- 灵活的推理模式:可控的混合快速和深度思考模式,可在快速响应和复杂推理之间切换。
- 先进的文本识别:强大的OCR和文档解析能力,可处理高达180万像素的高分辨率图像,在OCRBench和OmniDocBench上取得领先分数。
- 多平台支持:易于跨平台部署,支持llama.cpp和ollama,提供16种量化模型尺寸,集成SGLang和vLLM,支持微调选项,提供WebUI演示、iOS应用和在线网页演示。
#5. InternVL 2.5 4B
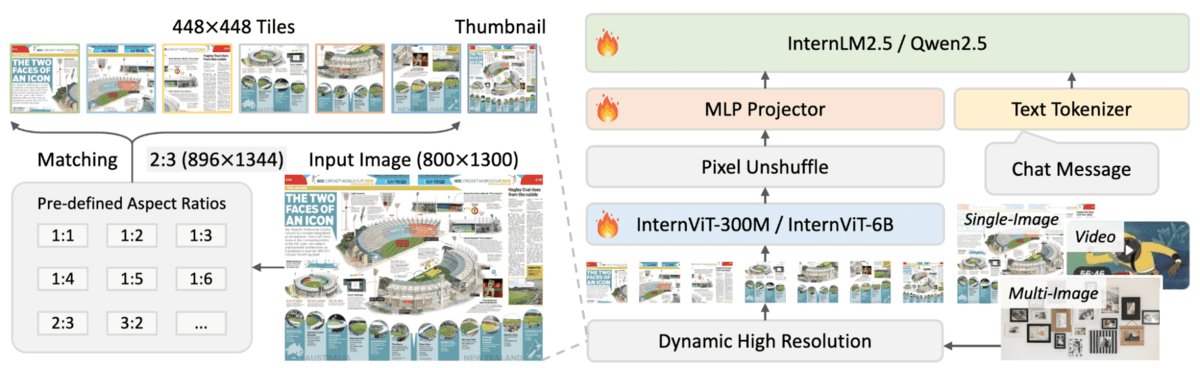
InternVL2.5-4B 是InternVL 2.5系列中的一款紧凑型多模态大语言模型,结合了3亿参数的InternViT视觉编码器和30亿参数的Qwen2.5语言模型。
该模型总计40亿参数,专为高效的光学字符识别和跨图像、文档和视频的全面多模态理解而设计。
它采用动态分辨率策略,将视觉内容处理为448×448像素的图块,同时在文本识别和推理任务上保持强劲性能,使其适合资源受限的环境。
以下是其五大核心特性:
- 动态高分辨率处理:通过将单张图像、多张图像和视频帧划分为自适应的448×448像素图块来处理,并通过像素重排操作智能减少令牌数量。
- 高效的三阶段训练:采用精心设计的流水线,包括MLP预热、针对特定领域的可选视觉编码器增量学习,以及具有严格数据质量控制的全模型指令微调。
- 渐进式扩展策略:首先使用较小的语言模型训练视觉编码器,然后再迁移到较大的语言模型,所用令牌数量不到同类模型的十分之一。
- 先进的数据质量过滤:采用全面的流水线,包括基于LLM的质量评分、重复检测和基于启发式规则的过滤,以移除低质量样本并防止模型性能下降。
- 强大的多模态性能:在OCR、文档解析、图表理解、多图像理解和视频分析方面提供有竞争力的结果,同时通过改进的数据管理保持纯粹的语言能力。
#6. Granite Vision 3.3 2b
Granite Vision 3.3 2b 是一款于2025年6月11日发布的紧凑高效视觉语言模型,专为视觉文档理解任务设计。
该开源模型基于Granite 3.1-2b-instruct语言模型和SigLIP2视觉编码器构建,能够从表格、图表、信息图、绘图和示意图中自动提取内容。
它引入了实验性功能,包括图像分割、文档标签生成和多页文档支持,同时与早期版本相比提供了增强的安全性。
以下是其五大核心特性:
- 卓越的文档理解性能:在ChartQA、DocVQA、TextVQA和OCRBench等关键基准测试中得分均有提升,优于之前的granite-vision版本。
- 增强的安全对齐:在RTVLM和VLGuard数据集上具有更高的安全分数,能更好地处理政治、种族、越狱和误导性内容。
- 实验性多页支持:经过训练,可使用文档中最多8个连续页面来处理问答任务,从而实现长上下文处理。
- 先进的文档处理功能:引入了新颖的功能,包括图像分割和文档标签生成,用于将文档解析为结构化文本格式。
- 高效的企业级设计:紧凑的20亿参数架构,针对视觉文档理解任务进行了优化,同时保持12.8万令牌的上下文长度。
#7. Trocr Large Printed
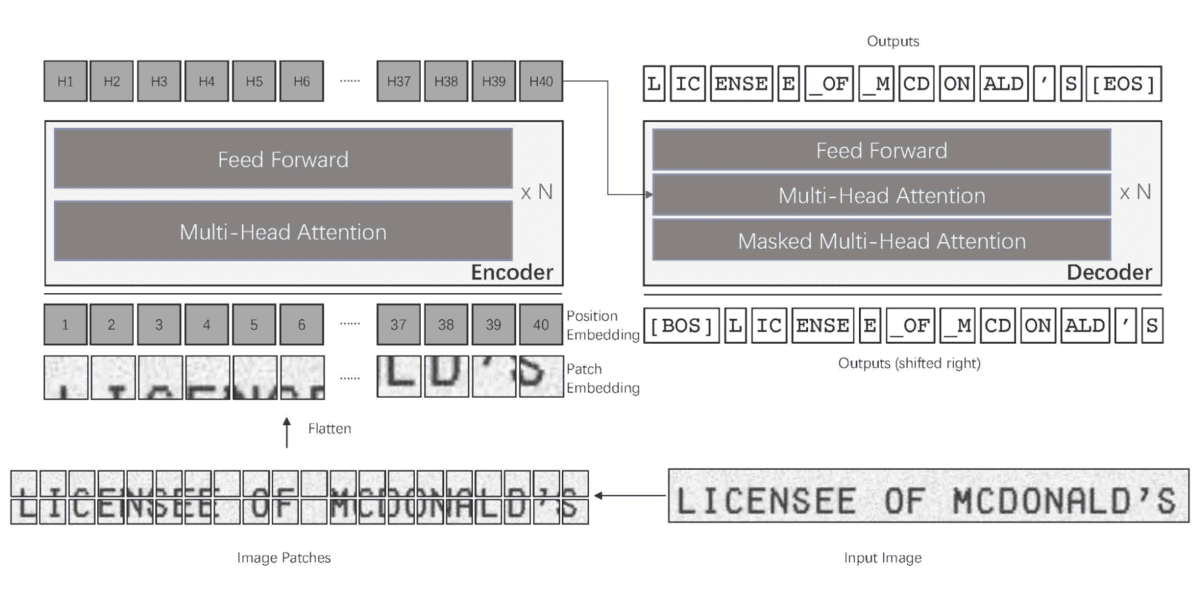
TrOCR 大型模型在SROIE上进行了微调,是一款专为从单行图像中提取文本而设计的基于Transformer的光学字符识别系统。
该模型基于论文《TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models》中介绍的架构,结合了BEiT初始化的图像Transformer编码器和RoBERTa初始化的文本Transformer解码器。
该模型将图像处理为16×16像素块的序列,并以自回归方式生成文本令牌,使其在印刷文本识别任务中特别有效。
以下是其五大核心特性:
- 基于Transformer的架构:编码器-解码器设计,包含图像Transformer编码器和文本Transformer解码器,用于端到端光学字符识别。
- 预训练组件初始化:利用BEiT权重初始化图像编码器,利用RoBERTa权重初始化文本解码器,以获得更好的性能。
- 基于图块的图像处理:将图像作为固定大小的16×16图块进行处理,并带有线性嵌入和位置嵌入。
- 自回归文本生成:解码器顺序生成文本令牌,以实现准确的字符识别。
- SROIE数据集专业化:在SROIE数据集上进行了微调,以增强印刷文本识别任务的性能。
#总结
以下对比表快速总结了领先的开源OCR和视觉语言模型,突出了它们的优势、能力和最佳使用场景。
| 模型 | 参数量 | 主要优势 | 特殊能力 | 最佳使用场景 |
| — | — | — | — | — |
| olmOCR-2-7B-1025 | 7B | 高精度文档OCR | GRPO强化学习训练,公式和表格OCR,针对约1288像素文档输入优化 | 大规模文档流水线,科学和技术PDF |
| PaddleOCR v5 / PaddleOCR-VL | 1B | 多语言解析(109种语言) | 文本、表格、公式、图表;基于NaViT的动态视觉编码器 | 全球多语言OCR,轻量高效推理 |
| OCRFlux-3B | 3B | Markdown精准解析 | 跨页表格和段落合并;针对vLLM优化 | PDF转Markdown流水线;在消费级GPU上运行良好 |
| MiniCPM-V 4.5 | 8B | 最先进的多模态OCR | 视频OCR,支持180万像素图像,快速和深度思考模式 | 移动和边缘OCR,视频理解,多模态任务 |
| InternVL 2.5-4B | 4B | 高效OCR与多模态推理 | 动态448×448分块策略;强大的文本提取 | 资源有限环境;多图像和视频OCR |
| Granite Vision 3.3 (2B) | 2B | 视觉文档理解 | 图表、表格、示意图、分割、文档标签、多页问答 | 跨表格、图表和示意图的企业文档提取 |
| TrOCR Large (Printed) | 0.6B | 清晰的印刷文本OCR | 16×16图块编码器;BEiT编码器与RoBERTa解码器 | 简单、高质量的印刷文本提取 |



