本文将深入探讨RAG(检索增强生成)流程中的关键一环:文档检索步骤。这一环节对于任何RAG系统的性能都至关重要。设想一下,如果无法获取最相关的文档,大型语言模型(LLM)将难以准确回答用户的提问。文章将介绍传统的文档检索方法、优化技术,以及提升检索效果对RAG系统性能带来的显著益处。
正如前一篇关于利用元数据丰富LLM上下文以显著增强能力的文章所提及,本文的核心目标是:
本文目标旨在阐明如何为AI搜索系统高效地获取和筛选最相关的文档。
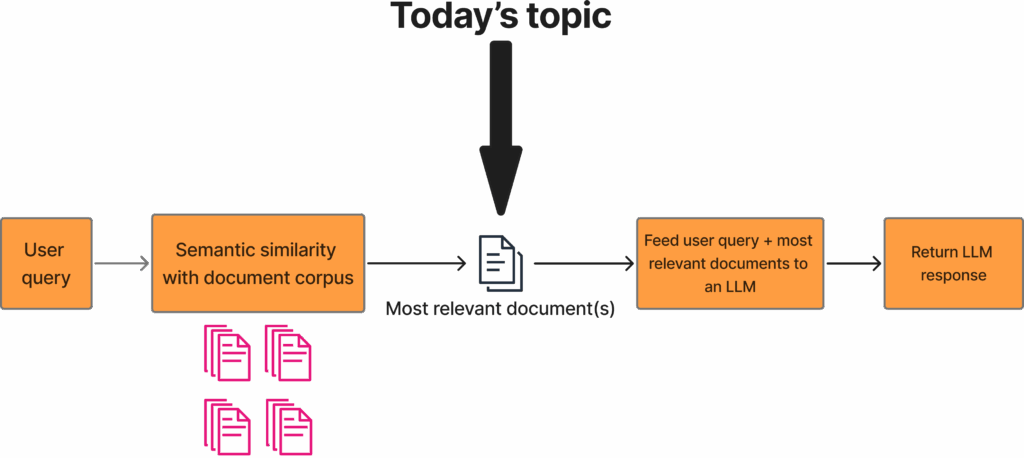
这张图展示了一个传统的RAG流程。首先,用户提出查询,系统会使用嵌入模型对其进行编码。随后,将这个查询嵌入与整个文档语料库中预先计算好的文档嵌入进行比较。通常,文档会被分割成若干个带有重叠的块(chunk),尽管有些系统也直接处理完整的文档。在计算出嵌入相似度后,系统仅保留前K个最相关的文档,K值通常由开发者自行设定,一般介于10到20之间。根据语义相似性获取最相关文档的这一步骤,正是本文重点探讨的主题。在获取这些文档后,它们将与用户查询一同输入给LLM,LLM最终会生成相应的回复。
目录
文档检索为何如此重要?
深入理解文档获取步骤对RAG流程的关键性至关重要。为此,需要先对RAG流程的整体框架有一个大致的了解:
- 用户输入查询
- 查询被嵌入(embedding),并计算查询嵌入与每个文档(或文档块)之间的嵌入相似度
- 根据嵌入相似度获取最相关的文档
- 最相关的文档(或文档块)被输入到LLM中,LLM根据这些提供的文档块回答用户问题
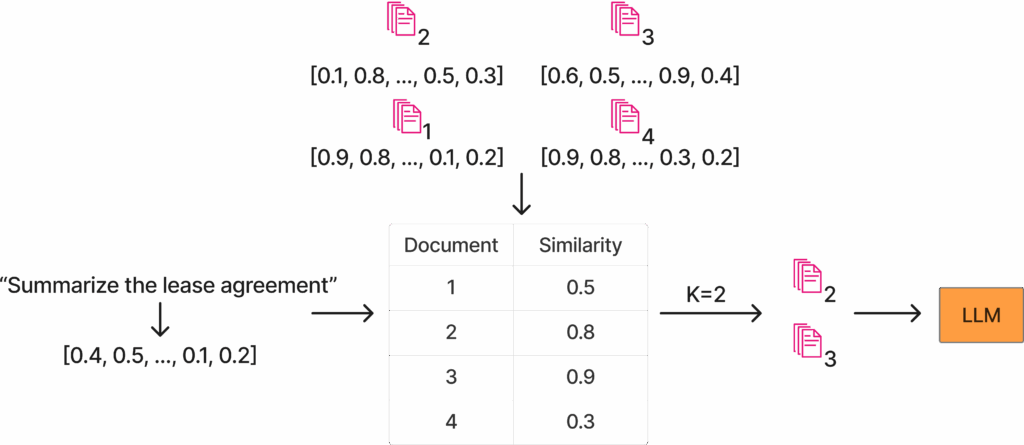
这张图清晰地展示了嵌入相似度的概念。左侧是用户查询:“总结租赁协议”。这个查询被嵌入到文本下方所示的向量中。此外,图示顶部中央是可用的文档语料库,本例中包含四份文档,所有文档都具有预先计算好的嵌入。随后,系统计算查询嵌入与每份文档之间的相似度。在此示例中,K值为2,因此系统将两份最相关的文档提供给LLM进行问答。
RAG管线中有几个重要方面,例如:
- 使用何种嵌入模型
- 采用何种LLM模型
- 获取多少文档(或文档块)
然而,文档选择的重要性在整个RAG管线中是首屈一指的。因为如果没有正确的文档,无论LLM表现多优秀,也无论获取了多少文档块,生成的答案很可能都是不准确的。
即使使用性能稍逊的嵌入模型或稍微旧一点的LLM,系统或许仍能运作。但如果未能获取到正确的文档,RAG管线将直接失效。
传统方法
首先,将了解目前常用的一些传统方法,主要包括嵌入相似性和关键词搜索。
嵌入相似性
利用嵌入相似性来获取最相关文档是当前的主流方法。这是一种在多数用例中表现良好的稳健方法。基于嵌入相似性的RAG文档检索原理与前文描述一致。
关键词搜索
关键词搜索也是获取相关文档的常用技术。传统的TF-IDF或BM25等方法至今仍被成功应用。然而,关键词搜索也存在其固有的局限性。例如,它通常只根据精确匹配来获取文档,当无法实现精确匹配时,就会出现问题。
因此,本文将探讨一些可以用来改进文档检索步骤的其他技术。
获取更相关文档的技术
本节将探讨一些更先进的文档获取技术。内容将分为两部分:第一部分侧重于优化文档检索的“召回率”,即从可用文档语料库中尽可能多地获取相关文档;第二部分则讨论如何优化“精确率”,这意味着确保所获取的文档对于用户查询来说是真正准确且相关的。
召回率:获取更多相关文档
以下将讨论几种技术:
- 上下文检索
- 获取更多文档块
- 重排序
上下文检索

这张图展示了上下文检索的流程。该流程包含与传统RAG管线相似的元素,例如用户提示、向量数据库(DB),以及将前K个最相关的文档块输入LLM。然而,上下文检索进一步引入了一些新元素。首先是BM25索引,所有文档(或文档块)都会被索引以供BM25搜索。每当执行搜索时,系统可以快速索引查询并根据BM25获取最相关的文档。随后,系统会从BM25和语义相似性(向量数据库)两种方法中分别保留前K个最相关文档,并将它们的嵌入结合起来。最后,像往常一样,将最相关的文档与用户查询一同输入给LLM,并接收回复。
上下文检索是Anthropic公司在2024年9月推出的一项技术。他们的文章涵盖了两个主要方面:为文档块添加上下文信息,以及将关键词搜索(BM25)与语义搜索结合起来以获取相关文档。
为了给文档添加上下文,该方法会获取每个文档块,并结合该文档块及完整文档,提示LLM重写此文档块,使其既包含原始文档块的信息,也融入来自完整文档的相关上下文。
例如,如果一份文档被分为两个文档块,其中一个文档块包含地址、日期、位置和时间等重要元数据,而另一个文档块包含租赁协议的信息。LLM可能会重写第二个文档块,使其既包含租赁协议的内容,也纳入第一个文档块中最相关的部分,如地址、位置和日期。
Anthropic在其文章中也讨论了如何结合语义搜索和关键词搜索,通过这两种技术共同获取文档,并采用一种优先级策略来整合从两种方法中检索到的文档。
获取更多文档块
一种获取更多相关文档的更简单方法是直接获取更多的文档块。获取的文档块越多,系统检索到相关文档块的可能性就越大。然而,这种方法也有两个主要缺点:
- 系统也可能获取到更多不相关的文档块(影响召回率)
- 会增加输入LLM的token数量,这可能会对LLM的输出质量产生负面影响
针对召回率的重排序
重排序(Reranking)也是一种强大的技术,可用于在根据用户查询获取相关文档时提高精确率和召回率。当基于语义相似性获取文档时,系统会为所有文档块分配一个相似度分数,通常只保留前K个最相似的文档块(K值通常在10到20之间,但会根据不同应用而异)。这意味着重排序器应尝试将相关文档提升到前K个最相关文档的列表中,同时将不相关文档排除在外。Qwen Reranker是一个性能不错的模型,但市面上也存在许多其他优秀的重排序器。
精确率:过滤不相关文档
- 重排序
- LLM验证
针对精确率的重排序
如前一节关于召回率的讨论所述,重排序器同样可以用于提高精确率。重排序器通过将相关文档纳入前K个最相关文档列表来提高召回率。另一方面,重排序器通过确保不相关文档不进入前K个最相关文档列表,从而提高精确率。
LLM验证
利用LLM来判断文档块(或文档)的相关性,也是过滤掉不相关文档块的强大技术。可以简单地创建一个类似如下的函数:
def is_relevant_chunk(chunk_text: str, user_query: str) -> bool:
"""
Verify if the chunk text is relevant to the user query
"""
prompt = f"""
Given the provided user query, and chunk text, determine whether the chunk text is relevant to answer the user query.
Return a json response with {
"relevant": bool
}
<user_query>{user_query}</user_query>
<chunk_text>{chunk_text}</chunk_text>
"""
return llm_client.generate(prompt)
然后,将每个文档块(或文档)通过这个函数进行处理,只保留那些被LLM判断为相关的文档块或文档。
这项技术主要有两个缺点:
- LLM调用成本
- LLM响应时间
由于需要发送大量的LLM API调用,这不可避免地会产生显著的成本。此外,发送如此多的查询会耗费时间,从而增加RAG管线的延迟。在实际应用中,需要在这项技术带来的优势与用户对快速响应的需求之间取得平衡。
优化文档检索的益处
改进RAG管线中的文档检索步骤会带来诸多益处。例如:
- 提升LLM问答性能
- 减少幻觉
- 更频繁地准确回答用户查询
- 从本质上讲,这简化了LLM的工作
总而言之,问答模型成功回答用户查询的数量将显著增加。这是衡量RAG系统表现的一个推荐指标,关于LLM系统评估的更多信息,可以参阅通过自动化LLM评估评测500万份文档。
减少幻觉也是一个极其重要的因素。幻觉是LLM面临的最严重问题之一,其危害性在于它会降低用户对问答系统的信任度,从而使他们不太可能继续使用应用程序。然而,确保LLM既能接收到相关的文档(精确率),又能最大程度地减少不相关文档的数量(召回率),对于最大程度地减少RAG系统产生幻觉至关重要。
减少不相关文档(提高精确率)还能避免上下文冗余(context bloat,即上下文中过多噪音)或甚至上下文投毒(context poisoning,即文档中提供了不正确的信息)等问题。
总结
本文深入探讨了如何优化RAG管线中的文档检索步骤。文章首先强调了文档检索在RAG管线中的核心地位及其优化价值。接着,介绍了传统RAG管线如何通过语义搜索和关键词搜索来获取相关文档。随后,详细阐述了用于提高检索文档精确率和召回率的各种技术,包括上下文检索和LLM文档块验证等。