

GPT-5作为一款前沿的大型语言模型,拥有强大的功能和实用特性。为了在不同应用场景中最大限度地发挥GPT-5的性能,用户需要理解并正确选择模型提供的各项参数和选项。
本文将深入探讨GPT-5的各项使用选项,旨在帮助用户为特定用例选择最佳设置。文章将详细介绍模型支持的不同输入模式、如工具调用和文件上传等核心功能,以及可供调整的各项模型参数。
需要声明的是,本文并非由OpenAI赞助,而是基于实践者使用GPT-5的经验总结,旨在探讨如何有效利用该模型。
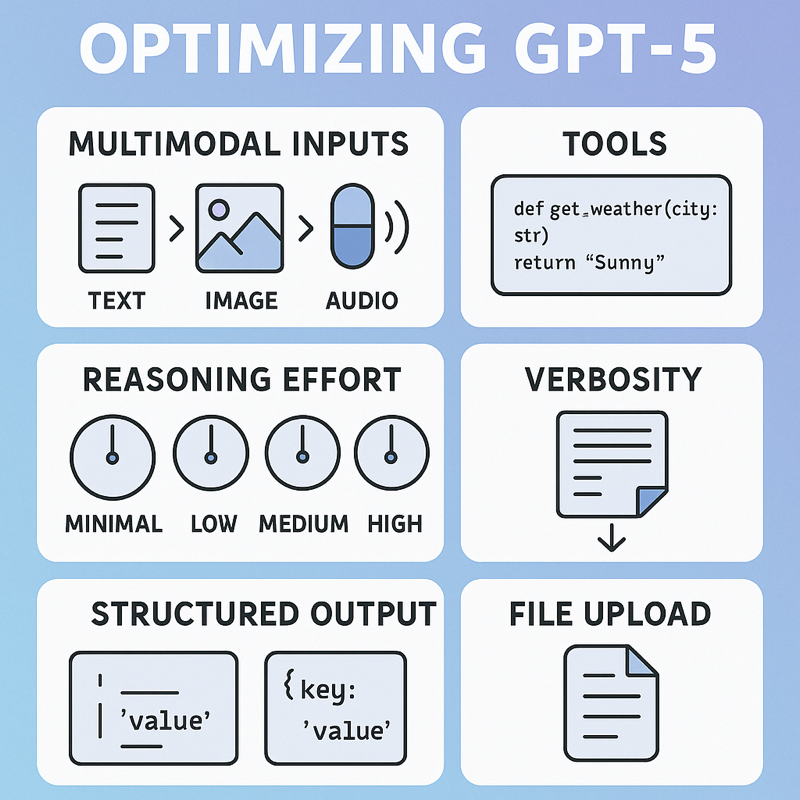
这份信息图概述了本文的主要内容。文章将阐述GPT-5如何处理多模态输入及其高效应用,并深入探讨工具调用、推理复杂度(Reasoning Effort)和冗长程度(Verbosity)的设置。此外,还将讨论结构化输出的实用场景及文件上传功能。图片来源:ChatGPT。
为何应使用GPT-5
GPT-5是一款功能极其强大的模型,可应用于各种广泛的任务,例如构建智能聊天助手或从文档中提取关键元数据。然而,GPT-5也提供了众多不同的选项和设置,其中许多细节可在OpenAI官方的GPT-5指南中查阅。本文将侧重于指导用户如何理解并驾驭这些选项,从而针对特定用例实现GPT-5的最优化利用。
多模态能力
GPT-5是一个多模态模型,这意味着它不仅能接受文本输入,还支持图像和音频输入,并最终输出文本。用户甚至可以在输入中混合使用不同模态,例如,同时输入一张图片和一个关于该图片的提示词,然后接收模型生成的响应。虽然大型语言模型(LLM)处理文本输入是意料之中,但其接受图像和音频输入的能力则显得异常强大。
正如先前文章所探讨的,视觉语言模型(VLMs)因其直接理解图像的能力而异常强大,这通常比先对图像执行光学字符识别(OCR)再理解提取文本的效果更佳。同样的概念也适用于音频处理。例如,用户可以直接输入一段音频剪辑,模型不仅能分析剪辑中的文字内容,还能解析其音高、语速等非文本信息。这种多模态理解能力无疑能帮助用户对所分析的数据获得更深层次的洞察。
工具调用
工具调用是GPT-5提供的另一项强大功能。用户可以定义模型在执行过程中可调用的工具,从而将GPT-5转化为一个智能代理。一个简单的工具示例是get_weather()函数:
def get_weather(city: str):
return "Sunny"
随后,用户可以将自定义工具及其描述和函数参数提供给模型:
tools = [
{
"type": "function",
"name": "get_weather",
"description": "Get today's weather.",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city you want the weather for",
},
},
"required": ["city"],
},
},
]
在函数定义中提供详细且描述性的信息至关重要,这包括对函数本身的描述以及利用该函数所需的参数信息。
虽然可以为模型定义大量工具,但请务必牢记AI工具定义的核心原则:
- 工具描述清晰明了
- 工具之间无功能重叠
- 明确指出模型何时应使用该函数,模糊性会降低工具使用的效率
核心参数
在使用GPT-5时,有三个核心参数值得关注:
- 推理复杂度(Reasoning effort)
- 冗长程度(Verbosity)
- 结构化输出(Structured output)
接下来,将详细介绍这些参数及其选择策略。
推理复杂度(Reasoning effort)
推理复杂度参数提供以下选项:
- 极简(minimal)
- 低(low)
- 中(medium)
- 高(high)
极简(minimal)推理模式使GPT-5在本质上成为一个非推理模型,适用于需要快速响应的简单任务。例如,在聊天应用中,当问题简单易答且用户期望即时反馈时,可以采用极简推理复杂度。
任务难度越高,所需的推理复杂度也应越高。然而,用户需权衡更高推理复杂度所带来的成本和延迟。推理过程会消耗输出token,在本文撰写时,GPT-5的推理成本约为每百万token 10美元。
实践中,建议从最低的推理复杂度开始对模型进行实验。如果观察到模型难以给出高质量的响应,可以逐步提高推理级别,例如从极简(minimal)提升至低(low),然后继续测试模型的表现。目标是使用在可接受质量前提下的最低推理复杂度。
client = OpenAI()
request_params = {
"model" = "gpt-5",
"input" = messages,
"reasoning": {"effort": "medium"}, # can be: minimal, low, medium, high
}
client.responses.create(**request_params)
冗长程度(Verbosity)
冗长程度是另一个重要的可配置参数,其选项包括:
- 低(low)
- 中(medium)
- 高(high)
冗长程度参数控制模型应输出多少token(此处不包括思考token)。默认设置为中(medium)冗长程度,OpenAI也曾指出,这基本上是其早期模型所采用的设置。
如果期望模型生成更长、更详细的响应,应将冗长程度设置为高(high)。然而,在多数应用场景中,通常选择在低(low)和中(medium)冗长程度之间。
- 对于聊天应用,中等(medium)冗长程度表现良好,因为过于简洁的模型可能会让用户觉得不够有帮助(许多用户更喜欢响应中包含一些细节)。
- 然而,对于提取目的,例如仅需从文档中提取特定信息(如日期),可将冗长程度设置为低(low)。这有助于确保模型只返回所需输出(即日期),而不提供额外的推理和上下文。
client = OpenAI()
request_params = {
"model" = "gpt-5",
"input" = messages,
"text" = {"verbosity": "medium"}, # can be: low, medium, high
}
client.responses.create(**request_params)
结构化输出(Structured output)
结构化输出是一项强大的设置,可以确保GPT-5以JSON格式响应。这对于仅需提取特定数据点(如文档中的日期)而无需其他文本的场景非常有用。它能保证模型返回一个有效的JSON对象,便于后续解析。在所有元数据提取任务中,结构化输出因其极高的结果一致性而备受青睐。用户可以通过在GPT-5请求参数中添加“text”键来启用结构化输出,示例如下。
client = OpenAI()
request_params = {
"model" = "gpt-5",
"input" = messages,
"text" = {"format": {"type": "json_object"}},
}
client.responses.create(**request_params)
请务必在您的提示词中明确提及“JSON”;否则,如果启用了结构化输出,将收到错误提示。
文件上传功能
文件上传是GPT-5提供的另一项强大功能。虽然前文已讨论了模型的多模态能力,但在某些场景下,直接上传文档并由OpenAI进行解析会非常有用。例如,如果用户尚未对文档执行OCR或从中提取图像,可以直接将文档上传至OpenAI并提出问题。根据实践经验,文件上传速度通常很快,并且模型通常会给出迅速响应,这主要取决于所请求的推理复杂度。
如果用户需要从文档中快速获取响应,而又没有时间先行执行OCR,那么文件上传无疑是一项值得利用的强大功能。
GPT-5的局限性
GPT-5也存在一些局限性。在使用过程中,一个主要缺点是OpenAI不提供模型推理过程中的“思考token”细节,用户只能获取思考过程的摘要信息。
这在实时应用中尤其具有限制性,因为如果需要使用中(medium)或高(high)等更高推理复杂度,模型在思考过程中无法向用户流式传输任何信息,从而导致较差的用户体验。这种情况下,用户只能选择较低的推理复杂度,但这又可能导致输出质量的下降。相比之下,其他前沿模型提供商,如Anthropic和Gemini,均提供了思考token。
此外,关于GPT-5相比其前代模型创造力有所下降的讨论也很多,不过对于主要通过API调用GPT-5的应用而言,这通常不是一个大问题,因为创意性往往不是API使用场景的核心要求。
总结
本文概述了GPT-5的各项参数和选项,并探讨了如何最有效地利用该模型。如果使用得当,GPT-5无疑是一款极其强大的模型,但其也伴随着一些固有的局限性。从开发者的角度来看,主要缺点是OpenAI不提供推理过程的详细信息。在开发LLM应用时,始终建议准备来自其他前沿模型提供商的备用模型。例如,可以以GPT-5作为主模型,但当其无法满足需求时,可回退到使用Google的Gemini 2.5 Pro等替代方案。





