作为一名数据科学家,初次接触n8n工作流时,其便利性令人惊叹。无需阅读长达数十页的API文档,便可轻松连接各类API;通过Gmail或Google表格触发工作流,并在短短几分钟内部署出有用的应用。
然而,一个显著的局限是,n8n的云实例在原生层面并未对运行Python环境进行优化。
与许多数据科学家一样,日常数据分析工具箱主要基于NumPy和Pandas构建。
为了保持工作习惯和效率,通常会选择将复杂的计算任务“外包”给外部API,而非直接使用n8n的JavaScript代码节点。
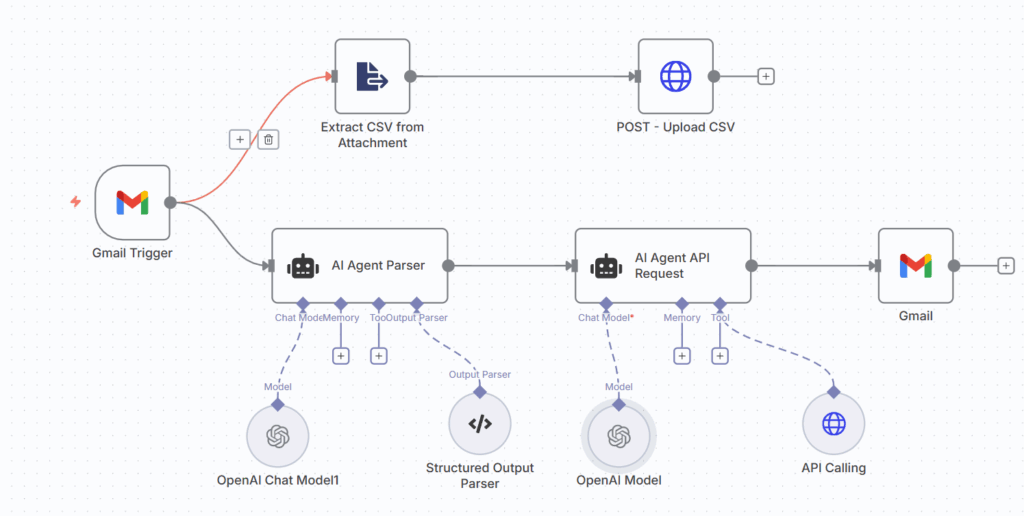
利用API函数调用进行生产计划的n8n工作流 – (图片由Samir Saci提供)
例如,这正是生产计划优化工具的运作方式,该工具通过一个包含Agent节点的工作流进行编排,该节点调用一个FastAPI微服务。
尽管这种方法有效,但有客户提出,希望在其n8n用户界面上能够完全可视化数据分析任务的每一步。
因此,需要学习足够的JavaScript知识,以便利用n8n原生代码节点执行数据处理任务。
JavaScript节点按ITEM进行销售分组的示例 – (图片由Samir Saci提供)
本文将通过在n8n代码节点中使用小的JavaScript代码片段,来实验执行日常数据分析任务。
为此次练习,将使用一个销售交易数据集,并逐步进行ABC和帕累托(Pareto)分析,这些分析在供应链管理中被广泛应用。
供应链管理中广泛使用的ABC XYZ和帕累托图表 – (图片由Samir Saci提供)
文章将提供Pandas与n8n代码节点中JavaScript的并排示例,使得将熟悉的Python数据分析步骤直接转换为自动化的n8n工作流成为可能。

JavaScript与Pandas示例对比 – (图片由Samir Saci提供)
核心思想是在云企业级n8n实例的现有能力范围内(即不使用社区节点),针对小型数据集或快速原型开发实现这些解决方案。
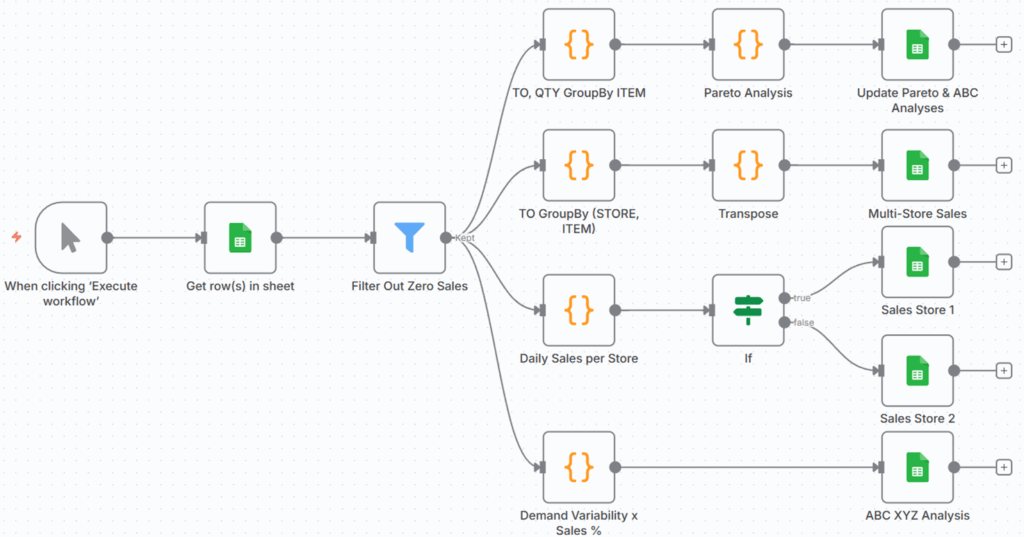
将共同构建的实验性工作流 – (图片由Samir Saci提供)
实验将以与FastAPI调用进行性能的快速比较研究结束。
读者可以利用文章中分享的Google表格和工作流模板,复现整个工作流。
现在,开始构建!
在n8n中使用JavaScript构建数据分析工作流
在开始构建节点之前,将介绍本次分析的背景。
供应链管理中的ABC和帕累托图表
在本教程中,建议构建一个简单的工作流,该工作流从Google表格中获取销售交易数据,并将其转换为全面的ABC和帕累托图表。
这将复现由LogiGreen初创公司开发的LogiGreen应用程序中的ABC和帕累托分析模块。
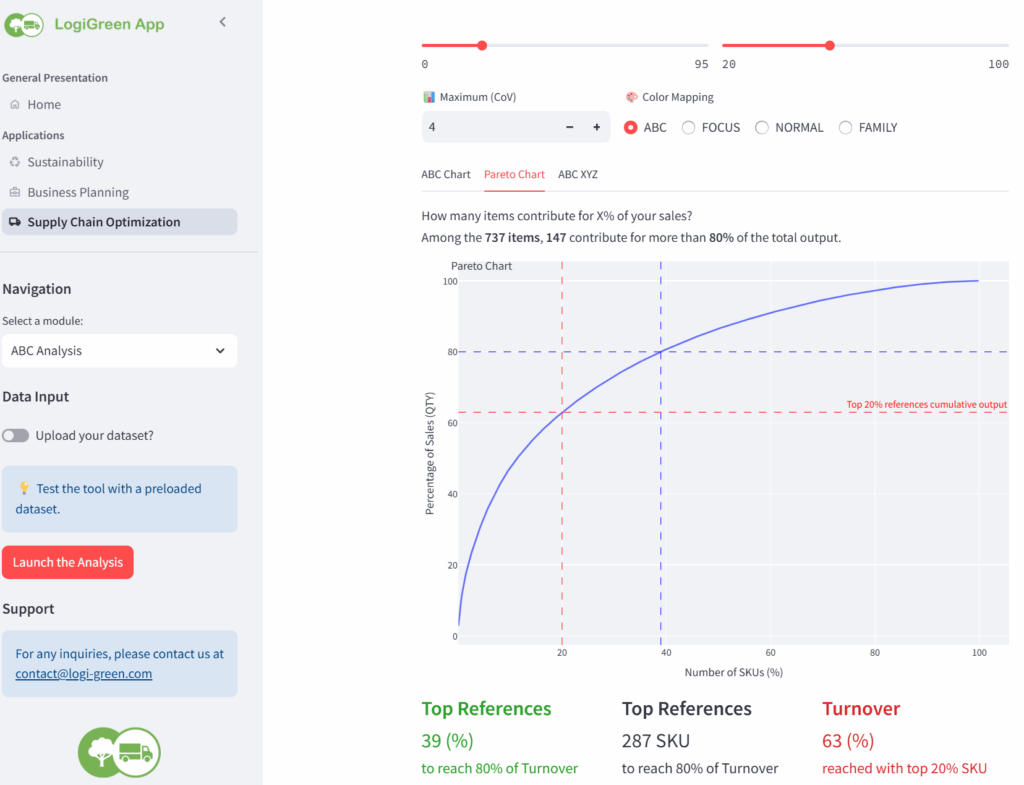
LogiGreen应用程序中的ABC分析模块 – (图片由Samir Saci提供)
目标是为超市连锁店的库存团队生成一系列可视化图表,帮助他们了解销售在各门店的分布情况。
将重点生成两个可视化图表。
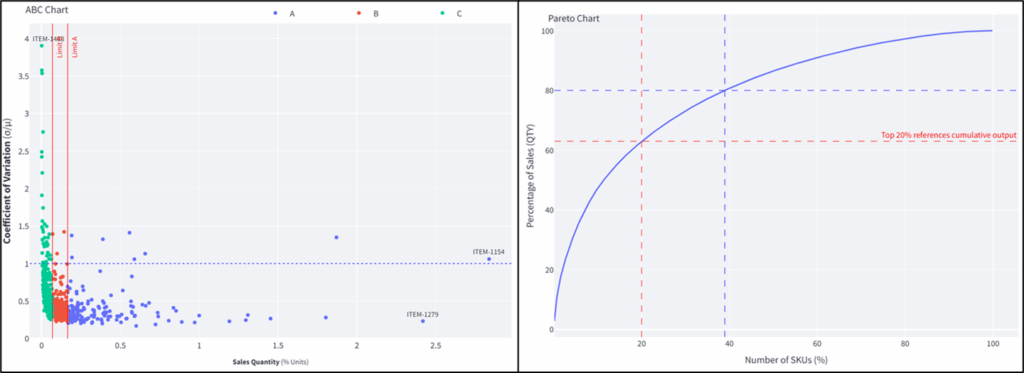
第一个图表展示了销售商品的ABC-XYZ分析:
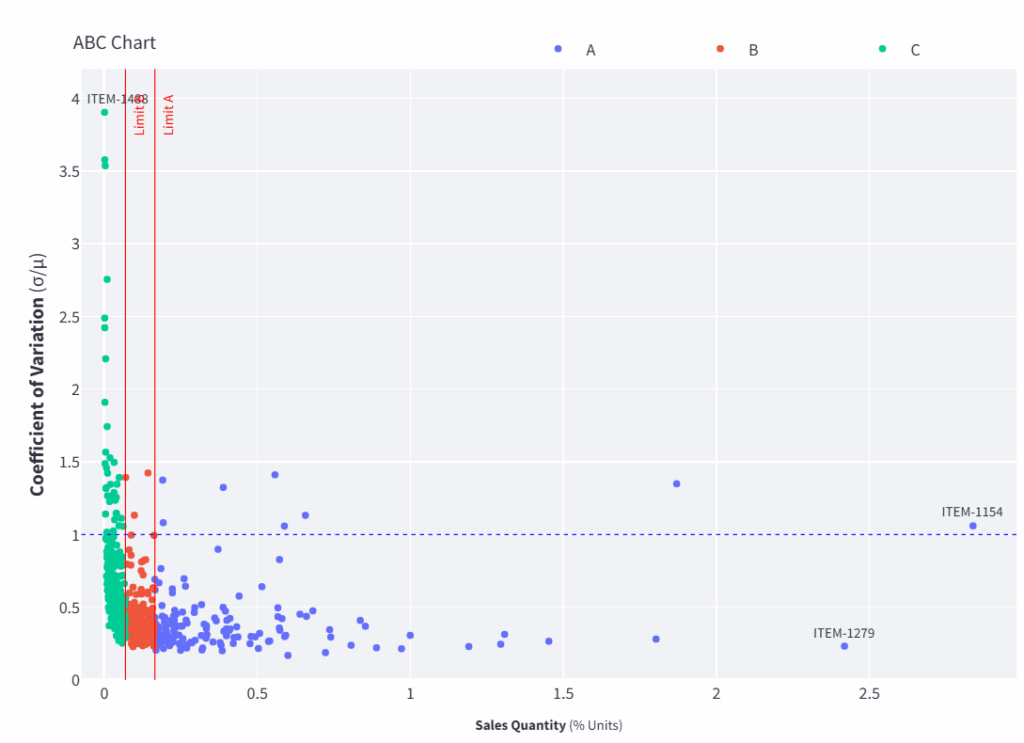
ABC XYZ图表 – (图片由Samir Saci提供)
- X轴(销售额百分比 %):每个商品对总收入的贡献。
- Y轴(变异系数):每个商品的市场需求波动性。
- 垂直红线根据销售额份额将商品分为A、B和C类。
- 水平蓝线标记了稳定需求与可变需求(CV=1)的分界。
这些指标共同突出了哪些商品是高价值且稳定(A类,低CV),哪些是低价值或高度可变的,从而指导库存管理的优先级。
第二个可视化图表是销售额的帕累托分析:
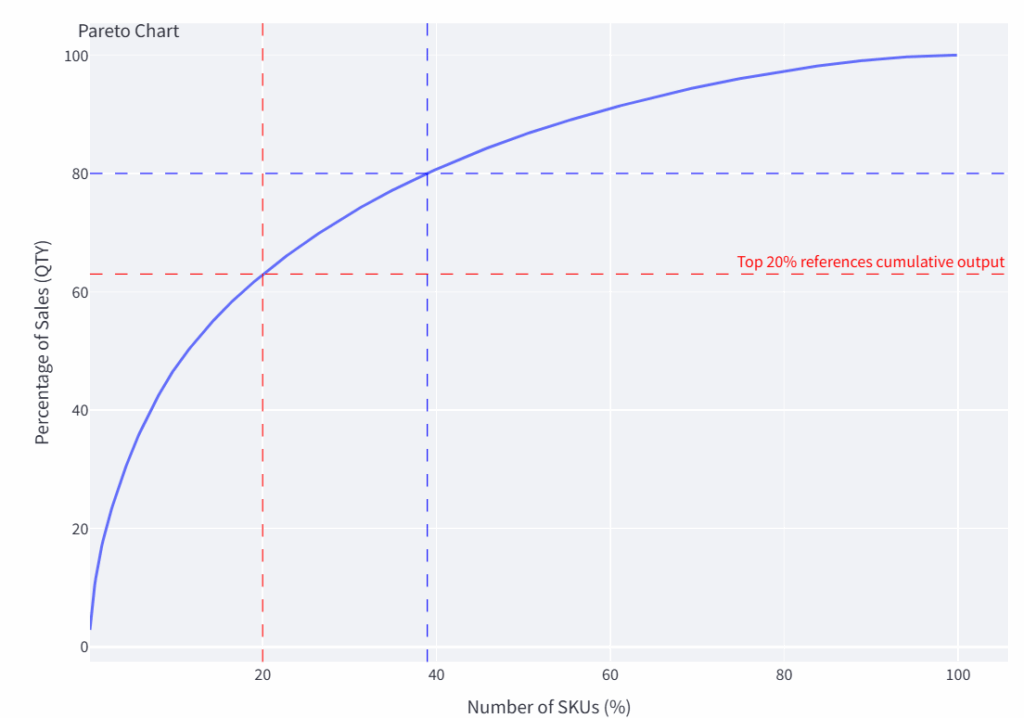
Logigreen App生成的帕累托图表 – (图片由Samir Saci提供)
- X轴:SKU百分比(按销售额排名)。
- Y轴:年度销售额的累计百分比。
- 曲线展示了少数商品如何贡献了大部分收入。
简而言之,这突出了(或未突出)经典的帕累托法则,即80%的销售额可能来自20%的SKU。
这些可视化图表是通过Python生成的。
在一个YouTube频道上,分享了一个完整的教程,展示了如何使用Pandas和Matplotlib实现这一点。
本教程的目标是使用n8n的原生JavaScript节点,准备销售交易数据并在Google表格中生成这些可视化图表。
在n8n中构建数据分析工作流
建议构建一个手动触发的工作流,以方便在开发过程中进行调试。
手动触发的最终工作流,用于从Google表格收集数据以生成可视化图表 – (图片由Samir Saci提供)
要跟随本教程,需要:
- 复制此链接提供的电子表格:Google表格
- 从n8n创建者配置文件下载模板:n8n创建者配置文件
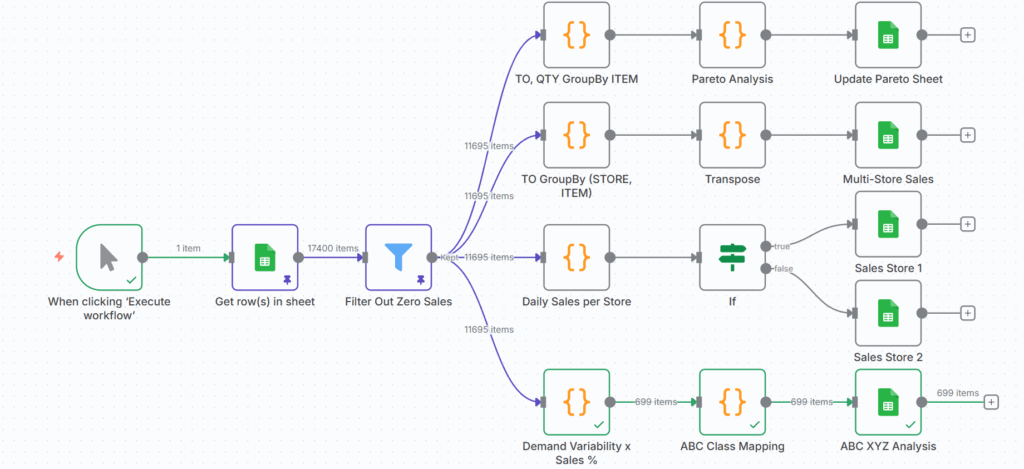
现在可以使用第二个节点Input Data连接复制的表格,该节点将从工作表中提取数据集。
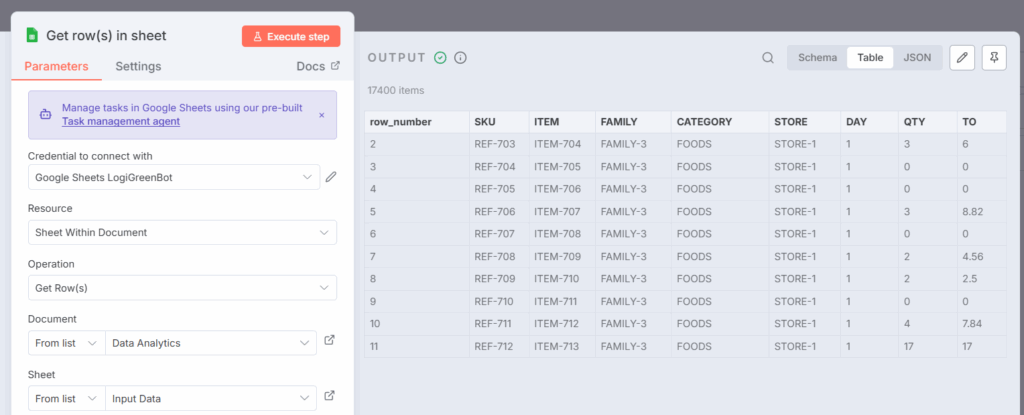
将第二个节点连接到您的Google表格副本以收集输入数据 – (图片由Samir Saci提供)
此数据集包括每日粒度的零售销售交易:
ITEM:可以在多个商店销售的商品SKU:代表在特定商店销售的SKUFAMILY:一组商品CATEGORY:一个产品类别可以包含多个系列STORE:代表销售地点的代码DAY:交易日期QTY:以单位计的销售数量TO:以欧元计的销售额
输出是JSON格式的表格内容,可供其他节点摄取。
Python代码
import pandas as pd
df = pd.read_csv("sales.csv")
现在可以开始处理数据集,以构建两个可视化图表。
步骤1:过滤掉没有销售额的交易
首先,过滤掉销售数量QTY为零的交易。
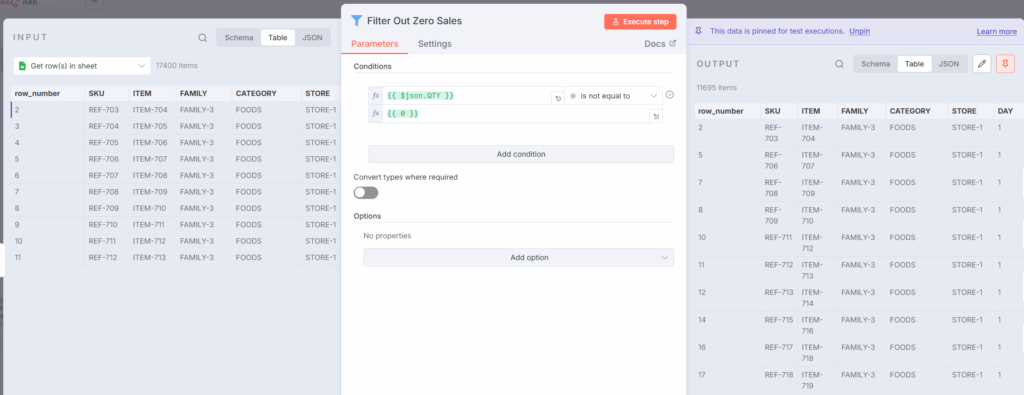
使用过滤节点过滤掉没有销售额的交易 – (图片由Samir Saci提供)
这里不需要JavaScript;一个简单的过滤节点就可以完成这项工作。
Python代码
df = df[df["QTY"] != 0]
步骤2:为帕累托分析准备数据
首先需要按ITEM聚合销售额,并按销售额对产品进行排名。
Python代码
sku_agg = (df.groupby("ITEM", as_index=False)
.agg(TO=("TO","sum"), QTY=("QTY","sum"))
.sort_values("TO", ascending=False))
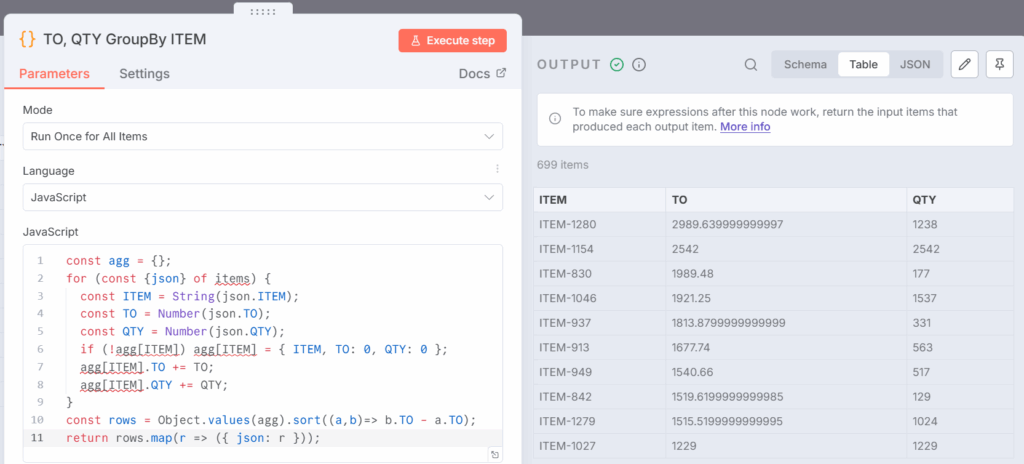
在工作流中,此步骤将在JavaScript节点TO, QTY GroupBY ITEM中完成:
const agg = {};
for (const {json} of items) {
const ITEM = json.ITEM;
const TO = Number(json.TO);
const QTY = Number(json.QTY);
if (!agg[ITEM]) agg[ITEM] = { ITEM, TO: 0, QTY: 0 };
agg[ITEM].TO += TO;
agg[ITEM].QTY += QTY;
}
const rows = Object.values(agg).sort((a,b)=> b.TO - a.TO);
return rows.map(r => ({ json: r }));
此节点返回一个按ITEM划分的销售数量(QTY)和销售额(TO)的排名表格:
- 将agg初始化为一个以ITEM为键的字典。
- 遍历n8n中的items行。
- 将TO和QTY转换为数字。
- 将QTY和TO值添加到每个ITEM的累计总额中。
- 最后,将字典转换为一个按TO降序排序的数组并返回项。
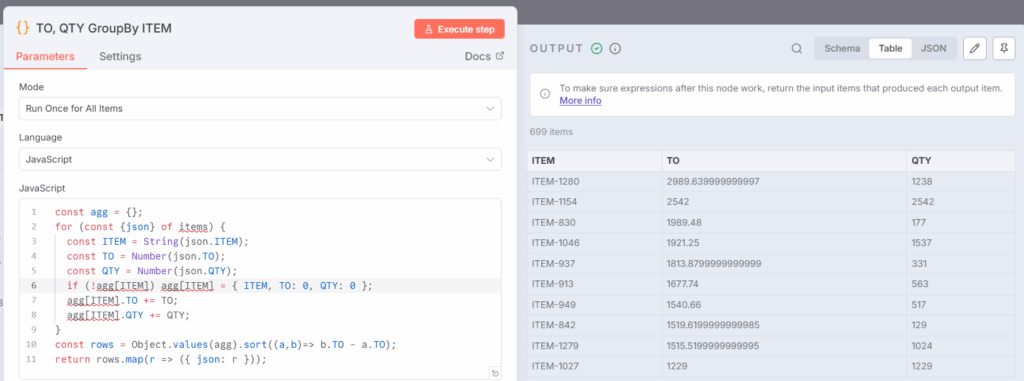
按ITEM聚合销售额的输出数据 – (图片由Samir Saci提供)
现在数据已准备好,可以对销售数量(QTY)或销售额(TO)执行帕累托分析。
为此,需要计算累计销售额并对SKU进行排名,从贡献最高到最低。
Python代码
abc = sku_agg.copy() # from Step 2, already sorted by TO desc
total = abc["TO"].sum() or 1.0
abc["cum_turnover"] = abc["TO"].cumsum()
abc["cum_share"] = abc["cum_turnover"] / total
abc["sku_rank"] = range(1, len(abc) + 1)
abc["cum_skus"] = abc["sku_rank"] / len(abc)
abc["cum_skus_pct"] = abc["cum_skus"] * 100
此步骤将在代码节点Pareto Analysis中完成:
const rows = items
.map(i => ({
...i.json,
TO: Number(i.json.TO || 0),
QTY: Number(i.json.QTY || 0),
}))
.sort((a, b) => b.TO - a.TO);
const n = rows.length; // number of ITEM
const totalTO = rows.reduce((s, r) => s + r.TO, 0) || 1;
从前一个节点收集数据集items:
- 对于每一行,清理字段
TO和QTY(以防有缺失值)。 - 按销售额降序排序所有SKU。
- 将商品数量和总销售额存储在变量中。
let cumTO = 0;
rows.forEach((r, idx) => {
cumTO += r.TO;
r.cum_turnover = cumTO;
r.cum_share = +(cumTO / totalTO).toFixed(6);
r.sku_rank = idx + 1;
r.cum_skus = +((idx + 1) / n).toFixed(6);
r.cum_skus_pct = +(r.cum_skus * 100).toFixed(2);
});
return rows.map(r => ({ json: r }));
然后按排序顺序遍历所有商品。
- 使用变量
cumTO计算累计贡献。 - 为每一行添加几个帕累托指标:
cum_turnover:到此商品为止的累计销售额cum_share:累计销售额占比sku_rank:商品的排名位置cum_skus:累计SKU数量占总SKU数量的比例cum_skus_pct:与cum_skus相同,但以百分比表示。
至此,帕累托图表的数据准备已完成。
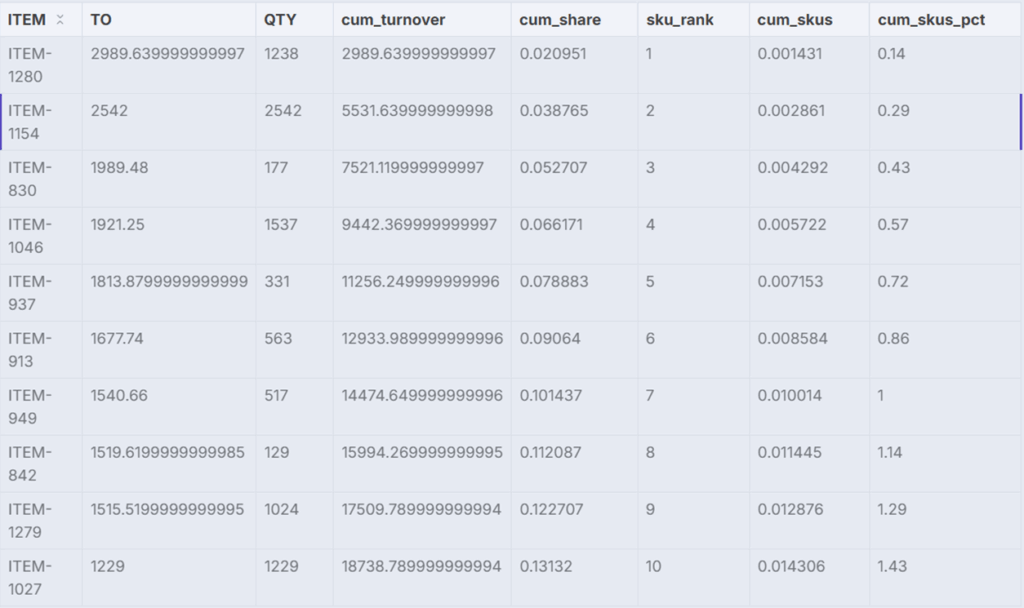
最终结果 – (图片由Samir Saci提供)
此数据集将由节点Update Pareto Sheet存储在工作表Pareto中。
通过一些巧妙的操作,可以在第一个工作表中生成此图表:
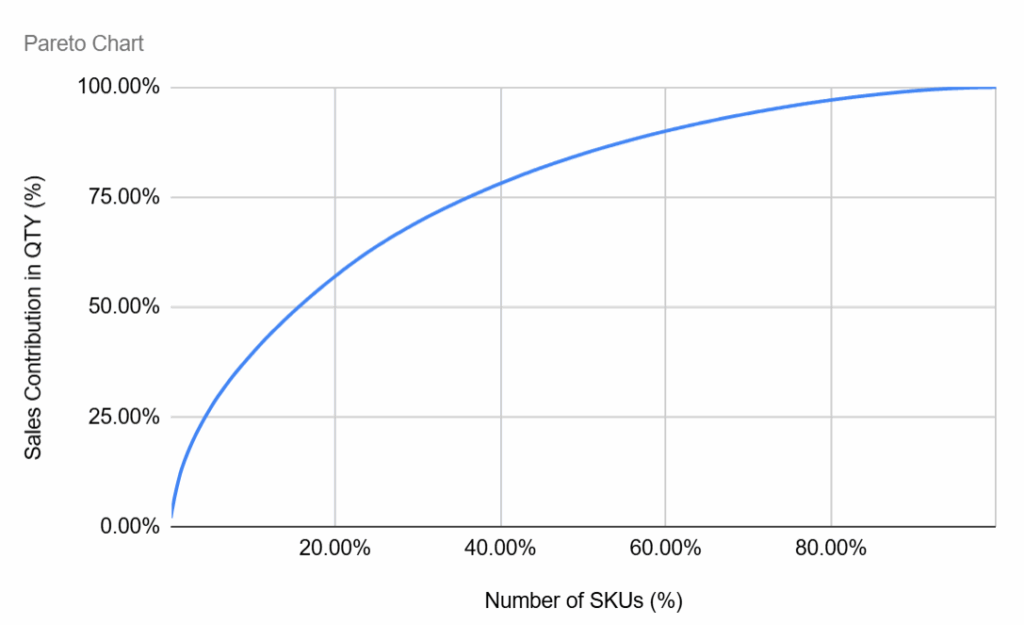
使用n8n工作流处理数据生成的帕累托图表 – (图片由Samir Saci提供)
现在可以继续制作ABC XYZ图表。
步骤3:计算需求变异性和销售贡献
虽然可以重用帕累托图表的输出作为销售贡献,但为了清晰起见,将每个图表视为独立的。
为了更清晰地说明,将节点“需求变异性”和“销售额与销售百分比”的代码拆分为多个部分。
第一部分:定义均值和标准差的函数
function mean(a){ return a.reduce((s,x)=>s + x, 0) / (a.length || 1); }
function stdev_samp(a){
if (a.length <= 1) return 0;
const m = mean(a);
const v = a.reduce((s,x)=> s + (x - m) ** 2, 0) / (a.length - 1);
return Math.sqrt(v);
}
这两个函数将用于计算变异系数(Cov):
mean(a):计算数组的平均值。stdev_samp(a):计算样本标准差。
它们以在第二部分中构建的每个ITEM的日销售分布作为输入。
第二部分:创建每个ITEM的日销售分布
const series = {}; // ITEM -> { day -> qty_sum }
let totalQty = 0;
for (const { json } of items) {
const item = String(json.ITEM);
const day = String(json.DAY);
const qty = Number(json.QTY || 0);
if (!series[item]) series[item] = {};
series[item][day] = (series[item][day] || 0) + qty;
totalQty += qty;
}
Python代码
import pandas as pd
import numpy as np
df['QTY'] = pd.to_numeric(df['QTY'], errors='coerce').fillna(0)
daily_series = df.groupby(['ITEM', 'DAY'])['QTY'].sum().reset_index()
现在可以计算应用于日销售分布的指标。
const out = [];
for (const [item, dayMap] of Object.entries(series)) {
const daily = Object.values(dayMap); // daily sales quantities
const qty_total = daily.reduce((s,x)=>s+x, 0);
const m = mean(daily); // average daily sales
const sd = stdev_samp(daily); // variability of sales
const cv = m ? sd / m : null; // coefficient of variation
const share_qty_pct = totalQty ? (qty_total / totalQty) * 100 : 0;
out.push({
ITEM: item,
qty_total,
share_qty_pct: Number(share_qty_pct.toFixed(2)),
mean_qty: Number(m.toFixed(3)),
std_qty: Number(sd.toFixed(3)),
cv_qty: cv == null ? null : Number(cv.toFixed(3)),
});
}
对于每个ITEM,计算:
qty_total:总销售额mean_qty:日均销售额。std_qty:日销售额标准差。cv_qty:变异系数(用于XYZ分类的变异性度量)share_qty_pct:占总销售额的百分比贡献(用于ABC分类)
以防读者混淆,以下是Python版本代码:
summary = daily_series.groupby('ITEM').agg(
qty_total=('QTY', 'sum'),
mean_qty=('QTY', 'mean'),
std_qty=('QTY', 'std')
).reset_index()
summary['std_qty'] = summary['std_qty'].fillna(0)
total_qty = summary['qty_total'].sum()
summary['cv_qty'] = summary['std_qty'] / summary['mean_qty'].replace(0, np.nan)
summary['share_qty_pct'] = 100 * summary['qty_total'] / total_qty
我们即将完成。
只需按贡献降序排序,为ABC类别的映射做准备:
out.sort((a,b) => b.share_qty_pct - a.share_qty_pct);
return out.map(r => ({ json: r }));
现在每个ITEM都拥有创建散点图所需的关键指标。
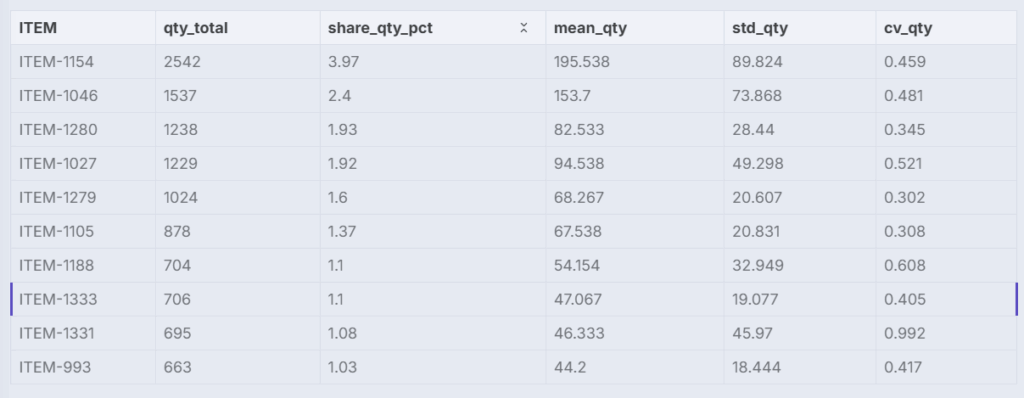
“需求变异性与销售百分比”节点的输出 – (图片由Samir Saci提供)
在此步骤中,仅缺少ABC类别。
步骤4:添加ABC类别
以前一个节点的输出作为输入。
let rows = items.map(i => i.json);
rows.sort((a, b) => b.share_qty_pct - a.share_qty_pct);
以防万一,按销售份额(%)降序对ITEMS进行排序 → 最重要的SKU排在前面。
(此步骤可以省略,因为它通常在前一个代码节点结束时已经完成。)
然后可以根据硬编码的条件应用类别:
- A:总销售额占前5%的SKU
- B:总销售额占接下来15%的SKU
- C:20%之后的所有SKU。
let cum = 0;
for (let r of rows) {
cum += r.share_qty_pct;
// 3) 根据累计百分比分配类别
if (cum <= 5) {
r.ABC = 'A'; // 前5%
} else if (cum <= 20) {
r.ABC = 'B'; // 接下来15%
} else {
r.ABC = 'C'; // 其余
}
r.cum_share = Number(cum.toFixed(2));
}
return rows.map(r => ({ json: r }));
使用Python代码可以这样完成:
df = df.sort_values('share_qty_pct', ascending=False).reset_index(drop=True)
df['cum_share'] = df['share_qty_pct'].cumsum()
def classify(cum):
if cum <= 5:
return 'A'
elif cum <= 20:
return 'B'
else:
return 'C'
df['ABC'] = df['cum_share'].apply(classify)
现在可以使用结果生成此图表,该图表可以在Google表格的第一个工作表中找到:
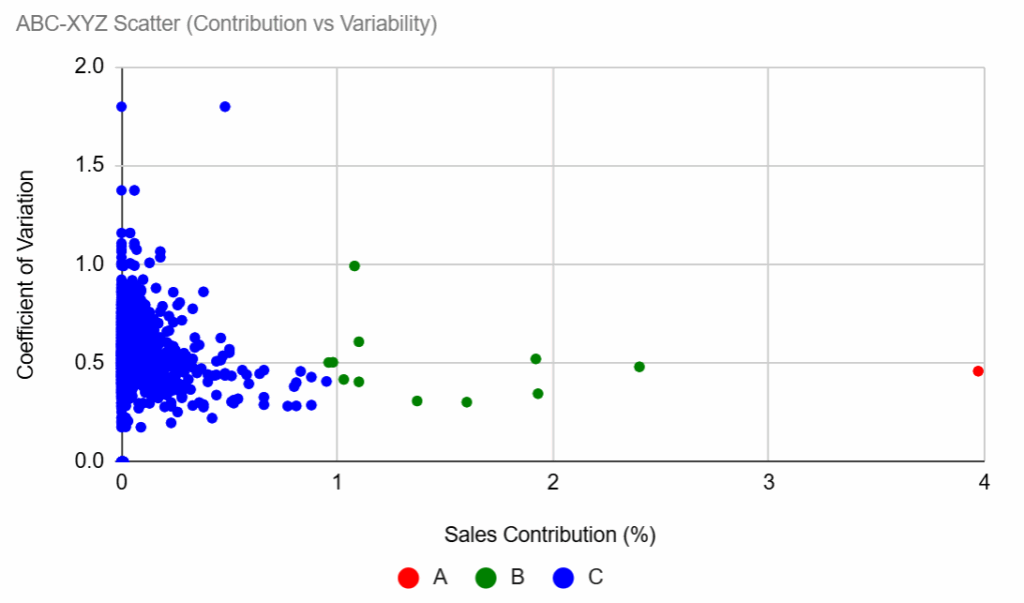
使用JavaScript通过工作流处理数据生成的ABC XYZ图表 – (图片由Samir Saci提供)
要在Google表格中创建这个带有正确颜色映射的散点图,曾遇到一些困难(可能是由于对Google表格的了解有限),未能找到“手动”解决方案。
因此,使用了Google表格中提供的Google Apps Script来创建它。
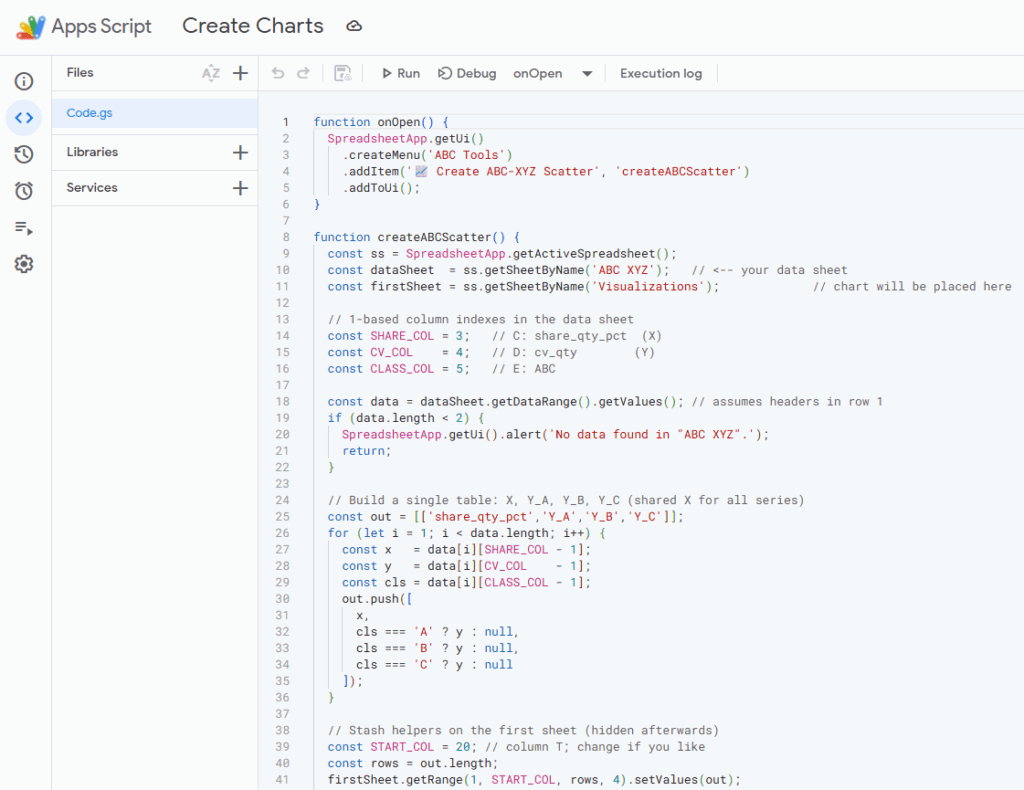
Google表格中包含的用于生成可视化图表的脚本 – (图片由Samir Saci提供)
作为额外的福利,在n8n模板中添加了更多节点,它们执行相同类型的分组操作,以计算按商店或ITEM-商店对的销售额。
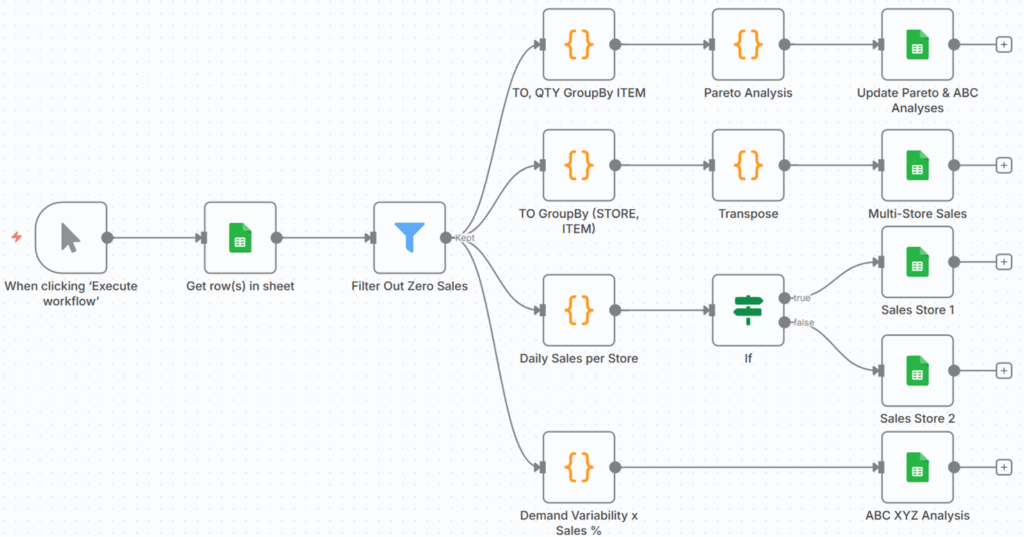
共同构建的实验性工作流 – (图片由Samir Saci提供)
这些节点可以用于创建如下所示的可视化图表:
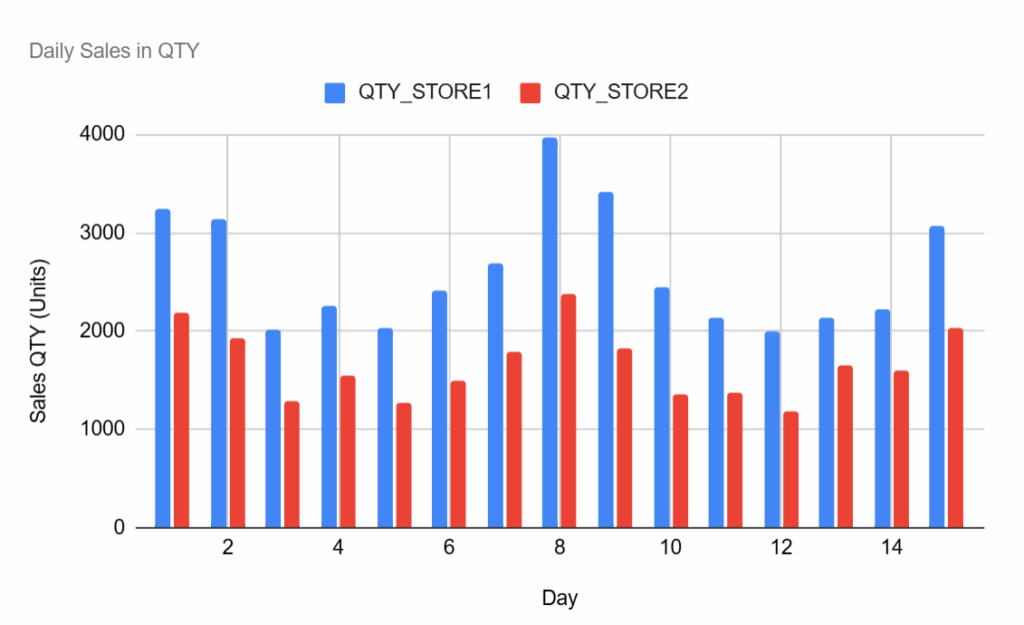
各门店每日总销售数量 – (图片由Samir Saci提供)
至此,可以自信地宣布,本教程的任务已圆满完成。
要查看工作流的实时演示,可以观看这个简短的教程。
在n8n云实例上运行此工作流的客户现在可以清晰地了解数据处理的每一步。
但这代价是什么呢?是否会损失性能?
这将在下一节中进行探讨。
n8n JavaScript节点与FastAPI中Python的性能对比研究
为了回答这个问题,准备了一个直接的实验。
使用n8n内部的两种不同方法处理相同的数据集和转换:
- 纯JavaScript节点:直接在n8n内部使用JavaScript函数。
- 外包给FastAPI微服务:通过HTTP请求调用Python端点来替代JavaScript逻辑。
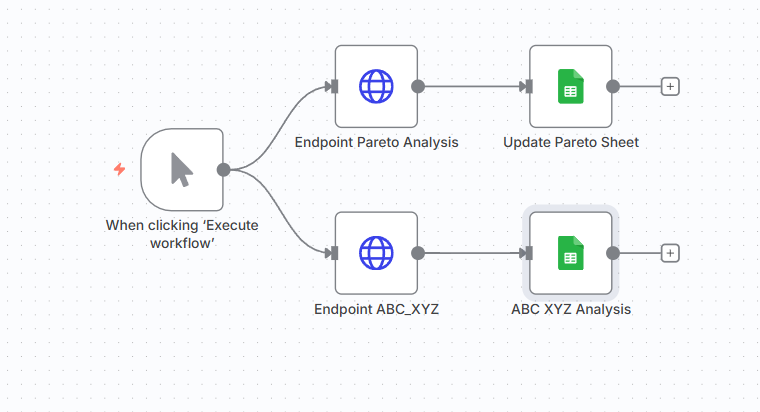
使用FastAPI微服务的简单工作流 – (图片由Samir Saci提供)
这两个端点连接到将直接从托管微服务的VPS实例加载数据的功能。
@router.post("/launch_pareto")
async def launch_speedtest(request: Request):
try:
session_id = request.headers.get('session_id', 'session')
folder_in = f'data/session/speed_test/input'
if not path.exists(folder_in):
makedirs(folder_in)
file_path = folder_in + '/sales.csv'
logger.info(f"[SpeedTest]: Loading data from session file: {file_path}")
df = pd.read_csv(file_path, sep=";")
logger.info(f"[SpeedTest]: Data loaded successfully: {df.head()}")
speed_tester = SpeedAnalysis(df)
output = await speed_tester.process_pareto()
result = output.to_dict(orient="records")
result = speed_tester.convert_numpy(result)
logger.info(f"[SpeedTest]: /launch_pareto completed successfully for {session_id}")
return result
except Exception as e:
logger.error(f"[SpeedTest]: Error /launch_pareto: {str(e)}
{traceback.format_exc()}")
raise HTTPException(status_code=500, detail=f"Failed to process Speed Test Analysis: {str(e)}")
@router.post("/launch_abc_xyz")
async def launch_abc_xyz(request: Request):
try:
session_id = request.headers.get('session_id', 'session')
folder_in = f'data/session/speed_test/input'
if not path.exists(folder_in):
makedirs(folder_in)
file_path = folder_in + '/sales.csv'
logger.info(f"[SpeedTest]: Loading data from session file: {file_path}")
df = pd.read_csv(file_path, sep=";")
logger.info(f"[SpeedTest]: Data loaded successfully: {df.head()}")
speed_tester = SpeedAnalysis(df)
output = await speed_tester.process_abcxyz()
result = output.to_dict(orient="records")
result = speed_tester.convert_numpy(result)
logger.info(f"[SpeedTest]: /launch_abc_xyz completed successfully for {session_id}")
return result
except Exception as e:
logger.error(f"[SpeedTest]: Error /launch_abc_xyz: {str(e)}
{traceback.format_exc()}")
raise HTTPException(status_code=500, detail=f"Failed to process Speed Test Analysis: {str(e)}")
本次测试仅关注数据处理性能。
SpeedAnalysis包含了上一节中列出的所有数据处理步骤:
- 按
ITEM对销售额进行分组 - 按降序排序
ITEM并计算累计销售额 - 计算按
ITEM划分的销售分布的标准差和均值
class SpeedAnalysis:
def __init__(self, df: pd.DataFrame):
config = load_config()
self.df = df
def processing(self):
try:
sales = self.df.copy()
sales = sales[sales['QTY']>0].copy()
self.sales = sales
except Exception as e:
logger.error(f'[SpeedTest] Error for processing : {e}
{traceback.format_exc()}')
def prepare_pareto(self):
try:
sku_agg = self.sales.copy()
sku_agg = (sku_agg.groupby("ITEM", as_index=False)
.agg(TO=("TO","sum"), QTY=("QTY","sum"))
.sort_values("TO", ascending=False))
pareto = sku_agg.copy()
total = pareto["TO"].sum() or 1.0
pareto["cum_turnover"] = pareto["TO"].cumsum()
pareto["cum_share"] = pareto["cum_turnover"] / total
pareto["sku_rank"] = range(1, len(pareto) + 1)
pareto["cum_skus"] = pareto["sku_rank"] / len(pareto)
pareto["cum_skus_pct"] = pareto["cum_skus"] * 100
return pareto
except Exception as e:
logger.error(f'[SpeedTest]Error for prepare_pareto: {e}
{traceback.format_exc()}')
def abc_xyz(self):
daily = self.sales.groupby(["ITEM", "DAY"], as_index=False)["QTY"].sum()
stats = (
daily.groupby("ITEM")["QTY"]
.agg(
qty_total="sum",
mean_qty="mean",
std_qty="std"
)
.reset_index()
)
stats["cv_qty"] = stats["std_qty"] / stats["mean_qty"].replace(0, np.nan)
total_qty = stats["qty_total"].sum()
stats["share_qty_pct"] = (stats["qty_total"] / total_qty * 100).round(2)
stats = stats.sort_values("share_qty_pct", ascending=False).reset_index(drop=True)
stats["cum_share"] = stats["share_qty_pct"].cumsum().round(2)
def classify(cum):
if cum <= 5:
return "A"
elif cum <= 20:
return "B"
else:
return "C"
stats["ABC"] = stats["cum_share"].apply(classify)
return stats
def convert_numpy(self, obj):
if isinstance(obj, dict):
return {k: self.convert_numpy(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [self.convert_numpy(v) for v in obj]
elif isinstance(obj, (np.integer, int)):
return int(obj)
elif isinstance(obj, (np.floating, float)):
return float(obj)
else:
return obj
async def process_pareto(self):
"""Main processing function that calls all other methods in order."""
self.processing()
outputs = self.prepare_pareto()
return outputs
async def process_abcxyz(self):
"""Main processing function that calls all other methods in order."""
self.processing()
outputs = self.abc_xyz().fillna(0)
logger.info(f"[SpeedTest]: ABC-XYZ analysis completed {outputs}.")
return outputs
现在这些端点已准备就绪,可以开始测试。

实验结果(上:使用原生代码节点处理 / 下:FastAPI微服务) – (图片由Samir Saci提供)
结果如上所示:
- 纯JavaScript工作流:整个过程在略超过11.7秒内完成。
大部分时间用于更新工作表和在n8n节点内执行迭代计算。
- FastAPI支持的工作流:等效的“外包”过程在约11.0秒内完成。
繁重计算被卸载到Python微服务,其处理速度比原生JavaScript节点更快。
换句话说,将复杂计算外包给Python实际上可以提高性能。
原因是FastAPI端点直接执行优化过的Python函数,而n8n内部的JavaScript节点必须通过循环进行迭代。
对于大型数据集,可以想象性能差异可能不容忽视。
结论
这表明,可以使用小的JavaScript代码片段在n8n内部进行简单的数据处理。
然而,供应链分析产品可能需要更高级的处理,涉及优化和高级统计库。
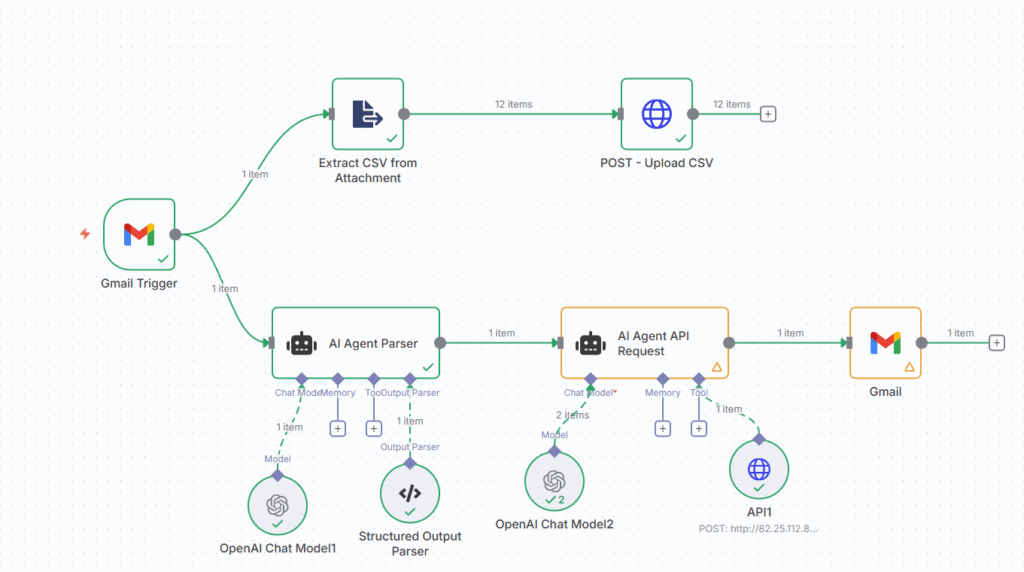
用于生产计划优化的AI工作流 (图片由Samir Saci提供)
为此,客户可以接受“黑盒”方法,正如这篇Towards Data Science文章中展示的生产计划工作流。
但对于轻量级处理任务,可以将它们集成到工作流中,以便为非代码用户提供可见性。
对于另一个项目,n8n被用于通过电子数据交换(EDI)连接供应链IT系统进行采购订单的传输。
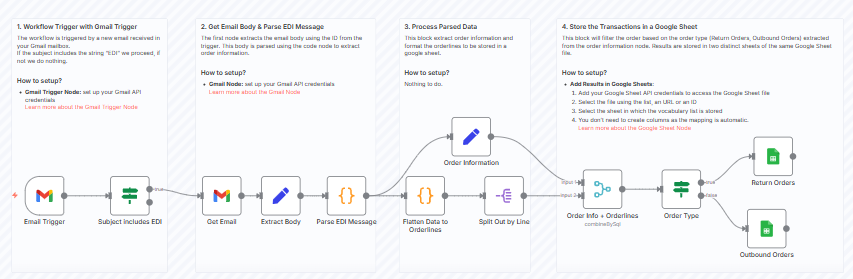
电子数据交换(EDI)消息解析工作流示例 – (图片由Samir Saci提供)
这个为一家小型物流公司部署的工作流,完全使用JavaScript节点解析EDI消息。
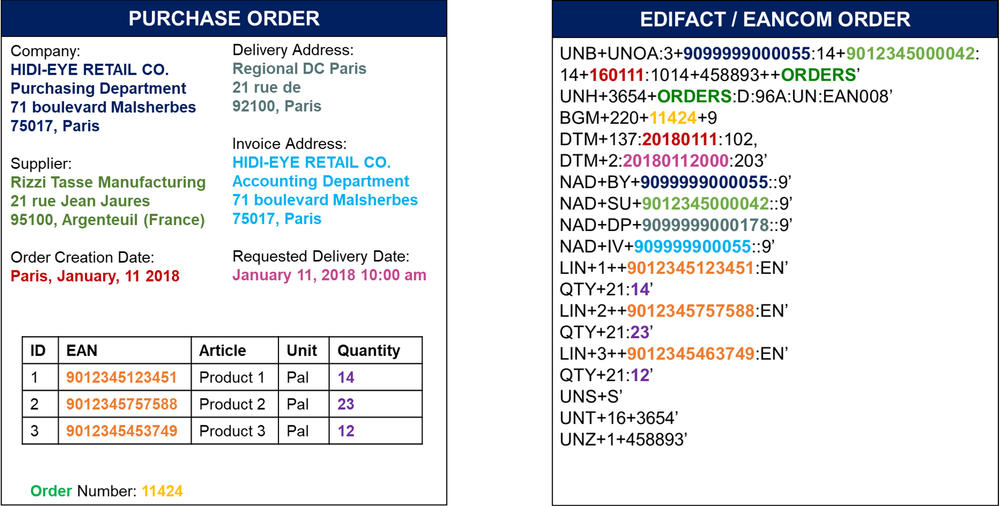
电子数据交换消息示例 – (图片由Samir Saci提供)
正如本教程所展示的,所有电子数据交换消息的解析都使用JavaScript节点完成。
这有助于提高解决方案的鲁棒性,并通过将维护工作移交给客户来减轻工作量。
哪种方法是最佳选择?
n8n应当被用作连接核心分析产品的编排和集成工具。
这些分析产品需要特定的输入格式,这些格式可能与客户的数据不完全一致。
因此,建议使用JavaScript代码节点来执行这种预处理。
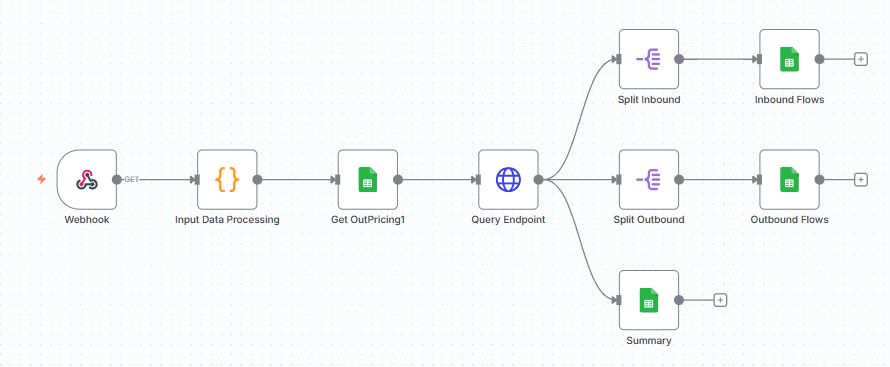
用于分销计划优化算法的工作流 – (图片由Samir Saci提供)
例如,上述工作流将一个Google表格(包含输入数据)连接到一个FastAPI微服务,该微服务运行一个分销计划优化算法。
目标是将优化算法与分销计划员用于组织门店配送的Google表格集成。
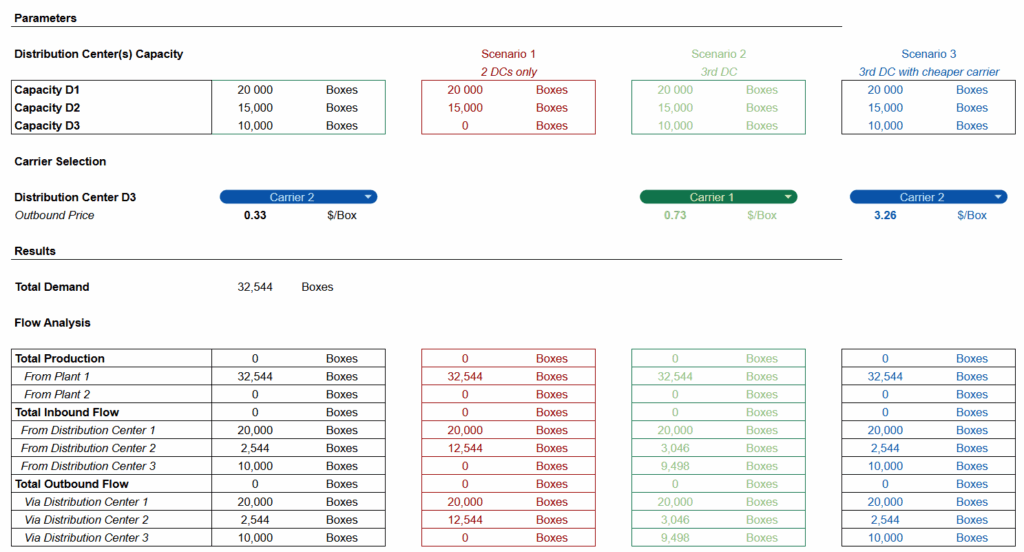
计划团队使用的工作表 – (图片由Samir Saci提供)
JavaScript代码节点用于将从Google表格收集的数据转换为算法所需的输入格式。
通过在工作流内部完成这项工作,它保持在客户的控制之下,客户可以在自己的实例中运行工作流。
而优化部分则可以保留在托管在独立实例上的微服务中。
为了更好地理解此设置,请随意查看此简短演示。
本教程和上述示例希望能为读者提供足够的洞察力,以了解n8n在数据分析方面的潜力。
欢迎分享对这种方法的评论以及对如何改进工作流性能的看法。