

之前的文章中,已经详细探讨了如何利用OpenAI API、LangChain和本地文件构建一个简单的RAG(检索增强生成)管道,以及如何高效地对大型文本文件进行分块处理。这些内容涵盖了RAG管道搭建的基础知识,使其能够根据本地文件内容生成响应。
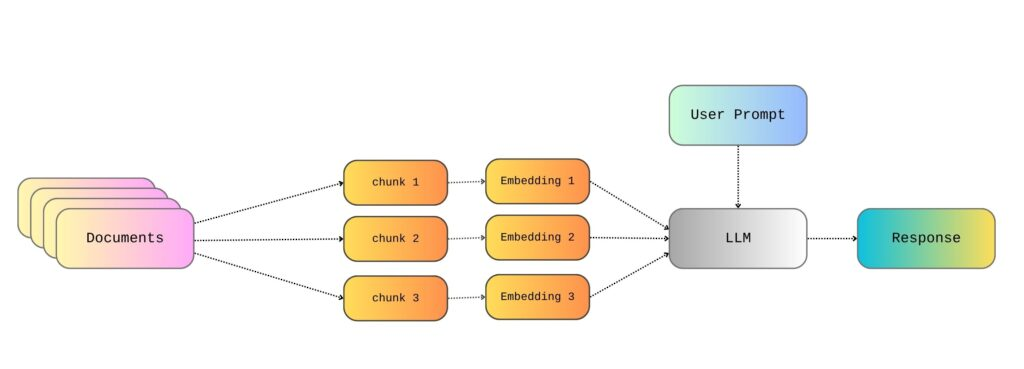
到目前为止,我们已经讨论了如何从存储位置读取文档、将其分割成文本块,并为每个文本块创建嵌入。之后,系统会“神奇地”选择与用户查询相关的嵌入,并生成一个相应的回复。然而,深入理解RAG中检索步骤的实际工作原理至关重要。
因此,本文将更进一步,仔细审视检索机制的运作方式,并进行更详细的分析。与之前的文章一样,本文将继续以公共领域授权、可通过古腾堡计划轻松获取的《战争与和平》文本为例进行讲解。
嵌入究竟是什么?
要理解RAG框架中检索步骤的工作原理,首先必须明白文本是如何被转换并表示为嵌入的。为了让大型语言模型(LLMs)能够处理任何文本,这些文本必须以向量的形式存在,而完成这种转换就需要利用嵌入模型。
嵌入是数据(在本例中为文本)的一种向量表示,它能够捕捉其语义含义。原始文本中的每个词语或句子都被映射到一个高维向量。用于执行这种转换的嵌入模型被设计成使得语义相似的词语或句子在向量空间中彼此靠近。例如,“快乐”(happy)和“愉悦”(joyful)的向量在向量空间中会非常接近,而“悲伤”(sad)的向量则会远离它们。
为了在RAG管道中高效地生成高质量嵌入,需要利用预训练的嵌入模型,例如BERT和GPT。目前存在多种类型的嵌入及其对应的模型。例如:
- 词嵌入(Word Embeddings):在词嵌入中,每个词语都有一个固定的向量,无论其上下文如何。创建此类嵌入的流行模型包括Word2Vec和GloVe。
- 上下文嵌入(Contextual Embeddings):上下文嵌入考虑了词语含义可能随上下文变化的情况。例如,“河岸”(the bank of a river)和“开立银行账户”(opening a bank account)中的“bank”含义就不同。可用于生成上下文嵌入的模型包括BERT、RoBERTa和GPT。
- 句嵌入(Sentence Embeddings):这些嵌入捕捉了整个句子的含义。相应的模型有Sentence-BERT或USE。
无论如何,文本都必须转换成向量才能进行计算。这些向量仅仅是文本的表示形式。换句话说,向量和数字本身并没有固有的意义。相反,它们的价值在于能够以数学形式捕捉词语或短语之间的相似性和关系。
例如,我们可以设想一个由“国王”(king)、“王后”(queen)、“女人”(woman)和“男人”(man)组成的微型词汇表,并为每个词语分配一个任意向量。
king = [0.25, 0.75]
queen = [0.23, 0.77]
man = [0.15, 0.80]
woman = [0.13, 0.82]
然后,我们可以尝试进行一些向量运算,例如:
king - man + woman
= [0.25, 0.75] - [0.15, 0.80] + [0.13, 0.82]
= [0.23, 0.77]
≈ queen
请注意,词语的语义及其之间的关系在映射到向量后得到了保留,这使得我们能够进行各种运算。
因此,嵌入就是这样一种机制——将词语映射到向量,旨在保留词语间的含义和关系,并允许对其进行计算。我们甚至可以在向量空间中可视化这些示例向量,以观察相关词语如何聚集在一起。
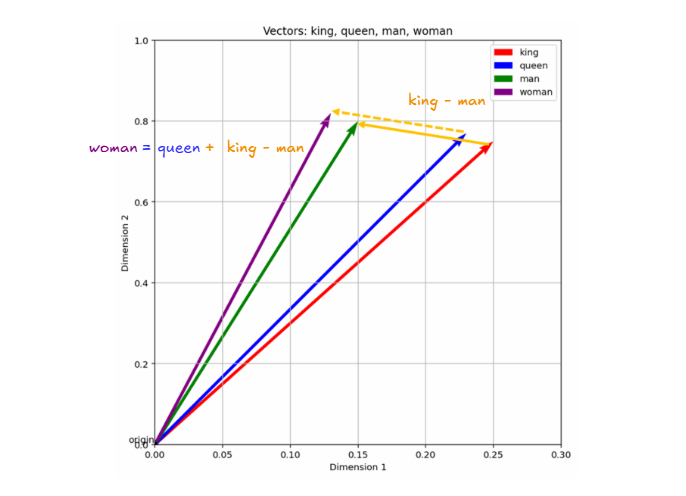
这些简单向量示例与嵌入模型实际生成的向量之间的区别在于,真正的嵌入模型会生成具有数百个维度的向量。二维向量对于理解含义如何映射到向量空间很有帮助,但它们的维度过低,无法捕捉真实语言和词汇的复杂性。这就是为什么实际的嵌入模型处理的维度要高得多,通常是数百甚至数千维。例如,Word2Vec生成300维向量,而BERT Base则生成768维向量。更高的维度使嵌入能够捕捉真实语言的多个层面,例如词义、用法、语法以及词语和短语的上下文。
评估嵌入的相似性
文本被转换成嵌入之后,推理就变成了向量数学。这正是RAG框架中检索步骤能够识别和检索相关文档的关键所在。一旦我们使用嵌入模型将用户的查询和知识库文档都转换为向量,我们就可以利用余弦相似度来计算它们之间的相似程度。
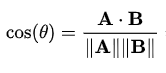
简而言之,余弦相似度是计算两个向量之间夹角的余弦值,其取值范围为-1到1。具体来说:
- 1表示向量在语义上完全相同(例如,“汽车”和“automobile”)。
- 0表示向量之间没有语义关系(例如,“香蕉”和“正义”)。
- -1表示向量在语义上完全相反(例如,“热”和“冷”)。
然而,在实际应用中,嵌入模型中接近-1的余弦相似度值极为罕见。这是因为即使是语义上相反的词语(例如“热”和“冷”),也常常出现在相似的语境中(例如“天气变热了”和“天气变冷了”)。要使余弦相似度达到-1,词语本身及其上下文都需要完全相反——这在自然语言中几乎不会发生。因此,即使是反义词,其嵌入通常在语义上仍然存在一定的接近性。
除了余弦相似度之外,确实存在其他相似度度量,例如点积或欧氏距离。然而,这些度量未经过归一化处理,并且依赖于向量的幅度,这使得它们在比较文本嵌入时不太适用。因此,余弦相似度是量化嵌入之间相似性时最主要的指标。
回到RAG管道,通过计算用户查询嵌入与知识库嵌入之间的余弦相似度,系统可以识别出与用户问题最相似(也即上下文最相关)的文本块,将其检索出来,然后用于生成答案。
查找Top K相似文本块
因此,在获取知识库的嵌入以及用户查询文本的嵌入之后,核心的检索过程便在此展开。我们所做的实质工作是计算用户查询嵌入与知识库中各个文本块嵌入之间的余弦相似度。由此,知识库的每个文本块都会得到一个介于-1到1之间的分数,这个分数表示了该文本块与用户查询的相似程度。
获得相似度分数后,系统会将它们按降序排列,并选择排名最高的K个文本块。这些Top K文本块随后被传递到RAG管道的生成步骤,从而使其能够有效地为用户的查询检索到相关信息。
为了加速这一过程,通常会采用近似最近邻(ANN)搜索技术。ANN能够找到近似最相似的向量,其结果接近于精确搜索的Top N结果,但速度远快于精确搜索方法。当然,精确搜索更为准确;然而,它的计算成本也更高,在处理大规模数据集时,可能难以在实际应用中良好扩展。
此外,还可以对相似度分数应用一个阈值,以过滤掉未达到最低相关性分数的文本块。例如,在某些情况下,只有当文本块的相似度分数超过特定阈值(例如,余弦相似度 > 0.3)时,才会被纳入考虑范围。
那么,安娜·巴甫洛夫娜是谁?
在《战争与和平》的示例中(如之前的文章所示),系统将整部文本分割成多个文本块,并为每个文本块创建相应的嵌入。随后,当用户提交一个查询,例如“安娜·巴甫洛夫娜是谁?”时,系统也会为用户的查询文本创建相应的嵌入。
import os
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
api_key = 'your_api_key'
# initialize LLM
llm = ChatOpenAI(openai_api_key=api_key, model="gpt-4o-mini", temperature=0.3)
# initialize embeddings model
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
# loading documents to be used for RAG
text_folder = "RAG files"
documents = []
for filename in os.listdir(text_folder):
if filename.lower().endswith(".txt"):
file_path = os.path.join(text_folder, filename)
loader = TextLoader(file_path)
documents.extend(loader.load())
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
split_docs = []
for doc in documents:
chunks = splitter.split_text(doc.page_content)
for chunk in chunks:
split_docs.append(Document(page_content=chunk))
documents = split_docs
# create vector database w FAISS
vector_store = FAISS.from_documents(documents, embeddings)
retriever = vector_store.as_retriever()
def main():
print("Welcome to the RAG Assistant. Type 'exit' to quit.
")
while True:
user_input = input("You: ").strip()
if user_input.lower() == "exit":
print("Exiting…")
break
# get relevant documents
relevant_docs = retriever.invoke(user_input)
retrieved_context = "
".join([doc.page_content for doc in relevant_docs])
# system prompt
system_prompt = (
"You are a helpful assistant. "
"Use ONLY the following knowledge base context to answer the user. "
"If the answer is not in the context, say you don't know.
"
f"Context:
{retrieved_context}"
)
# messages for LLM
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input}
]
# generate response
response = llm.invoke(messages)
assistant_message = response.content.strip()
print(f"
Assistant: {assistant_message}
")
if __name__ == "__main__":
main()
在这个脚本中,使用的是LangChain的检索器对象retriever = vector_store.as_retriever(),它默认利用余弦相似度来评估文档嵌入与用户查询的相关性。此外,它默认检索K=4个文档。因此,实质上,这里执行的操作是基于余弦相似度检索出与用户查询最相关的Top K文本块。
然而,LangChain的.as_retriever()方法并不直接显示余弦相似度值——它只返回Top K个相关文本块。因此,为了查看具体的余弦相似度,可以通过调整脚本,使用.similarity_search_with_score()方法替代.as_retriever()。这可以通过在main()函数中添加以下代码段轻松实现:
# REMOVE THIS LINE
retriever = vector_store.as_retriever()
def main():
print("Welcome to the RAG Assistant. Type 'exit' to quit.
")
while True:
user_input = input("You: ").strip()
if user_input.lower() == "exit":
print("Exiting…")
break
# ADD THIS SECTION
# Similarity search with score
results = vector_store.similarity_search_with_score(user_input, k=2)
# Extract documents and cosine similarity scores
print(f"
Cosine Similarities for Top 5 Chunks:
")
for idx, (doc, sim_score) in enumerate(results):
print(f"Chunk {idx + 1}:")
print(f"Cosine Similarity: {sim_score:.4f}")
print(f"Content:
{doc.page_content}
")
# CONTINUE WITH REST OF THE CODE...
# System prompt for LLM generation
retrieved_context = "
".join([doc.page_content for doc, _ in results])
请注意,现在可以明确定义检索的文本块数量K,当前设置为K=2。
最后,我们可以再次提问并获得答案:
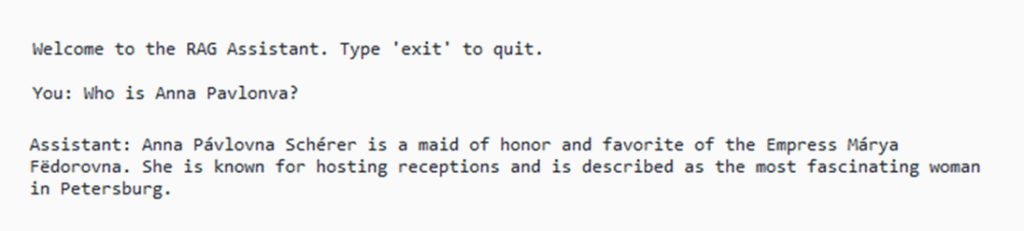
……而现在,我们也能看到生成此答案所依据的文本块,以及它们各自的余弦相似度分数……

显然,不同的参数设置会导致不同的答案。例如,当检索Top K设置为K=2、K=4和K=10时,将会得到略有差异的答案。考虑到分块步骤中使用的其他参数,例如文本块大小和重叠量,很明显,这些参数在从RAG管道获得良好结果方面扮演着至关重要的角色。





