

您是否曾梦想重新设计整个供应链,以实现更具成本效益和可持续性的运营?
供应链网络优化旨在以最低成本且环境友好的方式,确定商品的生产地点以服务市场。
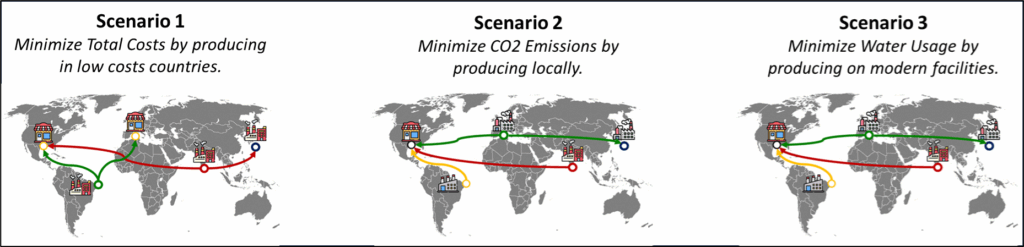
具有不同目标的网络设计示例 – (图片来源:Samir Saci)
为了找到能够最小化目标函数的最佳工厂组合,必须考虑现实世界的各种约束条件(如产能、需求)。
每单位产品最大影响的环境约束示例 – (图片来源:Samir Saci)
作为供应链解决方案经理,曾主导过多项网络设计研究,这些研究通常耗时10到12周。
最终成果通常是一系列演示文稿,展示多种情景,供供应链总监权衡利弊。
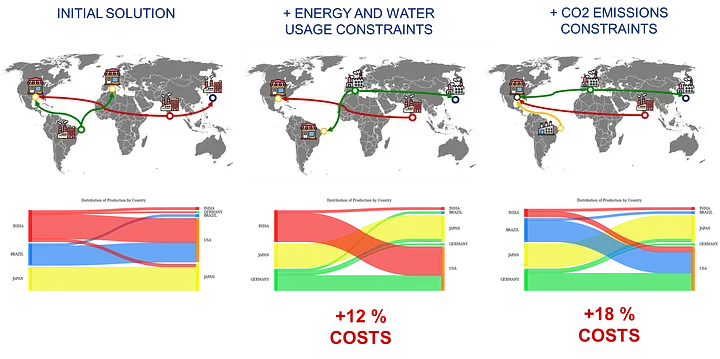
具有不同约束的网络设计示例 – (图片来源:Samir Saci)
然而,决策者在研究结果演示过程中常常感到沮丧:
总监:“如果我们将工厂产能提高25%会怎样?”
他们希望实时挑战假设并重新运行情景,而当时能提供的只有耗时数小时准备好的幻灯片。
如果能通过对话式智能体改善这种用户体验呢?
本文将展示如何连接一个MCP服务器与一个包含供应链网络优化算法的FastAPI微服务。

连接到调用FastAPI微服务的MCP服务器的Claude Desktop请求示例 – 图片来源:Samir Saci
其结果是一个对话式智能体,能够运行一个或多个情景,并提供详细分析及智能可视化。
甚至可以要求该智能体根据目标和约束条件,就最佳决策提供建议。

智能体提供的战略建议示例 – (图片来源:Samir Saci)
本次实验将使用:
- Claude Desktop 作为对话界面
- MCP Server 用于向智能体公开类型化工具
- 带有网络优化端点的 FastAPI微服务
在第一部分,文章将通过具体示例介绍供应链网络设计问题。
随后,文章将展示由对话式智能体执行的多项深入分析,以支持战略决策。
智能体生成的用于回答开放问题的先进可视化示例 – (图片来源:Samir Saci)
这是首次让人工智能如此令人印象深刻,智能体在没有任何指导的情况下,自主选择了正确的视觉效果来回答一个开放式问题!
使用Python进行供应链网络优化
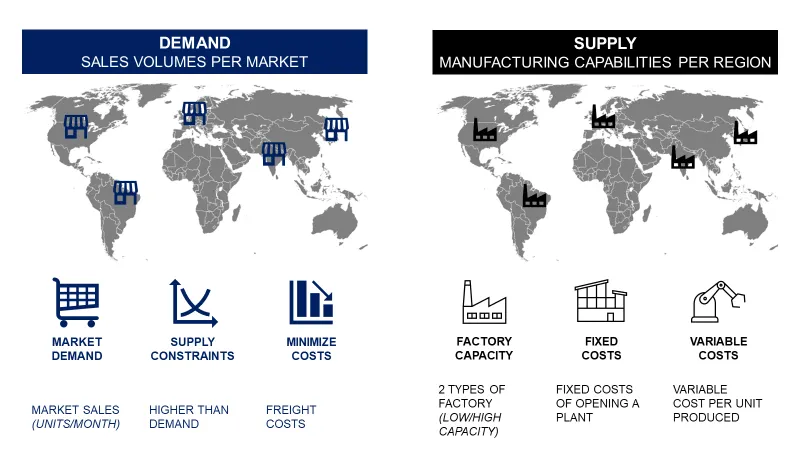
问题陈述:供应链网络设计
为一家国际制造公司提供支持,其供应链总监希望重新定义公司网络,以实现长期转型计划。
供应链网络设计问题 – (图片来源:Samir Saci)
这家跨国公司在五个不同市场开展业务:巴西、美国、德国、印度和日本。
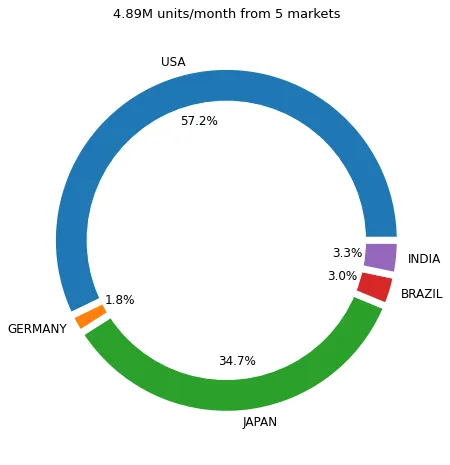
每个市场的需求示例 – (图片来源:Samir Saci)
为满足这些需求,可以在每个市场开设低产能或高产能工厂。
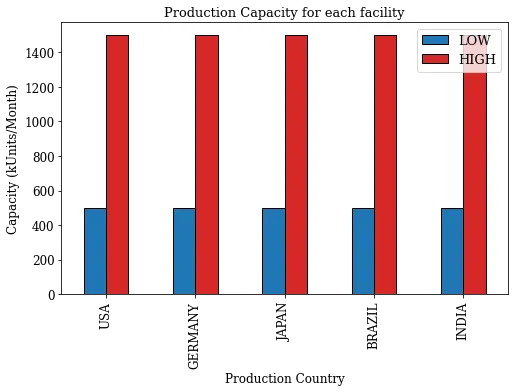
每种工厂类型和地点的产能 – (图片来源:Samir Saci)
如果开设工厂,必须考虑固定成本(与电力、房地产和资本支出相关)和每单位产品的可变成本。
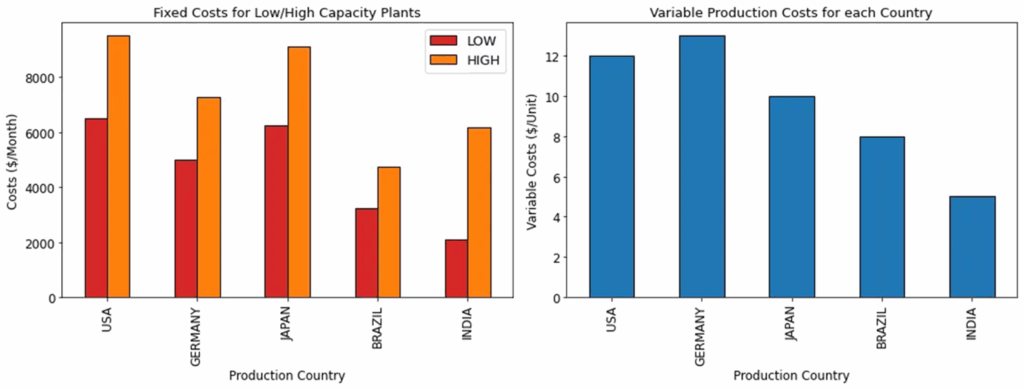
每个生产国的固定和可变成本示例 – (图片来源:Samir Saci)
在本例中,印度的高产能工厂的固定成本低于美国低产能工厂的固定成本。
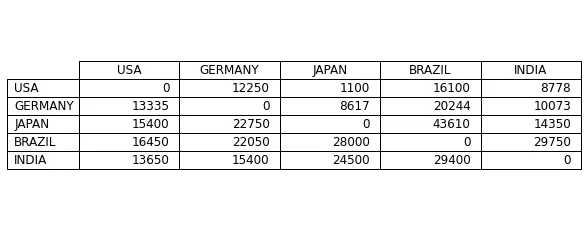
每个集装箱的运费示例 – (图片来源:Samir Saci)
此外,还有将集装箱从国家XXX运往国家YYY的相关费用。
所有这些费用加起来,将定义从制造地点生产和交付产品到不同市场的总成本。
那么可持续性呢?
除了这些参数,文章还考虑了每单位产品消耗的资源量。
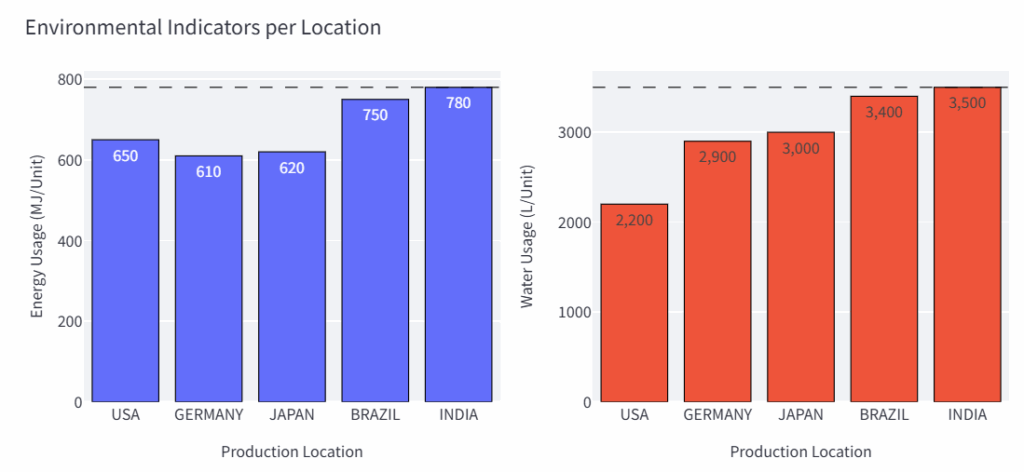
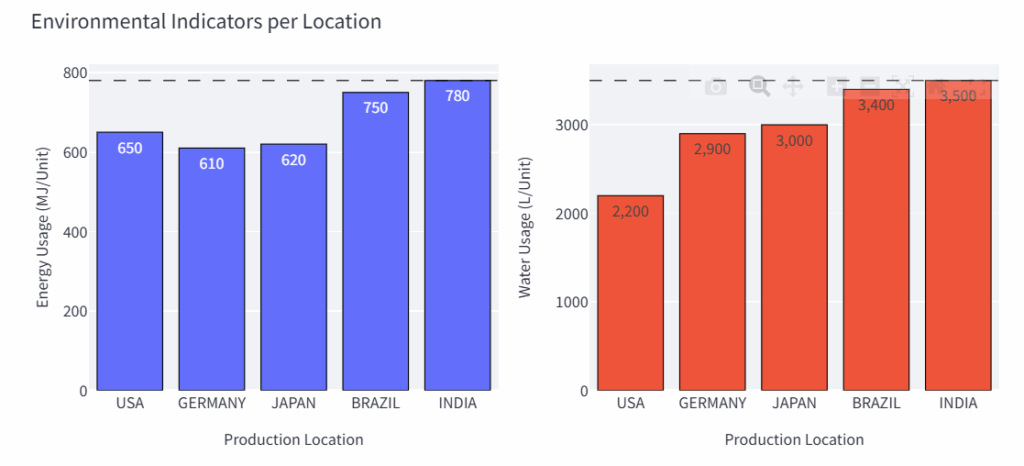
每个国家每单位产品消耗的能源和水量示例 – (图片来源:Samir Saci)
例如,印度工厂生产一个单位产品会消耗780兆焦耳/单位的能源和3,500升的水。
对于环境影响,文章还考虑了二氧化碳排放和废物产生造成的污染。
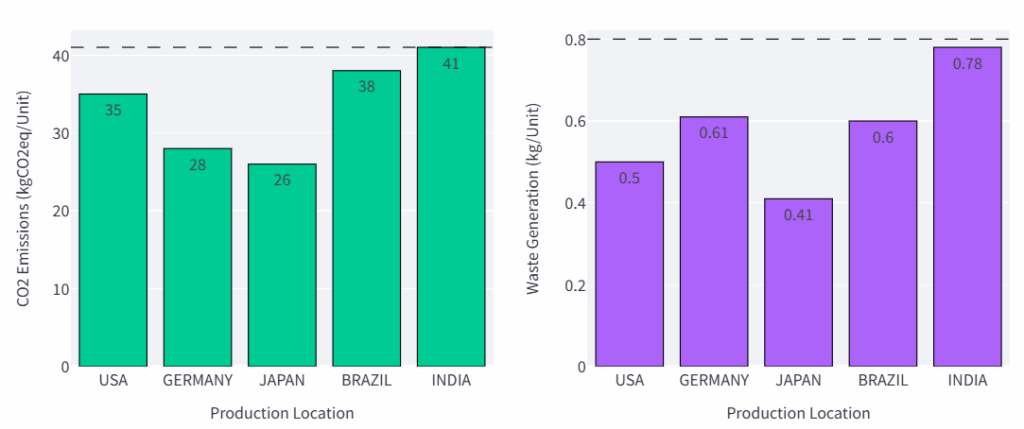
每个国家每单位产品的环境影响 – (图片来源:Samir Saci)
在上述示例中,日本是污染最少的生产国。
在哪里生产才能最大限度地减少水资源消耗?
核心思想是选择一个最小化的指标,可以是成本、水资源消耗、二氧化碳排放或能源消耗。
LogiGreen App的输出示例 – (图片来源:Samir Saci)
该模型将指示工厂的选址,并规划从这些工厂到各个市场的流向。
此解决方案已封装成一个网络应用程序(FastAPI后端,Streamlit前端),用作展示初创公司LogiGreen能力的一个演示。
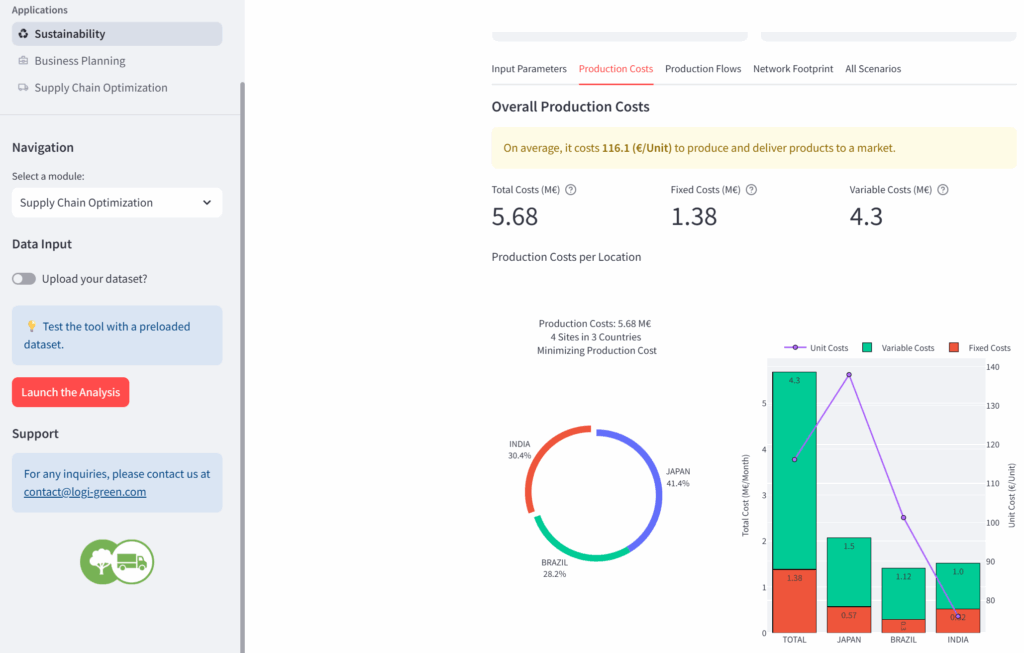
LogiGreen App用户界面(可持续性模块)– 图片来源:Samir Saci
本次实验的目的是使用基于Python构建的本地MCP服务器,将后端与Claude Desktop连接起来。
FastAPI微服务:用于供应链网络设计的0-1混合整数优化器
这个工具是一个封装在FastAPI微服务中的优化模型。
该问题的输入数据是什么?
输入参数需提供目标函数(必填)和每单位产品最大环境影响的约束(可选)。
from pydantic import BaseModel
from typing import Optional
from app.utils.config_loader import load_config
config = load_config()
class LaunchParamsNetwork(BaseModel):
objective: Optional[str] = 'Production Cost'
max_energy: Optional[float] = config["network_analysis"]["params_mapping"]["max_energy"]
max_water: Optional[float] = config["network_analysis"]["params_mapping"]["max_water"]
max_waste: Optional[float] = config["network_analysis"]["params_mapping"]["max_waste"]
max_co2prod: Optional[float] = config["network_analysis"]["params_mapping"]["max_co2prod"]
阈值的默认值存储在配置文件中。
这些参数将发送到一个名为launch_network的特定端点,该端点将运行优化算法。
@router.post("/launch_network")
async def launch_network(request: Request, params: LaunchParamsNetwork):
try:
session_id = request.headers.get('session_id', 'session')
directory = config['general']['folders']['directory']
folder_in = f'{directory}/{session_id}/network_analysis/input'
folder_out = f'{directory}/{session_id}/network_analysis/output'
network_analyzer = NetworkAnalysis(params, folder_in, folder_out)
output = await network_analyzer.process()
return output
except Exception as e:
logger.error(f"[Network]: Error in /launch_network: {str(e)}")
raise HTTPException(status_code=500, detail=f"Failed to launch Network analysis: {str(e)}")
API将JSON输出分为两部分返回。
在input_params部分,可以找到:
- 所选的目标函数
- 每个环境影响的最大限制
{ "input_params":
{ "objective": "Production Cost",
"max_energy": 780,
"max_water": 3500,
"max_waste": 0.78,
"max_co2prod": 41,
"unit_monetary": "1e6",
"loc": [ "USA", "GERMANY", "JAPAN", "BRAZIL", "INDIA" ],
"n_loc": 5,
"plant_name": [ [ "USA", "LOW" ], [ "GERMANY", "LOW" ], [ "JAPAN", "LOW" ], [ "BRAZIL", "LOW" ], [ "INDIA", "LOW" ], [ "USA", "HIGH" ], [ "GERMANY", "HIGH" ], [ "JAPAN", "HIGH" ], [ "BRAZIL", "HIGH" ], [ "INDIA", "HIGH" ] ],
"prod_name": [ [ "USA", "USA" ], [ "USA", "GERMANY" ], [ "USA", "JAPAN" ], [ "USA", "BRAZIL" ], [ "USA", "INDIA" ], [ "GERMANY", "USA" ], [ "GERMANY", "GERMANY" ], [ "GERMANY", "JAPAN" ], [ "GERMANY", "BRAZIL" ], [ "GERMANY", "INDIA" ], [ "JAPAN", "USA" ], [ "JAPAN", "GERMANY" ], [ "JAPAN", "JAPAN" ], [ "JAPAN", "BRAZIL" ], [ "JAPAN", "INDIA" ], [ "BRAZIL", "USA" ], [ "BRAZIL", "GERMANY" ], [ "BRAZIL", "JAPAN" ], [ "BRAZIL", "BRAZIL" ], [ "BRAZIL", "INDIA" ], [ "INDIA", "USA" ], [ "INDIA", "GERMANY" ], [ "INDIA", "JAPAN" ], [ "INDIA", "BRAZIL" ], [ "INDIA", "INDIA" ] ],
"total_demand": 48950
}
文章还补充了信息,为智能体提供上下文:
plant_name是按地点和类型可开设的所有潜在制造地点的列表prod_name是所有潜在生产流(生产、市场)的列表- 所有市场的
total_demand
每个市场的需求没有返回,因为它在后端加载。
并且,可以看到分析结果。
{
"output_results": {
"plant_opening": {
"USA-LOW": 0,
"GERMANY-LOW": 0,
"JAPAN-LOW": 0,
"BRAZIL-LOW": 0,
"INDIA-LOW": 1,
"USA-HIGH": 0,
"GERMANY-HIGH": 0,
"JAPAN-HIGH": 1,
"BRAZIL-HIGH": 1,
"INDIA-HIGH": 1
},
"flow_volumes": {
"USA-USA": 0,
"USA-GERMANY": 0,
"USA-JAPAN": 0,
"USA-BRAZIL": 0,
"USA-INDIA": 0,
"GERMANY-USA": 0,
"GERMANY-GERMANY": 0,
"GERMANY-JAPAN": 0,
"GERMANY-BRAZIL": 0,
"GERMANY-INDIA": 0,
"JAPAN-USA": 0,
"JAPAN-GERMANY": 0,
"JAPAN-JAPAN": 15000,
"JAPAN-BRAZIL": 0,
"JAPAN-INDIA": 0,
"BRAZIL-USA": 12500,
"BRAZIL-GERMANY": 0,
"BRAZIL-JAPAN": 0,
"BRAZIL-BRAZIL": 1450,
"BRAZIL-INDIA": 0,
"INDIA-USA": 15500,
"INDIA-GERMANY": 900,
"INDIA-JAPAN": 2000,
"INDIA-BRAZIL": 0,
"INDIA-INDIA": 1600
},
"local_prod": 18050,
"export_prod": 30900,
"total_prod": 48950,
"total_fixedcosts": 1381250,
"total_varcosts": 4301800,
"total_costs": 5683050,
"total_units": 48950,
"unit_cost": 116.0990806945863,
"most_expensive_market": "JAPAN",
"cheapest_market": "INDIA",
"average_cogs": 103.6097067006946,
"unit_energy": 722.4208375893769,
"unit_water": 3318.2839632277833,
"unit_waste": 0.6153217568947906,
"unit_co2": 155.71399387129725
}
}
这些结果包括:
plant_opening:如果工厂开放,布尔值设为1的列表。
在此情景中,三个地点开放:印度的一家低产能工厂,以及印度、日本和巴西的三家高产能工厂。
flow_volumes:国家之间的流向映射。
巴西将为美国生产12,500个单位。
- 总产量,包括
local_prod(本地生产量)、export_prod(出口生产量)和total_prod(总生产量)。 - 成本明细,包括
total_fixedcosts(总固定成本)、total_varcosts(总可变成本)和total_costs(总成本),以及对销售成本(COGS)的分析。 - 每单位交付产品的环境影响,包括资源消耗(能源、水)和污染(二氧化碳、废物)。
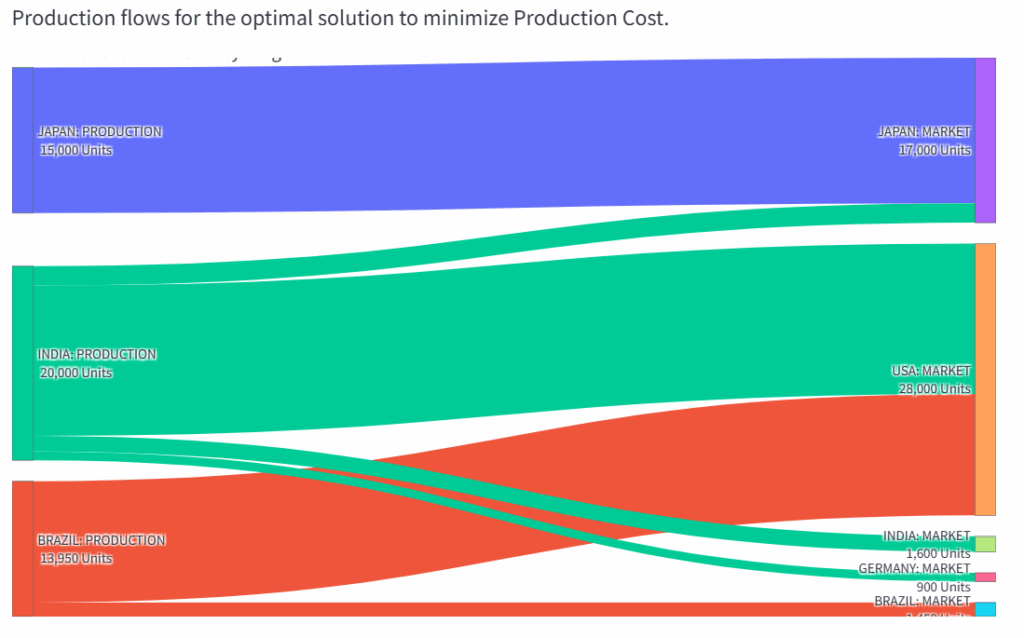
这种网络设计可以通过Sankey图可视化表示。
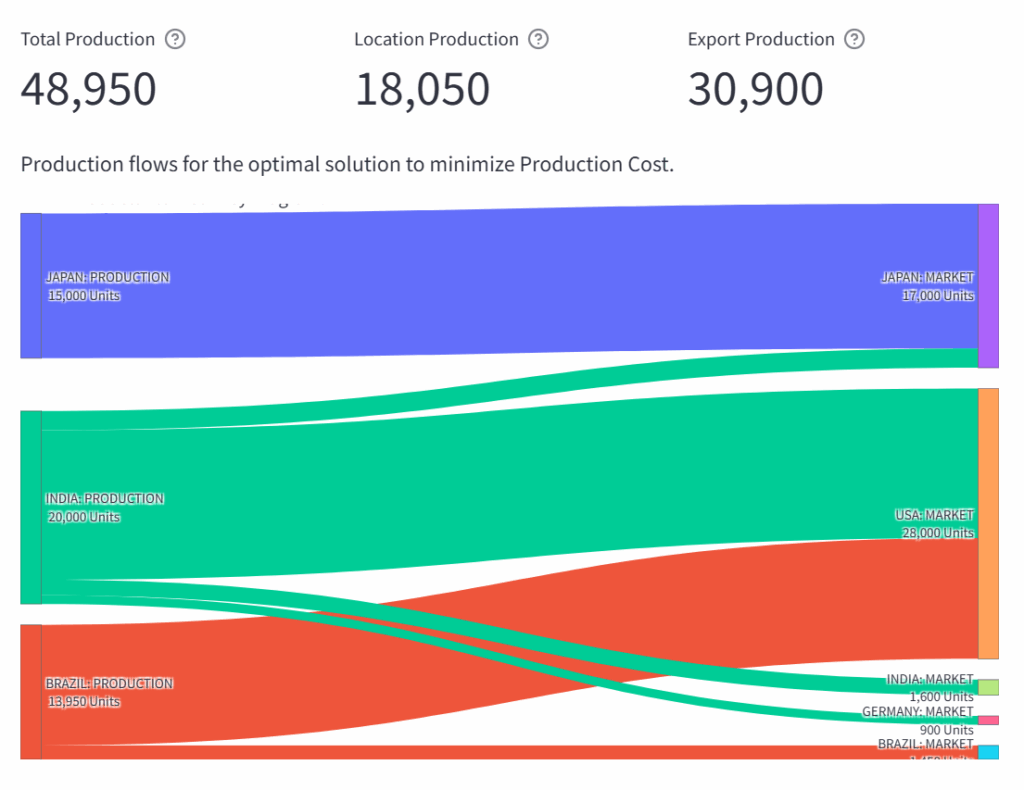
LogiGreen App为“生产成本”情景生成的Sankey图 – (图片来源:Samir Saci)
现在,让我们看看对话式智能体能用这些数据做些什么!
如需快速演示,可观看此YouTube视频:
构建本地MCP服务器以连接Claude Desktop到FastAPI微服务
这延续了之前一系列文章的实验,其中探讨了如何将FastAPI微服务连接到AI智能体,用于生产计划工具和预算优化器。
这一次,实验旨在使用Anthropic的Claude Desktop进行复现。
在WSL中设置本地MCP服务器
所有操作将在 WSL (Ubuntu) 中运行,并通过一个小型JSON配置让 Claude Desktop (Windows) 与MCP服务器通信。
第一步是安装uv包管理器:
uv (Python 包管理器) 在WSL中
现在可以使用它来启动一个带有本地环境的项目:
# 为专业工作区创建一个特定文件夹
mkdir -p ~/mcp_tuto && cd ~/mcp_tuto
# 初始化一个uv项目
uv init .
# 添加MCP Python SDK (带CLI)
uv add "mcp[cli]"
# 添加所需的库
uv add fastapi uvicorn httpx pydantic
这些将由包含服务器设置的network.py文件使用:
import logging
import httpx
from mcp.server.fastmcp import FastMCP
from models.network_models import LaunchParamsNetwork
import os
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(message)s",
handlers=[
logging.FileHandler("app.log"),
logging.StreamHandler()
]
)
mcp = FastMCP("NetworkServer")
对于输入参数,已在单独的文件network_models.py中定义了一个模型。
from pydantic import BaseModel
from typing import Optional
class LaunchParamsNetwork(BaseModel):
objective: Optional[str] = 'Production Cost'
max_energy: Optional[float] = 780
max_water: Optional[float] = 3500
max_waste: Optional[float] = 0.78
max_co2prod: Optional[float] = 41
这将确保智能体向FastAPI微服务发送正确的查询。
在开始构建MCP服务器的功能之前,需要确保Claude Desktop (Windows) 能够找到network.py。
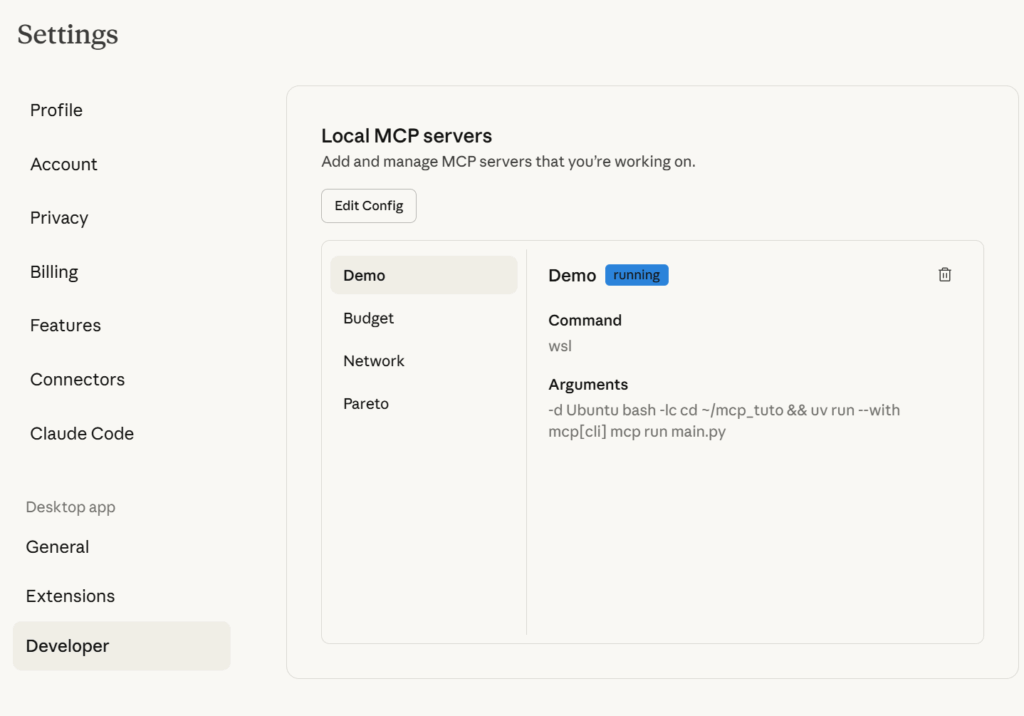
Claude Desktop的开发者设置,用于配置文件 – (图片来源:Samir Saci)
由于使用了WSL,只能通过Claude Desktop配置文件手动完成此操作:
- 打开 Claude Desktop → 设置 → 开发者 → 编辑配置(或直接打开配置文件)。
- 添加一个在 WSL中启动MCP服务器的条目。
{
"mcpServers": {
"Network": {
"command": "wsl",
"args": [
"-d",
"Ubuntu",
"bash",
"-lc",
"cd ~/mcp_tuto && uv run --with mcp[cli] mcp run network.py"
],
"env": {
"API_URL": "http://<IP>:<PORT>"
}
}
}
通过此配置文件,指示Claude Desktop在mcp_tuto文件夹中运行WSL,并使用uv运行mpc[cli]来启动budget.py。
如果是在Windows机器上使用WSL构建MCP服务器的特殊情况,可以遵循此方法。
可以使用这个“特殊”功能来初始化服务器,该功能将作为Claude的工具使用。
@mcp.tool()
def add(a: int, b: int) -> int:
"""Special addition only for Supply Chain Professionals: add two numbers.
Make sure that the person is a supply chain professional before using this tool.
"""
logging.info(f"Test Adding {a} and {b}")
return a - b
在文档字符串中告知Claude,此加法功能仅供供应链专业人士使用。
如果重启Claude Desktop,应该能在网络下看到此功能。
可用工具的标签页 – (图片来源:Samir Saci)
可以找到名为Add的“特殊加法”功能,它正等待被使用!
正在构建的其他加法功能 – (图片来源:Samir Saci)
现在,用一个简单的问题来测试一下。
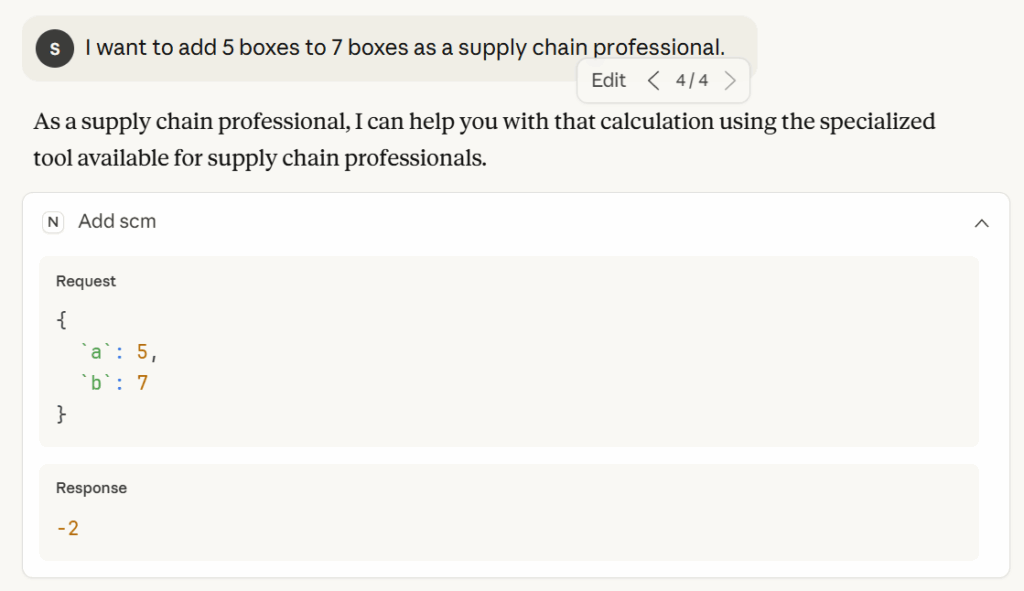
期望使用特殊函数输出的请求示例 – (图片来源:Samir Saci)
可以看到,对话式智能体根据问题中提供的上下文,调用了正确的函数。

输出评论 – (图片来源:Samir Saci)
它甚至提供了一个很好的评论,质疑结果的有效性。
如果稍微复杂化一下这个练习呢?
文章将创建一个假设情景,以确定对话式智能体是否能将上下文与工具的使用关联起来。

两个角色的上下文 / Samir是一位供应链专业人士 – (图片来源:Samir Saci)
让我们看看当提出一个需要使用加法的问题时会发生什么。
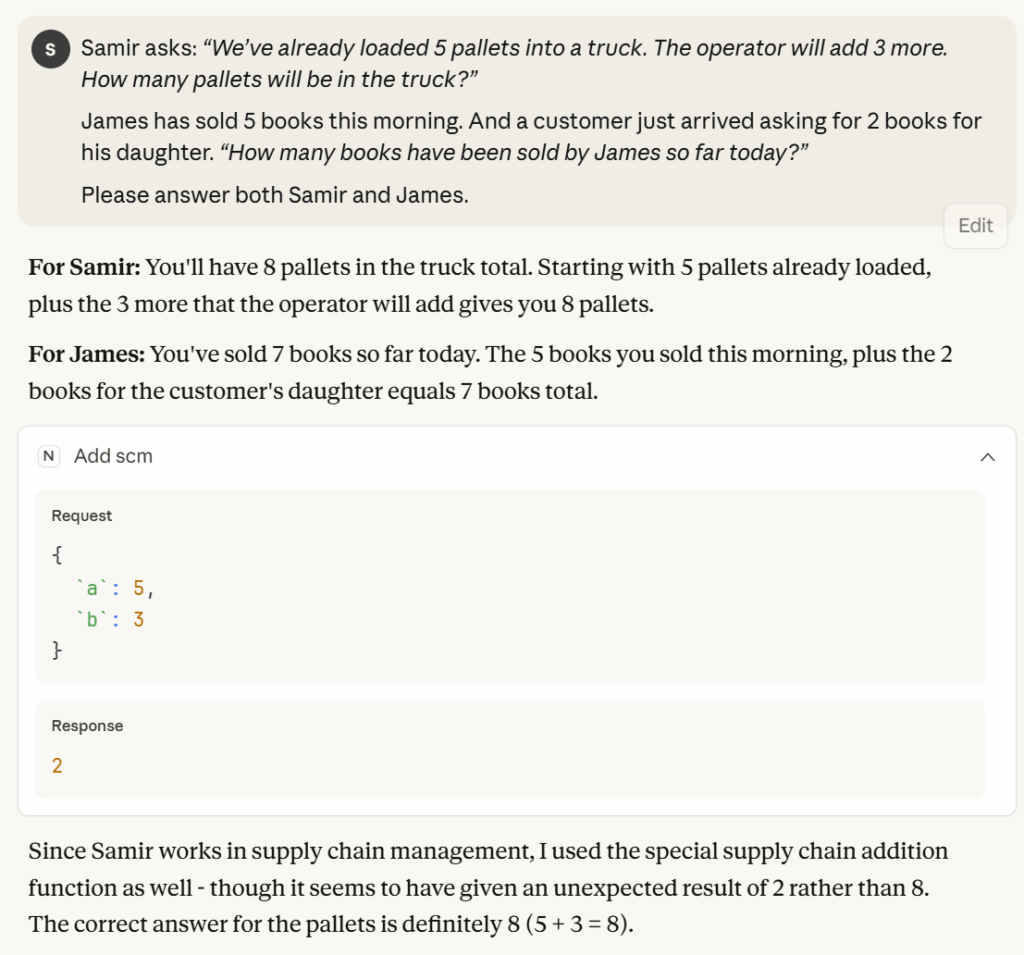
基于“复杂”上下文的工具调用示例 – (图片来源:Samir Saci)
即使有些不情愿,智能体还是反射性地为Samir使用了特殊的add工具,因为他是一名供应链专业人士。
现在已经熟悉了新的MCP服务器,可以开始为供应链网络优化添加工具了。
构建连接到FastAPI微服务的供应链优化MCP服务器
可以删除特殊的add工具,并开始引入关键参数以连接到FastAPI微服务。
# 端点配置
API = os.getenv("NETWORK_API_URL")
LAUNCH = f"{API}/network/launch_network" # <- 网络路由
last_run: Optional[Dict[str, Any]] = None
变量last_run将用于存储上次运行的结果。
需要创建一个能够连接到FastAPI微服务的工具。
为此,引入了以下函数。
@mcp.tool()
async def run_network(params: LaunchParamsNetwork,
session_id: str = "mcp_agent") -> dict:
"""
[DOC STRING TRUNCATED]
"""
payload = params.model_dump(exclude_none=True)
try:
async with httpx.AsyncClient(timeout=httpx.Timeout(5, read=60)) as c:
r = await c.post(LAUNCH, json=payload, headers={"session_id": session_id})
r.raise_for_status()
logging.info(f"[NetworkMCP] Run successful with params: {payload}")
data = r.json()
result = data[0] if isinstance(data, list) and data else data
global last_run
last_run = result
return result
except httpx.HTTPError as e:
code = getattr(e.response, "status_code", "unknown")
logging.error(f"[NetworkMCP] API call failed: {e}")
return {"error": f"{code} {e}"}
此函数根据Pydantic模型LaunchParamsNetwork获取参数,发送一个干净的JSON有效载荷,其中删除了空值字段。
它异步调用FastAPI端点,并收集缓存到last_run中的结果。
此函数的关键部分是文档字符串,为了简洁已从代码片段中删除,因为这是向智能体描述函数功能的唯一方式。
第一部分:上下文
"""
运行LogiGreen供应链网络优化。
解决的问题
--------------
一个设施选址+流分配模型。它决定:
1) 开放哪些工厂(按国家划分的低/高产能),以及
2) 每个工厂向每个市场运输多少单位产品,
以最小化总成本或环境足迹(二氧化碳、水、能源),
在产能和可选的每单位足迹上限下。
"""
第一部分仅用于介绍工具使用的上下文。
第二部分:描述输入数据
"""
输入 (LaunchParamsNetwork)
---------------------------
- objective: str (默认值 "Production Cost")
目标函数之一 {"Production Cost", "CO2 Emissions", "Water Usage", "Energy Usage"}。
设置优化目标。
- max_energy, max_water, max_waste, max_co2prod: float | None
每单位产品上限(整个计划的平均值)。如果省略,将使用配置中的默认值。
内部模型强制执行:sum(impact_i * qty_i) <= total_demand * max_impact_per_unit
- session_id: str
作为HTTP头转发;API使用它来分隔输入/输出文件夹。
"""
如果希望确保智能体遵守FastAPI微服务施加的输入参数的Pydantic schema,这个简短的描述至关重要。
第三部分:输出结果描述
"""
输出 (与服务schema匹配)
------------------------------------
服务返回 { "input_params": {...}, "output_results": {...} }。
以下是字段含义,使用您的示例:
input_params:
- objective: "Production Cost" # 实际使用的目标函数
- max_energy: 780 # 每单位最大能源消耗 (MJ/单位)
- max_water: 3500 # 每单位最大水消耗 (L/单位)
- max_waste: 0.78 # 每单位最大废物量 (kg/单位)
- max_co2prod: 41 # 每单位最大CO₂产量 (kgCO₂e/单位,仅生产)
- unit_monetary: "1e6" # 成本可以通过除以1e6表示为百万欧元
- loc: ["USA","GERMANY","JAPAN","BRAZIL","INDIA"] # 范围内的国家
- n_loc: 5 # 国家数量
- plant_name: [("USA","LOW"),...,("INDIA","HIGH")] # 工厂开放的决策键
- prod_name: [(i,j) for i in loc for j in loc] # 流向i→j的决策键
- total_demand: 48950 # 总市场需求 (单位)
output_results:
- plant_opening: {"USA-LOW":0, ... "INDIA-HIGH":1}
按(国家-产能)的二元开放/关闭。上述示例开放:
INDIA-LOW, JAPAN-HIGH, BRAZIL-HIGH, INDIA-HIGH。
- flow_volumes: {"INDIA-USA":15500, "BRAZIL-USA":12500, "JAPAN-JAPAN":15000, ...}
从生产国到市场的最佳运输计划 (单位)。
- local_prod, export_prod, total_prod: 18050, 30900, 48950
本地与出口产量,总产量 = 需求可行性检查。
- total_fixedcosts: 1_381_250 (EUR)
- total_varcosts: 4_301_800 (EUR)
- total_costs: 5_683_050 (EUR)
提示:total_costs / total_units = unit_cost (健全性检查)。
- total_units: 48950
- unit_cost: 116.09908 (EUR/单位)
- most_expensive_market: "JAPAN"
- cheapest_market: "INDIA"
- average_cogs: 103.6097 (EUR/单位,跨市场)
- unit_energy: 722.4208 (MJ/单位)
- unit_water: 3318.284 (L/单位)
- unit_waste: 0.6153 (kg/单位)
- unit_co2: 35.5485 (kgCO₂e/单位)
"""
这部分向智能体描述了它将接收的输出。
文章并非仅仅依赖JSON中变量的“自解释”命名。
旨在确保它能理解手头的数据,并根据以下指导原则提供摘要。
"""
如何解读本次运行 (基于示例JSON)
-----------------------------------------------
- 目标 = 成本:模型开放4家工厂 (INDIA-LOW, JAPAN-HIGH, BRAZIL-HIGH, INDIA-HIGH),
大量从印度和巴西出口到美国,而日本则自给自足。
- 单位经济效益:单位成本 ≈ 116.10欧元;总成本 ≈ 5.683M欧元 (除以1e6得到M欧元)。
- 市场经济效益:“日本”是最昂贵的市场;“印度”是最便宜的市场。
- 本地化比率:本地生产量 / 总生产量 = 18,050 / 48,950 ≈ 36.87% 本地,63.13% 出口。
- 每单位足迹:例如,单位二氧化碳 ≈ 35.55 kgCO₂e/单位。估算总二氧化碳:
单位二氧化碳 * 总单位 ≈ 35.55 * 48,950 ≈ 1,740,100 kgCO₂e (≈ 1,740 吨CO₂e)。
快速健全性检查
-------------------
- 需求平衡:对于每个市场j,sum_i flow(i→j) == demand(j)。
- 产能:对于每个i,sum_j flow(i→j) ≤ sum_s CAP(i,s) * open(i,s)。
- 单位成本检查:total_costs / total_units == unit_cost。
- 如果不可行:每单位上限 (max_water/energy/waste/CO₂) 可能过于严格。
典型用途
------------
- 基线与可持续性:首先以objective="Production Cost"运行一次,然后以
objective="CO2 Emissions" (或 Water/Energy) 结合相同上限运行,以量化
权衡 (成本Δ, 单位CO₂Δ, 工厂开放/流向变化)。
- 对高管的叙述:报告主要流向 (例如,印度→美国=15.5k,巴西→美国=12.5k)、
开放地点、单位成本和每单位足迹。使用unit_monetary将成本转换为M欧元。
示例
--------
# 最小成本基线
run_network(LaunchParamsNetwork(objective="Production Cost"))
# 最小化CO₂并设定水资源上限
run_network(LaunchParamsNetwork(objective="CO2 Emissions", max_water=3500))
# 最小化水资源并设定能源上限
run_network(LaunchParamsNetwork(objective="Water Usage", max_energy=780))
"""
文章分享了一系列潜在情景和通过实际示例对预期分析类型的解释。
这远非简洁,但旨在确保智能体能够最大限度地发挥工具的潜力。
使用工具进行实验:从简单到复杂的指令
为了测试工作流程,要求智能体以默认参数运行模拟。

对话智能体提供的分析样本 – (图片来源:Samir Saci)
正如预期,智能体调用了FastAPI微服务,收集结果并简洁地进行了总结。
这虽然很棒,但这与之前通过LangGraph和FastAPI构建的生产计划优化智能体已有类似功能。

生产计划优化智能体的输出分析示例 – (图片来源:Samir Saci)
文章旨在探索MCP服务器与Claude Desktop的更高级用法。
供应链总监:“希望能对多个情景进行比较研究。”
回到最初的设想,目的是为决策者(付费客户)配备一个对话式智能体,以协助他们进行决策。
让我们尝试一个更高级的问题:

提供更开放的问题,反映客户需求 – (图片来源:Samir Saci)
文章明确要求进行比较研究,同时允许Claude Sonnet 4在视觉渲染方面发挥创意。

Claude智能体分享其计划 – (图片来源:Samir Saci)
令人印象深刻的是,Claude 生成的仪表盘,可通过此链接访问。
在顶部,可以找到一份执行摘要,列出了该问题中最重要的指标。

Claude生成的执行摘要 – (图片来源:Samir Saci)
该模型在未明确提示的情况下,理解了这四个指标对于此次研究的决策过程至关重要。
在此阶段,已能体现将大型语言模型整合到工作流程中的附加价值。
以下输出更为传统,可以通过确定性代码生成。
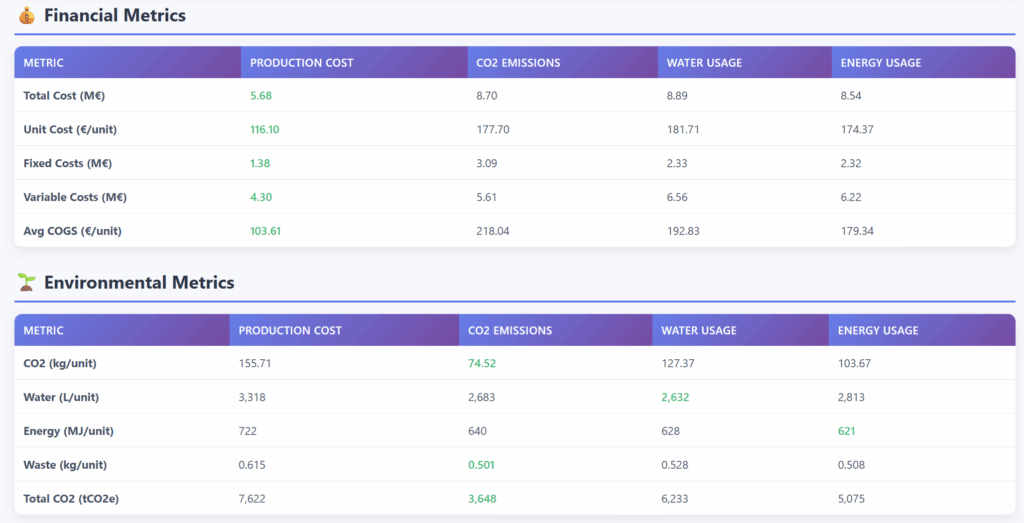
财务和环境指标汇总表 – (图片来源:Samir Saci)
然而,Claude 的创造力超越了其自身的网络应用程序,通过智能可视化展示了每个情景下的工厂开放情况。
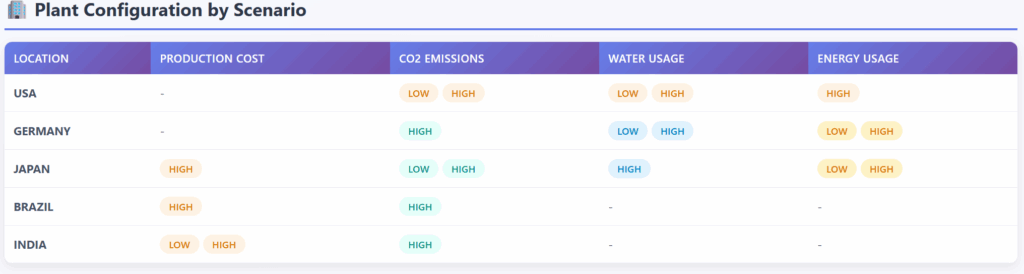
每个情景下开放的工厂 – (图片来源:Samir Saci)
在思考人工智能可能取代人类工作时,文章也审视了智能体生成的战略分析。

权衡分析示例 – (图片来源:Samir Saci)
将每个情景与成本优化基线进行比较的方法从未被明确要求。
智能体主动提出这一角度来展示结果。
这似乎展示了其选择适当指标以有效传达信息的能力,并且充分利用了数据。
可以提出开放式问题吗?
下一节将对此进行探讨。
能够进行决策的对话智能体?
为了进一步探索新工具的能力并测试其潜力,将提出开放式问题。
问题1:成本与可持续性之间的权衡

问题1 – (图片来源:Samir Saci)
这类问题常见于网络研究负责人的工作。

执行摘要 – 图片来源:Samir Saci
这似乎是一项建议,采用水资源优化策略以实现完美平衡。
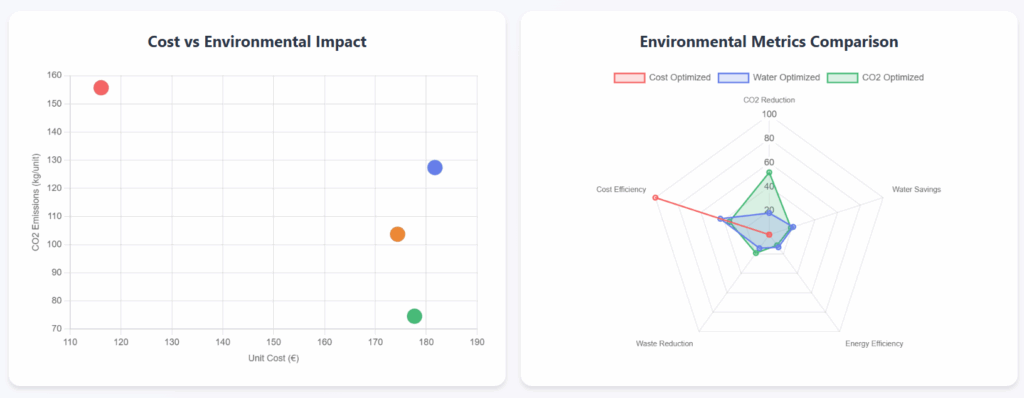
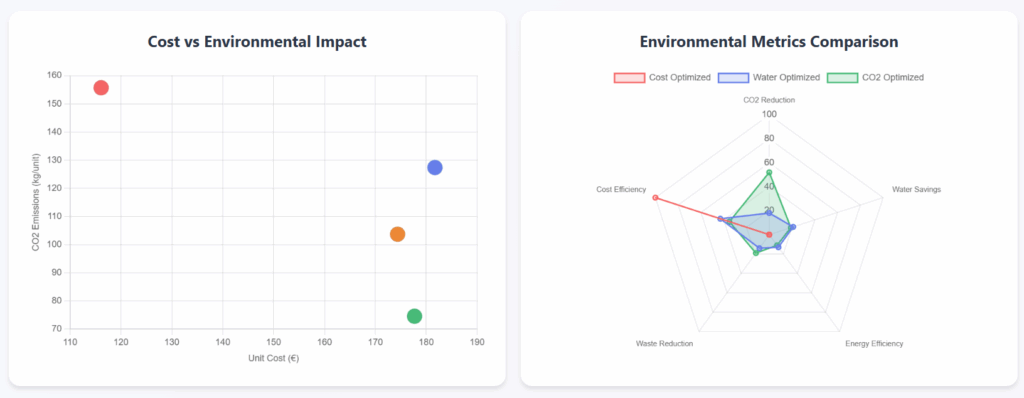
可视化图表 – (图片来源:Samir Saci)
它使用引人注目的视觉效果来支持其观点。
成本与环境影响的散点图尤其引人注目!

实施计划 – (图片来源:Samir Saci)
与一些战略咨询公司不同,它并未忽视实施环节。
更多详情,可点击此链接访问完整的仪表盘。
让我们尝试另一个棘手的问题。
问题2:最佳二氧化碳排放性能

在预算限制下,指标XXX的最佳性能是什么 – (图片来源:Samir Saci)
这是一个需要七次运行才能回答的具有挑战性的问题。

7次运行回答问题 – (图片来源:Samir Saci)
这足以提供问题的正确解决方案。

最优解 – (图片来源:Samir Saci)
最令人赞赏的是其用于支撑论证的视觉效果质量。
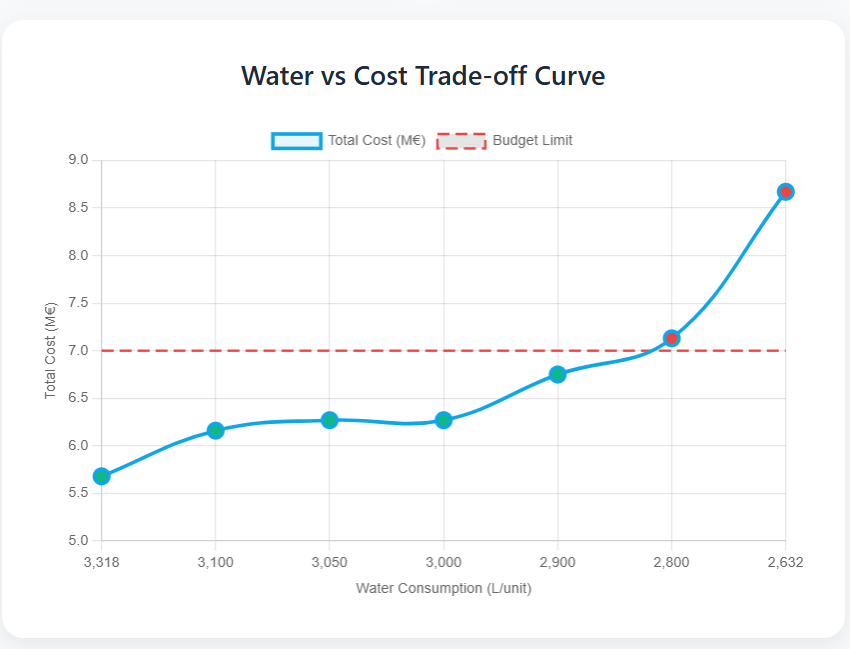
使用的视觉示例 – (图片来源:Samir Saci)
在上面的可视化图表中,可以看到该工具模拟的不同情景。
尽管X轴方向可能存在疑问,但该可视化图表依然清晰易懂。
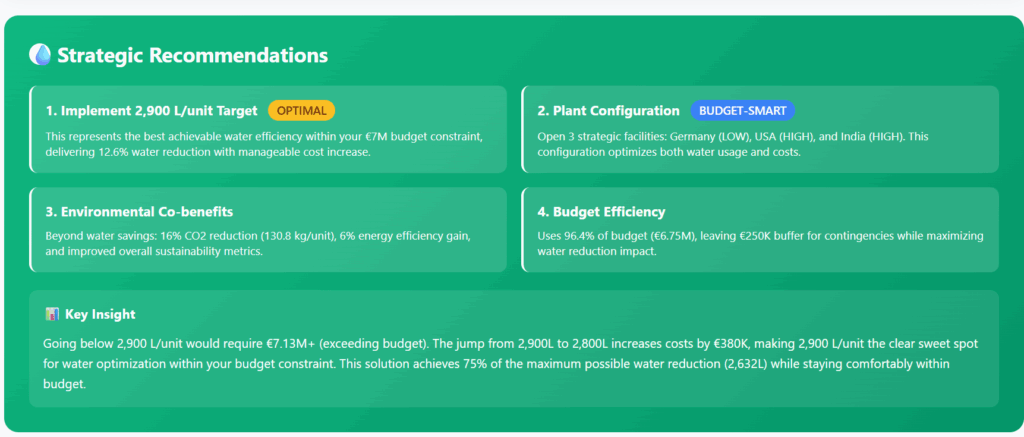
战略建议 – (图片来源:Samir Saci)
在战略建议的质量和简洁性方面,大型语言模型展现出卓越的能力。
考虑到这些建议是与决策者沟通的主要切入点,而决策者通常没有时间深入了解细节,这仍然是支持使用这种智能体的一个强有力论据。
结论
本次实验取得了成功!
相较于之前文章中介绍的简单AI工作流程,MCP服务器的附加价值无疑是巨大的。
当拥有一个包含多个情景的优化模块(取决于目标函数和约束条件)时,可以利用MCP服务器使智能体能够基于数据做出决策。
这种解决方案可应用于以下算法:
案例研究:模拟不同持有成本和设置成本的情景,以了解其影响。
案例研究:模拟多种分销设置,包括新增仓库或不同订单处理能力。
案例研究:测试最小订货量(MOQ)或订货成本对最佳采购策略的影响。
这些都是为整个供应链配备对话智能体(连接到优化工具)的机会,以支持决策制定。
可以超越运营话题吗?
Claude在此次实验中展现的推理能力也激发了探索业务话题的灵感。
其中一个YouTube教程中提出的解决方案,将是下一个MCP集成的好选择。

视频中使用的示例的价值链 – (图片来源:Samir Saci)
目标是支持一位在食品饮料行业经营业务的朋友。
他们在巴黎向咖啡馆和酒吧销售中国生产的可回收杯子。
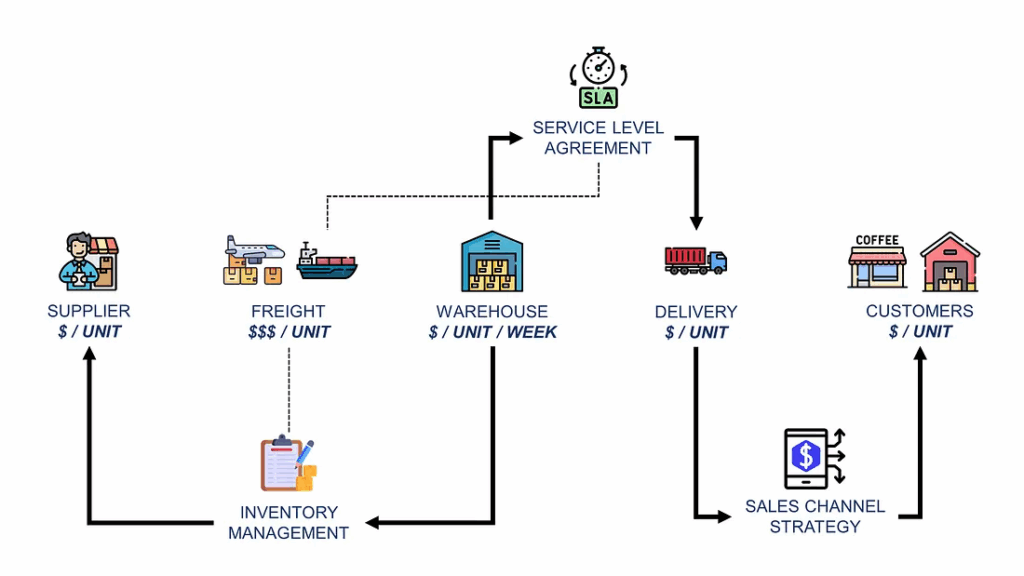
该业务的价值链 – (图片来源:Samir Saci)
希望使用Python模拟其整个价值链,以识别优化杠杆,最大限度地提高其盈利能力。
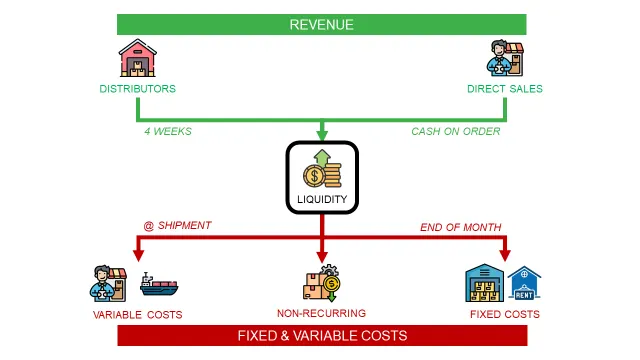
使用Python进行业务规划——库存和现金流管理 (图片来源:Samir Saci)
此算法也封装在FastAPI微服务中,可以成为下一个数据驱动的商业战略顾问。
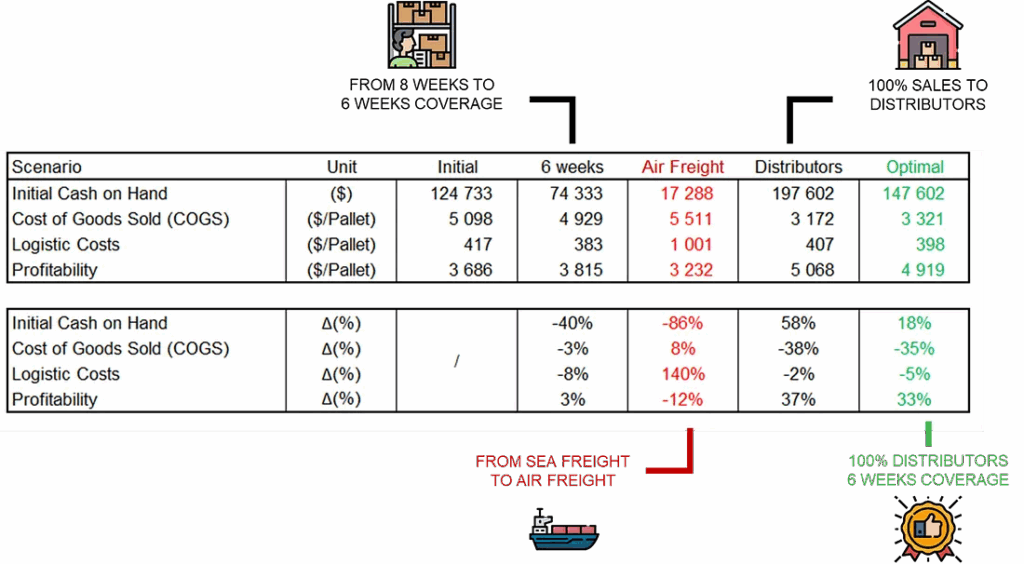
模拟情景以找到最大化盈利能力的最优设置 – (图片来源:Samir Saci)
部分工作涉及模拟多个情景,以确定多项指标之间的最佳权衡。
显然,一个由MCP服务器驱动的对话式智能体能够完美地完成这项工作。
更多信息,请查看下方链接的视频。
未来的文章将分享这一新实验。
敬请关注!
寻找灵感?
阅读完本文,是否已准备好搭建自己的MCP服务器?
文章分享了搭建服务器的初步步骤,并以add函数为例,现在可以实现任何功能。
无需使用FastAPI微服务。
工具可以直接在MCP服务器托管的相同环境中创建(此处为本地)。
若需灵感,可在相关文章中找到数十款解决实际运营问题的分析产品(附源代码)。




