

引言
推荐系统能够为用户生成智能建议,有效筛选出相关内容。本文将探讨如何利用 PostgreSQL、FastAPI 和 Render 构建并部署一个动态视频游戏推荐系统。该系统根据用户已互动的游戏,为其推荐新的游戏。其目标是提供一个清晰的独立推荐系统构建示例,该系统随后可与前端系统或其他应用程序集成。
本项目使用可通过 Steam API 获取的视频游戏数据,但这些数据可以轻松替换为任何您感兴趣的产品数据,关键步骤将保持不变。本文将涵盖如何将数据存储到数据库中、如何对游戏标签进行向量化处理、如何根据用户已互动的游戏生成相似度分数,以及如何返回一系列相关推荐。完成本文内容后,该推荐系统将作为一个 FastAPI Web 应用程序部署,以便每当用户与新游戏互动时,系统都能动态生成并存储该用户的新推荐列表。
将使用的工具包括:
- PostgreSQL
- FastAPI
- Docker
- Render
对 GitHub 仓库感兴趣的读者可点击此处查看。
目录
鉴于本项目篇幅较长,将其分为两篇文章。第一部分(如下所示的步骤 1-5)涵盖项目的设置和理论基础,第二部分则侧重于部署。第二部分文章可点击此处阅读。
第一部分
– 模型
– 路由
第二部分:
- 在 Render 上部署 PostgreSQL 数据库
- 将 FastAPI 应用程序部署为 Render Web 应用程序
– 应用程序 Docker 化
– 将 Docker 镜像推送到 DockerHub
– 从 DockerHub 拉取到 Render
数据集概览
本项目使用的数据集包含来自 Steamworks API 的大约 2000 款热门游戏数据。这些数据可免费用于个人和商业用途,但需遵守服务条款。API 存在每 5 分钟 200 次请求的速率限制,因此本项目仅使用了部分数据。服务条款可在此处查阅。
游戏数据集的概览如下所示。大多数字段都是相对不言自明的;需要注意的是,唯一的商品标识符是 `appid`。除了此数据集,还有几张额外的表格将在下文中详细介绍;其中对推荐系统最重要的一张是游戏标签表(`game tags` table),它包含了 `appid` 值与每个游戏相关联的标签(如策略、角色扮演、卡牌游戏等)的映射。这些标签从“数据概览”中显示的 `categories` 字段提取,然后进行透视,创建 `game_tags` 表,以便每个 `appid:category` 组合都有一行唯一的记录。
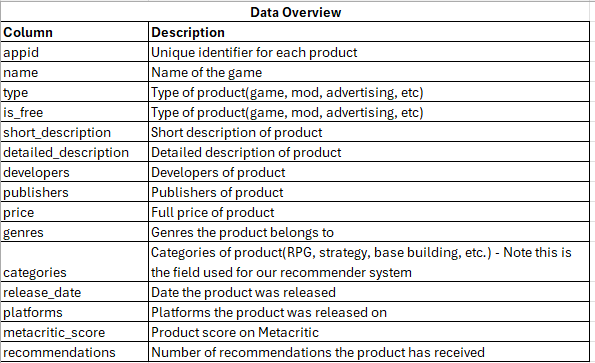
图 2:数据集概览
有关项目结构的更详细概览,请参见下图。
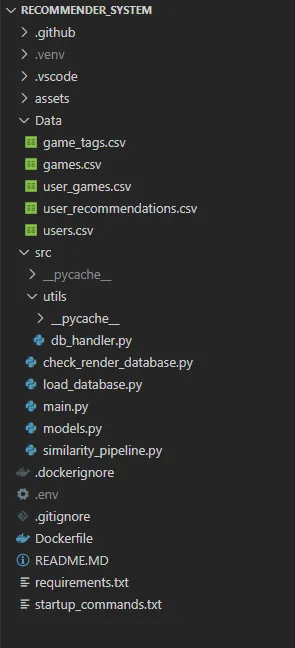
图 3:项目文件结构
接下来,本文将快速概述本项目的架构,然后深入探讨如何填充数据库。
架构设计
本推荐系统将采用 PostgreSQL 数据库,并结合 FastAPI 作为数据访问和处理层,从而实现用户游戏列表的添加或删除操作。用户通过 FastAPI 的 POST 请求对游戏库进行更改时,将同时触发一个推荐管道,该管道利用 FastAPI 的“后台任务”(Background Tasks)功能,从数据库中查询用户喜欢的游戏,计算与未喜欢游戏的相似度分数,并更新 `user_recommendation` 表,生成用户最新的 Top-N 推荐游戏。最终,PostgreSQL 数据库和 FastAPI 服务都将部署在 Render 平台上,以便在本地环境之外也能访问。在部署阶段,虽然可以使用任何云服务,但此处选择 Render 是为了其操作的简易性。
总而言之,从用户的角度来看,整个工作流程如下所示:
-
用户通过向 FastAPI 发送 POST 请求将游戏添加到其游戏库中。
- 如果需要将推荐系统连接到前端应用程序,可以轻松地将此 Post API 集成到用户界面中。
-
此 POST 请求会启动一个 FastAPI 后台任务,运行推荐管道。
-
推荐管道查询数据库以获取用户的游戏列表和全局游戏列表。
-
随后,利用游戏的标签计算用户游戏与所有游戏之间的相似度分数。
-
最后,推荐管道向数据库发送 POST 请求,更新该用户的推荐游戏表。
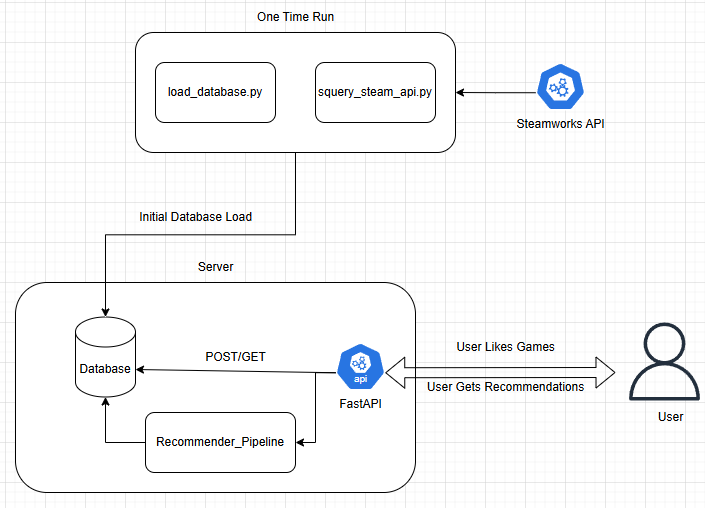
图 4:推荐系统架构图
数据库设置
在构建推荐系统之前,第一步是设置数据库。图 5 展示了基本的数据库图。本文前面已讨论过游戏表;这是所有其他数据通常派生出来的基础数据集。完整的表格列表如下:
Game表:包含数据库中每个独立游戏的基础数据。User表:一个包含示例信息的虚拟用户表,用于填充示例数据。User_Game表:包含用户“喜欢”的所有游戏之间的映射关系;该表通过捕获用户感兴趣的游戏,成为生成推荐的基础表之一。Game_Tags表:包含 `appid:game_tag` 的映射,其中游戏标签可以是“策略”、“角色扮演”、“喜剧”等描述性标签,捕捉了游戏的部分精髓。每个 `appid` 可以映射到多个标签。User_Recommendation表:这是管道将要更新的目标表。每当用户与新游戏互动时,推荐管道就会运行,为该用户生成一系列新的推荐并存储在此处。
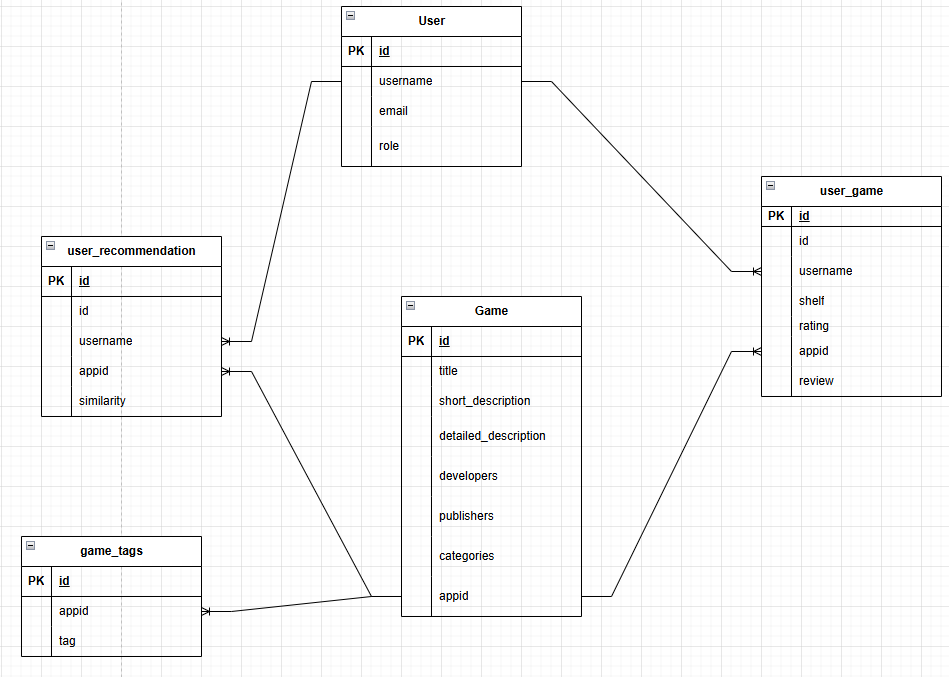
图 5:数据库关系图
为了设置这些表,只需运行 `src/load_database.py` 文件即可。该文件通过以下几个步骤创建并填充表格。请注意,目前主要关注如何将数据写入通用数据库,因此只需了解 `External_Database_Url` 是您希望使用的任何数据库的 URL。在本文的第二部分,将详细介绍如何在 Render 上设置数据库,并将 URL 复制到 `.env` 文件中。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, Session
from sqlalchemy.ext.declarative import declarative_base
import os
from dotenv import load_dotenv
from utils.db_handler import DatabaseHandler
import pandas as pd
import uuid
import sys
from sqlalchemy.exc import OperationalError
import psycopg2
# Loading environmental variables
load_dotenv(override=True)
# Construct PostgreSQL connection URL for Render
URL_database = os.environ.get("External_Database_Url")
# Initialize DatabaseHandler with our URL
engine = DatabaseHandler(URL_database)
# loading initial user data
users_df = pd.read_csv("Data/users.csv")
games_df = pd.read_csv("Data/games.csv")
user_games_df = pd.read_csv("Data/user_games.csv")
user_recommendations_df = pd.read_csv("Data/user_recommendations.csv")
game_tags_df = pd.read_csv("Data/game_tags.csv")
首先,将 `Data` 文件夹中的五个 CSV 文件加载到数据框中;每个数据框对应数据库图中的一张表。通过声明一个 `engine` 变量,建立与数据的连接;该 `engine` 变量使用一个自定义的 `DataBaseHandler` 类,其初始化方法如下所示。这个类接收 Render(或您偏好的云服务)上数据库的连接字符串(从 `.env` 文件传入),并包含所有数据库连接、更新、删除和测试功能。
加载数据并实例化 `DatabaseHandler` 类之后,需要定义创建这五张表的查询语句,并使用 `DatabaseHandler.create_table` 函数执行这些查询。这是一个非常简单的函数,它连接到数据库,执行查询,然后关闭连接,从而创建数据库图中所示的五张表;然而,这些表目前是空的。
# Defining queries to create tables
user_table_creation_query = """CREATE TABLE IF NOT EXISTS users (
id UUID PRIMARY KEY,
username VARCHAR(255) UNIQUE NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
role VARCHAR(50) NOT NULL
)
"""
game_table_creation_query = """CREATE TABLE IF NOT EXISTS games (
id UUID PRIMARY KEY,
appid VARCHAR(255) UNIQUE NOT NULL,
name VARCHAR(255) NOT NULL,
type VARCHAR(255),
is_free BOOLEAN DEFAULT FALSE,
short_description TEXT,
detailed_description TEXT,
developers VARCHAR(255),
publishers VARCHAR(255),
price VARCHAR(255),
genres VARCHAR(255),
categories VARCHAR(255),
release_date VARCHAR(255),
platforms TEXT,
metacritic_score FLOAT,
recommendations INTEGER
)
"""
user_games_query = """CREATE TABLE IF NOT EXISTS user_games (
id UUID PRIMARY KEY,
username VARCHAR(255) NOT NULL,
appid VARCHAR(255) NOT NULL,
shelf VARCHAR(50) DEFAULT 'Wish_List',
rating FLOAT DEFAULT 0.0,
review TEXT
)
"""
recommendation_table_creation_query = """CREATE TABLE IF NOT EXISTS user_recommendations (
id UUID PRIMARY KEY,
username VARCHAR(255),
appid VARCHAR(255),
similarity FLOAT
)
"""
game_tags_creation_query = """CREATE TABLE IF NOT EXISTS game_tags (
id UUID PRIMARY KEY,
appid VARCHAR(255) NOT NULL,
category VARCHAR(255) NOT NULL
)
"""
# Running queries to create tables
engine.delete_table('user_recommendations')
engine.delete_table('user_games')
engine.delete_table('game_tags')
engine.delete_table('games')
engine.delete_table('users')
# Create tables
engine.create_table(user_table_creation_query)
engine.create_table(game_table_creation_query)
engine.create_table(user_games_query)
engine.create_table(recommendation_table_creation_query)
engine.create_table(game_tags_creation_query)
在初始表设置之后,接着会运行一个质量检查,以确保每个数据集都具有所需的 ID 列,然后将数据从数据框填充到相应的表中,并测试以确保表已正确填充。如果设置成功,`test_table` 函数将返回一个形如 `{‘table_exists’: True, ‘table_has_data’: True}` 的字典。
# Ensuring each row of each dataframe has a unique ID
if 'id' not in users_df.columns:
users_df['id'] = [str(uuid.uuid4()) for _ in range(len(users_df))]
if 'id' not in games_df.columns:
games_df['id'] = [str(uuid.uuid4()) for _ in range(len(games_df))]
if 'id' not in user_games_df.columns:
user_games_df['id'] = [str(uuid.uuid4()) for _ in range(len(user_games_df))]
if 'id' not in user_recommendations_df.columns:
user_recommendations_df['id'] = [str(uuid.uuid4()) for _ in range(len(user_recommendations_df))]
if 'id' not in game_tags_df.columns:
game_tags_df['id'] = [str(uuid.uuid4()) for _ in range(len(game_tags_df))]
# Populates the 4 tables with data from the dataframes
engine.populate_table_dynamic(users_df, 'users')
engine.populate_table_dynamic(games_df, 'games')
engine.populate_table_dynamic(user_games_df, 'user_games')
engine.populate_table_dynamic(user_recommendations_df, 'user_recommendations')
engine.populate_table_dynamic(game_tags_df, 'game_tags')
# Testing if the tables were created and populated correctly
print(engine.test_table('users'))
print(engine.test_table('games'))
print(engine.test_table('user_games'))
print(engine.test_table('user_recommendations'))
print(engine.test_table('game_tags'))
FastAPI 入门
数据库已经设置并填充完毕,接下来需要使用 FastAPI 构建访问、更新和删除数据的方法。FastAPI 使开发人员能够轻松构建标准化(且快速)的 API,从而实现与数据库的交互。FastAPI 官方文档提供了出色的分步教程,可在此处找到。总体而言,FastAPI 具有以下几项出色特性,使其成为数据库与前端应用程序之间交互层的理想选择:
- 标准化:FastAPI 允许开发人员使用 `GET, POST, DELETE, UPDATE` 等方法,以标准化的方式定义与表格交互的路由。这种标准化使得开发人员能够用纯 Python 构建数据访问层,然后与各种前端应用程序进行交互。只需在前端调用所需的 API 方法,而无需关心前端是用何种语言构建的。
- 数据验证:如下文所示,需要为每个交互对象(例如游戏表和用户表)定义一个 Pydantic 数据模型。这样做主要的好处是确保所有变量都具有明确定义的数据类型。例如,如果将 `Game` 对象的 `rating` 字段定义为浮点型,而用户尝试通过 POST 请求添加一个 `rating` 为“great”的新条目,系统将拒绝该操作。这种内置的数据验证机制将有助于预防系统在扩展过程中出现各种数据质量问题。
- 异步性:FastAPI 函数可以异步运行,这意味着它们之间不相互依赖,一个任务的完成无需等待另一个任务。这可以显著提高性能,因为不会出现一个快速任务等待一个慢速任务完成的情况。
- 内置 Swagger 文档:FastAPI 具有内置的用户界面,可以通过访问 `localhost` 上的特定地址进入,从而轻松测试和与路由进行交互。
FastAPI 模型
FastAPI 项目主要依赖于两个文件:`models.py`,用于定义将要交互的数据模型(如游戏、用户等),以及 `main.py`,用于定义实际的 FastAPI 应用程序并包含其路由。在 FastAPI 的语境中,路由定义了处理请求的不同路径。例如,可以有一个 `/games` 路由来从数据库请求游戏数据。
首先,来讨论 `models.py` 文件。在此文件中,定义了所有模型。尽管针对不同对象有不同的模型,但总体方法是相同的,因此将仅详细讨论下面的游戏模型。首先会注意到,为 `Game` 对象定义了两个实际的类:一个继承自 Pydantic `BaseModel` 的 `GameModel` 类,以及一个继承自 `sqlalchemy declarative_base` 的 `Game` 类。那么,一个数据结构(游戏的结构)为什么需要两个类呢?
如果本项目不使用 SQL 数据库,而是在每次 `main.py` 运行时都将每个 CSV 文件读取到数据框中,那么就不需要 `Game` 类,只需要 `GameModel` 类。在这种情况下,会读取 `games.csv` 数据框,FastAPI 将使用 `GameModel` 类来确保数据类型正确无误。
然而,由于使用了 SQL 数据库,为 API 和数据库设置单独的类更有意义,因为这两个类扮演着略微不同的角色。API 类处理数据验证、序列化和可选字段,而数据库类处理数据库特定的问题,如定义主键/外键、定义对象映射到的表以及保护敏感数据。重申最后一点,数据库中可能存在仅供内部使用的敏感字段(例如密码),不希望通过 API 将其暴露给用户。通过拥有一个面向用户的独立 Pydantic 类和一个内部的 SQLAlchemy 类,可以解决这一问题。
以下是 `Games` 对象的实现示例;其他表也有独立的类定义,可在此处找到,但总体结构是相同的。
from pydantic import BaseModel
from uuid import UUID,uuid4
from typing import Optional
from enum import Enum
from sqlalchemy import Column, String, Float, Integer
import sqlalchemy.dialects.postgresql as pg
from sqlalchemy.dialects.postgresql import UUID as SA_UUID
from sqlalchemy.ext.declarative import declarative_base
import uuid
from uuid import UUID
# loading sql model
from sqlmodel import Field, Session, SQLModel, create_engine, select
# Initialize the base class for SQLAlchemy models
Base = declarative_base()
# This is the Game model for the database
class Game(Base):
__tablename__ = "optigame_products" # Table name in the PostgreSQL database
id = Column(pg.UUID(as_uuid=True), primary_key=True, default=uuid.uuid4, unique=True, nullable=False)
appid = Column(String, unique=True, nullable=False)
name = Column(String, nullable=False)
type = Column(String, nullable=True)
is_free = Column(pg.BOOLEAN, nullable=True, default=False) #
short_description = Column(String, nullable=True)
detailed_description = Column(String, nullable=True)
developers = Column(String, nullable=True)
publishers = Column(String, nullable=True)
price = Column(String, nullable=True)
genres = Column(String, nullable=True)
categories = Column(String, nullable=True)
release_date = Column(String, nullable=True)
platforms = Column(String, nullable=True)
metacritic_score = Column(Float, nullable=True)
recommendations = Column(Integer, nullable=True)
class GameModel(BaseModel):
id: Optional[UUID] = None
appid: str
name: str
type: Optional[str] = None
is_free: Optional[bool] = False
short_description: Optional[str] = None
detailed_description: Optional[str] = None
developers: Optional[str] = None
publishers: Optional[str] = None
price: Optional[str] = None
genres: Optional[str] = None
categories: Optional[str] = None
release_date: Optional[str] = None
platforms: Optional[str] = None
metacritic_score: Optional[float] = None
recommendations: Optional[int] = None
class Config:
orm_mode = True # Enable ORM mode to work with SQLAlchemy objects
from_attributes = True # Enable attribute access for SQLAlchemy objects
设置 FastAPI 路由
定义模型之后,便可以创建方法来与这些模型进行交互,从而实现从数据库请求数据(GET)、向数据库添加数据(POST)或从数据库删除数据(DELETE)。下面是为游戏模型定义 GET 请求的示例。`main.py` 函数的开头进行了一些初始化设置,用于获取数据库 URL 并建立连接。接着,初始化应用程序并添加中间件以定义允许请求的 URL。由于 FastAPI 项目将部署在 Render 上,并从本地机器向其发送请求,因此只允许 `localhost` 端口 8000 作为来源。随后,定义了名为 `fetch_products` 的 `app.get` 方法,该方法接收一个 `appid` 输入,查询数据库中 `appid` 等于筛选 `appid` 的 `Game` 对象,并返回这些产品。
请注意,以下代码片段仅包含设置和第一个 GET 方法,其余方法都非常相似,并且可以在仓库中找到,因此本文将不再对每个方法进行深入解释。
from fastapi import FastAPI, Depends, HTTPException, BackgroundTasks
from uuid import uuid4, UUID
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
from dotenv import load_dotenv
import os
# Load environment variables
load_dotenv()
# security imports
from fastapi.middleware.cors import CORSMiddleware
from fastapi.security import OAuth2PasswordBearer
# custom imports
from src.models import User, Game, GameModel, UserModel, UserGameModel, UserGame, GameSimilarity,GameSimilarityModel, UserRecommendation, UserRecommendationModel
from src.similarity_pipeline import UserRecommendationService
# Load the database connection string from environment variable or .env file
DATABASE_URL = os.environ.get("Internal_Database_Url")
# creating connection to the database
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
# Create the database tables (if they don't already exist)
Base.metadata.create_all(bind=engine)
# Dependency to get the database session
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
# Initialize the FastAPI app
app = FastAPI(title="Game Store API", version="1.0.0")
# Add CORS middleware to allow requests
origins = ["http://localhost:8000"]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
#-------------------------------------------------#
# ----------PART 1: GET METHODS-------------------#
#-------------------------------------------------#
@app.get("/")
async def root():
return {"message": "Hello World"}
@app.get("/api/v1/games/")
async def fetch_products(appid: str = None, db: Session = Depends(get_db)):
# Query the database using the SQLAlchemy Game model
if appid:
products = db.query(Game).filter(Game.appid == appid).all()
else:
products = db.query(Game).all()
return [GameModel.from_orm(product) for product in products]
定义好 `main.py` 文件后,便可以从项目根目录使用以下命令运行它。
uvicorn src.main:app --reload
运行成功后,可以导航至 http://127.0.0.1:8000/docs,查看交互式 FastAPI 环境。在该页面上,可以测试 `main.py` 文件中定义的任何方法。对于 `fetch_products` 函数,可以传入一个 `appid`,并从数据库中返回任何匹配的游戏。
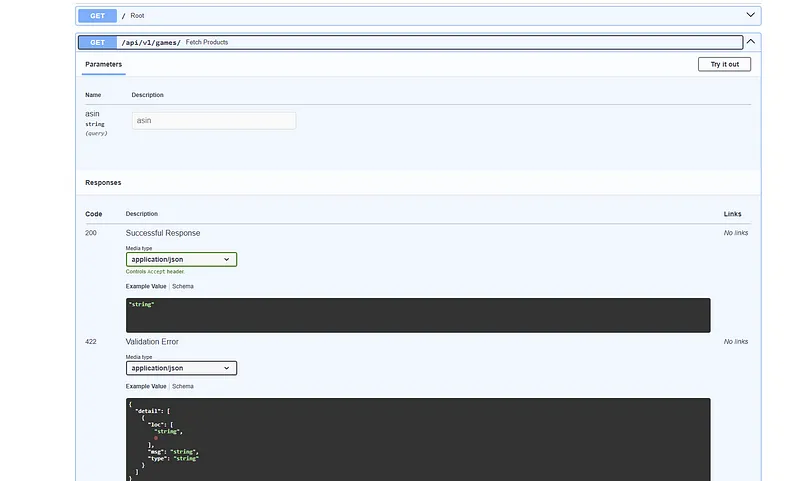
图 6:FastAPI Swagger 文档界面
构建相似度管道
数据库已经设置完毕,并且可以通过 FastAPI 访问和更新数据;现在是时候转向本项目核心功能:推荐管道。推荐系统是一个经过充分研究的领域,本文在此没有增加任何创新;然而,这将提供一个清晰的示例,展示如何使用 FastAPI 实现一个基本的推荐系统。
入门 — 如何推荐产品?
如果思考“如何推荐用户会喜欢的新产品?”,有两种直观的方法:
- 协同过滤推荐系统:如果有一系列用户和一系列产品,可以通过查看用户整体的产品组合来识别兴趣相似的用户,然后找出特定用户产品组合中“缺失”的产品。例如,如果有用户 1-3 和产品 A-C,用户 1-2 喜欢所有三款产品,而用户 3 迄今只喜欢产品 A 和 B,那么系统可能会向其推荐产品 C。这在逻辑上是合理的;所有三位用户在喜欢的产品上高度重叠,但产品 C 缺失于用户 3 的产品组合中,因此他们也很可能喜欢它。这种通过比较相似用户来生成推荐的过程称为协同过滤。
- 基于内容的推荐系统:如果有一系列产品,可以识别与用户喜欢的产品相似的产品并推荐这些产品。例如,如果每个游戏都有一系列标签,可以将每个游戏的标签系列转换为 1 和 0 的向量,然后使用相似度度量(本例中为余弦相似度)来衡量游戏之间基于其向量的相似性。完成此操作后,便可以根据相似度分数,返回与用户喜欢游戏最相似的 Top-N 游戏。
有关推荐系统的更多信息,请参阅此处。
由于本项目的初始数据集不包含大量用户数据,因此没有足够的数据来根据用户相似性推荐物品,这被称为冷启动问题。因此,本文将转而开发一个基于内容的推荐系统,因为我们有大量的游戏数据可供使用。
为了构建推荐管道,需要解决两个挑战:(1) 如何计算用户的相似度分数?(2) 如何自动化此过程,使其在用户更新游戏时自动运行?
本文将介绍如何在用户通过“喜欢”游戏发出 POST 请求时触发相似度管道,然后涵盖如何构建管道本身。
将推荐管道与 FastAPI 结合
现在,假设有一个推荐服务将更新 `user_recommendation` 表。希望确保每当用户更新其偏好时,都会调用此服务。可以通过以下几个步骤实现:首先,定义一个 `generate_recommendations_background` 函数,该函数负责连接到数据库,运行相似度管道,然后关闭连接。接下来,需要确保当用户发出 POST 请求(即喜欢一个新游戏)时调用此函数;为此,只需在 `create_user_game` POST 请求函数的末尾添加该函数调用即可。
此工作流程的结果是,每当用户向 `user_game` 表发出 POST 请求时,他们都会调用 `create_user_game` 函数,向数据库添加一个新的 `user_game` 对象,然后作为后台函数运行相似度管道。
注意:以下 POST 方法和辅助函数与其余 FastAPI 方法一同存储在 `main.py` 文件中。
# importing similarity pipeline
from src.similarity_pipeline import UserRecommendationService
# Background task function
def generate_recommendations_background(username: str, database_url: str):
"""Background task to generate recommendations for a user"""
# Create a new database session for the background task
background_engine = create_engine(database_url)
BackgroundSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=background_engine)
db = BackgroundSessionLocal()
try:
recommendation_service = UserRecommendationService(db, database_url)
recommendation_service.generate_recommendations_for_user(username)
finally:
db.close()
# Post method which calls background task function
@app.post("/api/v1/user_game/")
async def create_user_game(user_game: UserGameModel, background_tasks: BackgroundTasks, db: Session = Depends(get_db)):
# Check if the entry already exists
existing = db.query(UserGame).filter_by(username=user_game.username, appid=user_game.appid).first()
if existing:
raise HTTPException(status_code=400, detail="User already has this game.")
# Prepare data with defaults
user_game_data = {
"username": user_game.username,
"appid": user_game.appid,
"shelf": user_game.shelf if user_game.shelf is not None else "Wish_List",
"rating": user_game.rating if user_game.rating is not None else 0.0,
"review": user_game.review if user_game.review is not None else ""
}
if user_game.id is not None:
user_game_data["id"] = UUID(str(user_game.id))
# Save the user game to database
db_user_game = UserGame(**user_game_data)
db.add(db_user_game)
db.commit()
db.refresh(db_user_game)
# Trigger background task to generate recommendations for this user
background_tasks.add_task(generate_recommendations_background, user_game.username, DATABASE_URL)
return db_user_game
构建推荐管道
现在已经了解了当用户更新其喜欢的游戏时,相似度管道如何被触发,接下来将深入探讨推荐管道的工作机制。推荐管道存储在 `similarity_pipeline.py` 文件中,并包含前面已介绍如何导入和实例化的 `UserRecommendationService` 类。该类包含一系列辅助函数,这些函数最终都将在 `generate_recommendations_for_user` 方法中被调用。以下将逐一介绍按顺序调用的 7 个基本步骤。
- 获取用户的游戏:为了生成相似的游戏推荐,需要检索用户已添加到其游戏库中的游戏。这通过调用 `fetch_user_games` 辅助函数完成。该函数使用发出 POST 请求的用户 ID 作为输入,查询 `user_games` 表,并返回用户游戏库中的所有游戏。
- 获取游戏标签:为了比较游戏,需要一个维度来进行比较,这个维度就是与每个游戏相关联的标签(如策略、棋盘游戏等)。为了检索游戏与标签的映射关系,调用 `fetch_all_game_tags` 函数,该函数返回数据库中所有游戏的标签。
- 游戏标签向量化:为了比较游戏 A 和游戏 B 之间的相似性,首先需要使用 `create_game_vectors` 函数对游戏标签进行向量化。该函数按字母顺序获取所有标签,并检查每个标签是否与给定游戏关联。例如,如果总标签集是 [boardgame, deckbuilding, resource-management],而游戏 1 仅关联了 boardgame 标签,那么其向量将是 [1, 0, 0]。
- 创建用户向量:一旦有了代表每个游戏的向量,就需要一个聚合用户向量来与之比较。为了实现这一点,使用 `create_user_vector` 函数,它生成一个与游戏向量长度相同的聚合向量,然后可以使用该向量来生成用户与所有其他游戏之间的相似度分数。
- 计算相似度:在步骤 3 和 4 中创建的向量将用于 `calculate_user_recommendations` 函数中,该函数计算范围从 0 到 1 的余弦相似度分数,并衡量每个游戏与用户聚合游戏之间的相似性。
- 删除旧推荐:在用新推荐填充 `user_recommendations` 表之前,首先需要使用 `delete_existing_recommendations` 删除旧的推荐。这仅删除发出 POST 请求的用户的推荐;其他用户的推荐保持不变。
- 填充新推荐:删除旧推荐后,接着使用 `save_recommendations` 填充新推荐。
from sqlalchemy.orm import Session
from sqlalchemy import create_engine, text
from src.models import UserGame, UserRecommendation
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
import uuid
from typing import List
import logging
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class UserRecommendationService:
def __init__(self, db_session: Session, database_url: str):
self.db = db_session
self.database_url = database_url
self.engine = create_engine(database_url)
def fetch_user_games(self, username: str) -> pd.DataFrame:
"""Fetch all games for a specific user"""
query = text("SELECT username, appid FROM user_games WHERE username = :username")
with self.engine.connect() as conn:
result = conn.execute(query, {"username": username})
data = result.fetchall()
return pd.DataFrame(data, columns=['username', 'appid'])
def fetch_all_category(self) -> pd.DataFrame:
"""Fetch all game tags"""
query = text("SELECT appid, category FROM category")
with self.engine.connect() as conn:
result = conn.execute(query)
data = result.fetchall()
return pd.DataFrame(data, columns=['appid', 'category'])
def create_game_vectors(self, tag_df: pd.DataFrame) -> tuple[pd.DataFrame, List[str], List[str]]:
"""Create game vectors from tags"""
unique_tags = tag_df['category'].drop_duplicates().sort_values().tolist()
unique_games = tag_df['appid'].drop_duplicates().sort_values().tolist()
game_vectors = []
for game in unique_games:
tags = tag_df[tag_df['appid'] == game]['category'].tolist()
vector = [1 if tag in tags else 0 for tag in unique_tags]
game_vectors.append(vector)
return pd.DataFrame(game_vectors, columns=unique_tags, index=unique_games), unique_tags, unique_games
def create_user_vector(self, user_games_df: pd.DataFrame, game_vectors: pd.DataFrame, unique_tags: List[str]) -> pd.DataFrame:
"""Create user vector from their played games"""
if user_games_df.empty:
return pd.DataFrame([[0] * len(unique_tags)], columns=unique_tags, index=['unknown_user'])
username = user_games_df.iloc[0]['username']
user_games = user_games_df['appid'].tolist()
# Only keep games that exist in game_vectors
user_games = [g for g in user_games if g in game_vectors.index]
if not user_games:
user_vector = [0] * len(unique_tags)
else:
played_game_vectors = game_vectors.loc[user_games]
user_vector = played_game_vectors.mean(axis=0).tolist()
return pd.DataFrame([user_vector], columns=unique_tags, index=[username])
def calculate_user_recommendations(self, user_vector: pd.DataFrame, game_vectors: pd.DataFrame, top_n: int = 20) -> pd.DataFrame:
"""Calculate similarity between user vector and all game vectors"""
username = user_vector.index[0]
user_vector_data = user_vector.iloc[0].values.reshape(1, -1)
# Calculate similarities
similarities = cosine_similarity(user_vector_data, game_vectors)
similarity_df = pd.DataFrame(similarities.T, index=game_vectors.index, columns=[username])
# Get top N recommendations
top_games = similarity_df[username].nlargest(top_n)
recommendations = []
for appid, similarity in top_games.items():
recommendations.append({
"username": username,
"appid": appid,
"similarity": float(similarity)
})
return pd.DataFrame(recommendations)
def delete_existing_recommendations(self, username: str):
"""Delete existing recommendations for a user"""
self.db.query(UserRecommendation).filter(UserRecommendation.username == username).delete()
self.db.commit()
def save_recommendations(self, recommendations_df: pd.DataFrame):
"""Save new recommendations to database"""
for _, row in recommendations_df.iterrows():
recommendation = UserRecommendation(
id=uuid.uuid4(),
username=row['username'],
appid=row['appid'],
similarity=row['similarity']
)
self.db.add(recommendation)
self.db.commit()
def generate_recommendations_for_user(self, username: str, top_n: int = 20):
"""Main method to generate recommendations for a specific user"""
try:
logger.info(f"Starting recommendation generation for user: {username}")
# 1. Fetch user's games
user_games_df = self.fetch_user_games(username)
if user_games_df.empty:
logger.warning(f"No games found for user: {username}")
return
# 2. Fetch all game tags
tag_df = self.fetch_all_category()
if tag_df.empty:
logger.error("No game tags found in database")
return
# 3. Create game vectors
game_vectors, unique_tags, unique_games = self.create_game_vectors(tag_df)
# 4. Create user vector
user_vector = self.create_user_vector(user_games_df, game_vectors, unique_tags)
# 5. Calculate recommendations
recommendations_df = self.calculate_user_recommendations(user_vector, game_vectors, top_n)
# 6. Delete existing recommendations
self.delete_existing_recommendations(username)
# 7. Save new recommendations
self.save_recommendations(recommendations_df)
logger.info(f"Successfully generated {len(recommendations_df)} recommendations for user: {username}")
except Exception as e:
logger.error(f"Error generating recommendations for user {username}: {str(e)}")
self.db.rollback()
raise
总结
在本文中,详细介绍了如何设置 PostgreSQL 数据库和 FastAPI 应用程序以运行游戏推荐系统。然而,尚未涵盖如何将该系统部署到云服务,以供其他用户交互。有关部署的第二部分内容,请继续阅读第二部分。
图片来源:除非另有说明,所有图片均由作者提供。
链接





