深度研究系统(Deep Research System)是一种日益普及的功能,可在ChatGPT和Google Gemini等应用程序中启用。它允许用户像往常一样提出查询,但应用程序会投入更长的时间对问题进行深入研究,从而提供比普通大型语言模型(LLM)响应更优质的答案。
这项技术同样可以应用于私有文档集合。例如,如果企业拥有数千份内部文件,可能希望构建一个深度研究系统,该系统能够接收用户问题,扫描所有可用的(内部)文档,并基于这些信息生成准确且全面的答案。

此信息图概括了本文的主要内容。文章将探讨在何种情况下需要构建深度研究系统,以及何时采用检索增强生成(RAG)或关键词搜索等更简单的方法更为合适。接着,将详细阐述如何构建一个深度研究系统,包括数据收集、工具创建,以及如何利用协调器LLM和子智能体将所有组件整合起来。该图片由ChatGPT生成。
目录
为什么要构建深度研究系统?
读者可能会提出的第一个问题是:
为什么需要深度研究系统?
这是一个合理的问题,因为在许多情况下,存在其他可行的替代方案:
- 将所有数据输入大型语言模型
- 检索增强生成(RAG)
- 关键词搜索
如果能够通过这些更简单的系统解决问题,那么几乎总是应该优先选择它们。最简单的方法莫过于将所有数据直接喂给一个大型语言模型。如果信息量少于100万个token,这无疑是一个不错的选择。
此外,如果传统的RAG方法表现良好,或者能够通过关键词搜索找到相关信息,同样也应优先考虑这些方案。然而,有时这些解决方案都无法有效解决问题。可能需要深入分析大量来源,而基于相似性的块检索(RAG)已不足以满足需求。或者,由于对数据集不够熟悉,不知道该使用哪些关键词进行搜索,导致关键词搜索无法奏效。在这种情况下,就应该考虑使用深度研究系统。
如何构建深度研究系统
自然地,可以利用OpenAI等提供商的深度研究系统,他们提供了深度研究API。如果希望保持简单,这会是一个不错的选择。然而,本文将更详细地探讨深度研究系统是如何构建的,以及它的实用之处。Anthropic公司曾发表一篇关于其多智能体研究系统(本质上就是深度研究系统)的优秀文章,建议读者阅读以了解更多细节。
信息收集与索引
任何信息查找系统的第一步都是将所有信息集中到一个地方。信息可能分散在以下应用程序中:
- Google Drive
- Notion
- Salesforce
接着,需要将这些信息集中到一个位置(例如,将其全部转换为PDF并存储在同一文件夹中),或者可以像ChatGPT在其应用程序中所做的那样,直接连接到这些应用。
信息收集完成后,接下来需要对其进行索引,以便于访问。应创建的两种主要索引是:
- 关键词搜索索引。例如BM25
- 向量相似性索引:将文本分块、嵌入,并存储在Pinecone等向量数据库中。
这将使得信息能够通过下一节将描述的工具轻松访问。
工具
后续使用的智能体需要工具来获取相关信息。因此,应该构建一系列功能,使大型语言模型能够轻松地检索相关信息。例如,如果用户查询销售报告,大型语言模型可能会希望对该报告进行关键词搜索并分析检索到的文档。这些工具的示例代码如下:
@tool
def keyword_search(query: str) -> str:
"""
Search for keywords in the document.
"""
results = keyword_search(query)
# format responses to make it easy for the LLM to read
formatted_results = "
".join([f"{result['file_name']}: {result['content']}" for result in results])
return formatted_results
@tool
def vector_search(query: str) -> str:
"""
Embed the query and search for similar vectors in the document.
"""
vector = embed(query)
results = vector_search(vector)
# format responses to make it easy for the LLM to read
formatted_results = "
".join([f"{result['file_name']}: {result['content']}" for result in results])
return formatted_results
此外,还可以允许智能体访问其他功能,例如:
- 互联网搜索
- 仅按文件名搜索
以及其他潜在的相关功能
系统整合
深度研究系统通常由一个协调器智能体和多个子智能体组成。其运作方式通常如下:
- 协调器智能体接收用户查询并规划采取的方法。
- 多个子智能体被派去获取相关信息,并将汇总的信息反馈给协调器。
- 协调器判断是否有足够的信息来回答用户查询。如果否,则返回上一步;如果是,则进入最后一步。
- 协调器将所有信息整合起来,并向用户提供答案。
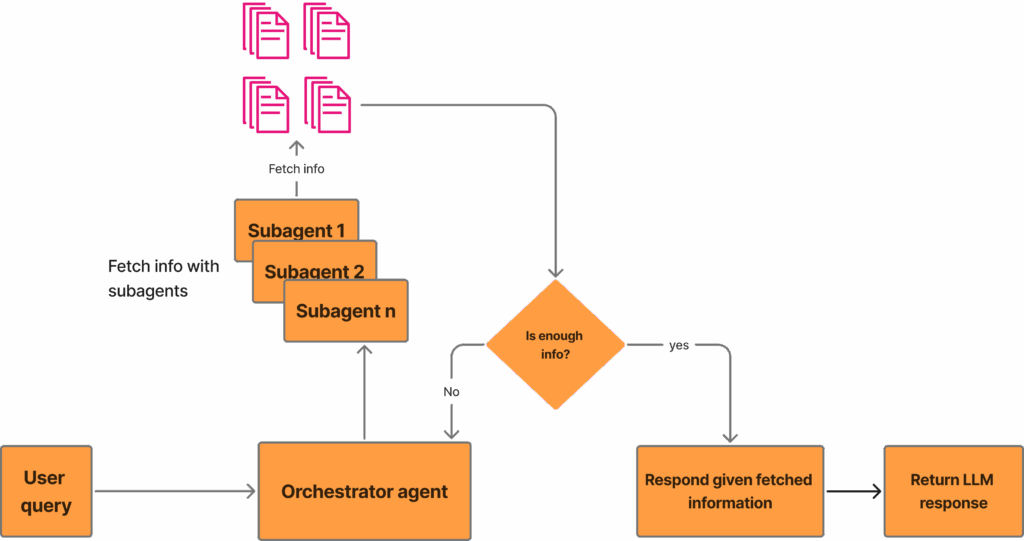
此图突出了本文所讨论的深度研究系统。用户输入查询后,协调器智能体对其进行处理,并派遣子智能体从文档语料库中获取信息。协调器智能体随后判断是否有足够的信息来响应用户查询。如果答案是否定的,它会获取更多信息;如果信息充足,它将为用户生成响应。图片由作者提供。
此外,如果用户的提问模糊,或者为了缩小查询范围,系统也可能提出澄清问题。如果曾使用过前沿实验室的任何深度研究系统,可能已经体验过这种情况,即深度研究系统总是以提出澄清问题作为开始。
通常,协调器智能体是一个更大/性能更优的模型,例如Claude Opus,或具有高推理能力的GPT-5。而子智能体通常较小,如GPT-4.1和Claude Sonnet。
这种方法(特别是与传统RAG相比)的主要优势在于,它允许系统扫描和分析更多的信息,从而降低了遗漏与用户查询相关的关键信息的可能性。然而,需要扫描更多文档的事实通常也会使系统运行速度变慢。这自然是响应时间与响应质量之间的一种权衡。
结论
在本文中,深入探讨了如何构建一个深度研究系统。文章首先阐述了构建此类系统的动机,以及在哪些场景下应优先考虑构建RAG或关键词搜索等更简单的系统。接着,文章讨论了深度研究系统的基础构成,它本质上接收用户查询,规划回答策略,派遣子智能体获取相关信息,然后聚合这些信息并最终响应用户。