在第一部分中,探讨了如何利用HTMX为HTML元素增加交互性,实现“无JavaScript的JavaScript”。为了具体演示,当时已着手构建一个能返回模拟大型语言模型(LLM)响应的简单聊天应用。在本文中,将进一步扩展聊天机器人的功能,并增加多项特性,其中流式传输功能将大幅提升用户体验,相较于之前构建的同步聊天应用,这是一项显著的进步。
 基于SSE的实时流式传输
基于SSE的实时流式传输 支持多用户的会话式架构
支持多用户的会话式架构 使用asyncio.Queue进行异步协调
使用asyncio.Queue进行异步协调 采用专用SSE处理的清晰HTMX模式
采用专用SSE处理的清晰HTMX模式 集成Google搜索智能体,以获取最新数据并回答查询
集成Google搜索智能体,以获取最新数据并回答查询 几乎零JavaScript的代码实现
几乎零JavaScript的代码实现
以下是本文将要构建的成果预览:
从同步通信到异步通信的演进
此前构建的应用利用了非常基础的Web表单功能,其通信方式是同步的。这意味着在服务器完成全部处理并返回响应之前,客户端无法获取任何信息。当发送一个请求后,只能等待完整的响应,然后才能将其显示出来。在这段等待过程中,用户体验可能会受到影响。
然而,现代聊天机器人采取了不同的工作模式,它们提供了异步通信能力。这通常通过流式传输实现:客户端可以持续接收更新和部分响应,而无需等待完整的最终响应。当响应生成过程耗时较长时,这种方式尤其有用,例如大型语言模型(LLM)生成长答案时,流式传输能显著提升用户体验。
SSE 与 WebSocket:实时通信协议之选
SSE(Server-Sent Events,服务器发送事件)和WebSocket都是客户端与服务器之间实现实时数据交换的协议。
WebSocket支持全双工连接,这意味着浏览器和服务器可以同时发送和接收数据。这通常应用于在线游戏、即时聊天应用以及协作工具(如Google表格)等场景。
相比之下,SSE是单向的,只允许从服务器到客户端的单向通信。这意味着客户端不能通过SSE协议向服务器发送数据。如果说WebSocket像一场人们可以同时说话和倾听的双向电话交谈,那么SSE则更像是收听广播。SSE通常用于发送通知、更新金融应用中的图表或实时新闻推送。
那为什么选择SSE呢?因为在本文所构建的场景中,并不需要全双工通信。简单的HTTP协议(WebSocket的工作方式与HTTP不同)足以满足需求:客户端发送数据,服务器接收并返回数据。SSE的引入仅仅是为了实现数据以流的形式传输,其他更复杂的功能并非必需。
实现目标与工作流程
- 用户输入查询。
- 服务器接收查询并将其发送至大型语言模型(LLM)。
- LLM开始生成内容。
- 服务器即时返回LLM生成的每一小部分内容。
- 浏览器将这些内容片段逐步添加到DOM中。
接下来的工作将分为后端和前端两大部分进行。
后端实现
后端处理将分为两个主要步骤:
- 一个POST接口,负责接收消息,但不返回任何内容。
- 一个GET接口,负责读取消息队列并生成输出流。
在本次演示中,首先会通过重复用户输入来模拟大型语言模型(LLM)的响应,这意味着流式传输中的词语将与用户的输入完全相同。
为了确保通信的清晰与隔离,需要按用户会话分离消息流(即消息队列),否则不同用户之间的对话可能会混淆。因此,将创建一个会话字典来存储这些队列。
接下来,还需要指示后端在消息队列填充完毕后再开始流式传输响应。如果不在队列填充前等待,可能会遇到并发执行或时序问题:例如,客户端的SSE连接启动时队列是空的,SSE随即关闭;用户随后输入消息,但为时已晚,消息无法被处理。
解决方案是使用异步队列!异步队列具有多项优势:
- 如果队列中有数据,则立即返回。
- 如果队列为空,则暂停执行,直到调用
queue.put()。 - 支持多个消费者,每个消费者都能获取到自己的数据。
- 线程安全,避免竞态条件。
下面是具体的代码实现:
from fastapi import FastAPI, Request, Form
from fastapi.templating import Jinja2Templates
from fastapi.responses import HTMLResponse, StreamingResponse
import asyncio
import time
import uuid
app = FastAPI()
templates = Jinja2Templates("templates")
# This object will store session id and their corresponding value, an async queue.
sessions = dict()
@app.get("/")
async def root(request: Request):
session_id = str(uuid.uuid4())
sessions[session_id] = asyncio.Queue()
return templates.TemplateResponse(request, "index.html", context={"session_id": session_id})
@app.post("/chat")
async def chat(request: Request, query: str=Form(...), session_id: str=Form(...)):
""" Send message to session-based queue """
# Create the session if it does not exist
if session_id not in sessions:
sessions[session_id] = asyncio.Queue()
# Put the message in the queue
await sessions[session_id].put(query)
return {"status": "queued", "session_id": session_id}
@app.get("/stream/{session_id}")
async def stream(session_id: str):
async def response_stream():
if session_id not in sessions:
print(f"Session {session_id} not found!")
return
queue = sessions[session_id]
# This BLOCKS until data arrives
print(f"Waiting for message in session {session_id}")
data = await queue.get()
print(f"Got message: {data}")
message = ""
await asyncio.sleep(1)
for token in data.replace("
", " ").split(" "):
message += token + " "
data = f"""data: <li class='mb-6 ml-[20%]'> <div class='font-bold text-right'>AI</div><div>{message}</div></li>
"""
yield data
await asyncio.sleep(0.03)
queue.task_done()
return StreamingResponse(response_stream(), media_type="text/event-stream")
下面解释几个关键概念。
会话隔离机制
确保每个用户拥有独立的消息队列至关重要,以避免不同对话之间产生混淆。实现这一目标的方法是使用会话字典。在实际的生产应用中,通常会使用Redis等工具来存储这些会话信息。在以下代码示例中,可以看到页面加载时会创建一个新的会话ID,并将其存储在sessions字典中。刷新页面将启动一个新的会话;虽然当前的消息队列没有持久化,但可以通过数据库等方式实现。该主题将在第三部分详细探讨。
# This object will store session id and their corresponding value, an async queue.
sessions = dict()
@app.get("/")
async def root(request: Request):
session_id = str(uuid.uuid4())
sessions[session_id] = asyncio.Queue()
return templates.TemplateResponse(request, "index.html", context={"session_id": session_id})
阻塞式协调机制
在SSE消息发送和用户查询接收之间,需要精确控制它们的顺序。在后端,正确的顺序应为:
- 接收用户消息。
- 创建消息队列并填充消息。
- 通过流式响应发送队列中的消息。
如果未能遵循这一顺序,可能会导致不希望发生的行为,例如,先读取(空的)消息队列,然后才用用户查询填充它。
控制执行顺序的解决方案是使用asyncio.Queue。此对象将用于两个关键场景:
- 当向队列中插入新消息时。插入消息将“唤醒”SSE接口中的轮询操作。
await sessions[session_id].put(query)- 当从队列中拉取消息时。在这行代码中,程序将阻塞,直到队列发出“有新数据可用!”的信号:
data = await queue.get()这种模式具有多项优势:
- 每个用户拥有独立的队列。
- 消除了竞态条件的风险。
流式传输模拟
在本文中,通过将用户查询拆分成单词并逐一返回这些单词,来模拟大型语言模型(LLM)的响应。在第三部分中,将实际接入一个真实的LLM。
流式传输通过FastAPI的StreamingResponse对象处理。此对象期望一个异步生成器,该生成器将持续yield数据直到生成器结束。必须使用yield关键字而非return关键字,否则生成器将在第一次迭代后停止。
接下来,将分解流式传输函数:
首先,需要确保当前会话有一个消息队列,以便从中拉取消息:
if session_id not in sessions:
print(f"Session {session_id} not found!")
return
queue = sessions[session_id]
接着,一旦获取了队列,如果队列中包含消息,将从队列中拉取消息;否则,代码将暂停并等待消息的到来。这是函数中最核心的部分:
# This BLOCKS until data arrives
print(f"Waiting for message in session {session_id}")
data = await queue.get()
print(f"Got message: {data}")
为了模拟流式传输,现在将消息分块为单词(此处称为tokens),并添加一些时间延迟(通过asyncio.sleep实现)来模拟大型语言模型(LLM)的文本生成过程。请注意,yield的数据实际上是HTML字符串,并被封装在一个以“data:”开头的字符串中。这是SSE消息的发送方式。也可以选择使用“event:”元数据来标记消息。例如:
event: my_custom_event
data: <div>Content to swap into your HTML page.</div>
下面展示如何在Python中实现它(对于追求完美的开发者,建议使用Jinja模板而非直接构建字符串来渲染HTML):
message = ""
# First pause to let the browser display "Thinking when the message is sent"
await asyncio.sleep(1)
# Simulate streaming by splitting message in words
for token in data.replace("
", " ").split(" "):
# We append tokens to the message
message += token + " "
# We wrap the message in HTML tags with the "data" metadata
data = f"""data: <li class='mb-6 ml-[20%]'><div class='font-bold text-right'>AI</div><div>{message}</div></li>
"""
yield data
# Pause to simulate the LLM generation process
await asyncio.sleep(0.03)
queue.task_done()
前端设计与实现
前端主要承担两项任务:向后端发送用户查询,以及在特定通道(即session_id)上监听SSE消息。为此,采用了“职责分离”的设计理念,即每个HTMX元素仅负责一项单一任务:
- 表单负责发送用户输入。
- SSE监听器负责处理流式传输。
- 聊天列表(ul)负责显示消息。
发送消息时,将使用表单中的标准textarea输入框。其HTMX的精妙之处在于:
<form
id="userInput"
class="flex max-h-16 gap-4"
hx-post="/chat"
hx-swap="none"
hx-trigger="click from:#submitButton"
hx-on::before-request="
htmx.find('#chat').innerHTML += `<li class='mb-6 justify-start max-w-[80%]'><div class='font-bold'>Me</div><div>${htmx.find('#query').value}</div></li>`;
htmx.find('#chat').innerHTML += `<li class='mb-6 ml-[20%]'><div class='font-bold text-right'>AI</div><div class='text-right'>Thinking...</div></li>`;
htmx.find('#query').value = '';
"
>
<textarea
id="query"
name="query"
class="flex w-full rounded-md border border-input bg-transparent px-3 py-2 text-sm shadow-sm placeholder:text-muted-foreground focus-visible:outline-none focus-visible:ring-1 focus-visible:ring-ring disabled:cursor-not-allowed disabled:opacity-50 min-h-[44px] max-h-[200px]"
placeholder="Write a message..."
rows="4"></textarea>
<button
type="submit"
id="submitButton"
class="inline-flex max-h-16 items-center justify-center rounded-md bg-neutral-950 px-6 font-medium text-neutral-50 transition active:scale-110"
>Sends</button>
</form>
回顾第一部分的文章,有几个值得解释的HTMX属性:
hx-post:表单数据将提交到的后端接口。hx-swap:设置为none,因为在此场景中,后端接口不返回任何数据。hx-trigger:指定哪个事件将触发请求。hx-on::before-request:这部分使用了少量JavaScript,旨在提升应用响应速度。它会将用户的请求添加到聊天列表中,并在等待SSE消息流式传输时向用户显示“正在思考…”的信息。这比让用户盯着空白页面等待要友好得多。
值得注意的是,实际上向后端发送了两个参数:用户的输入和会话ID。这样,消息将被插入到后端正确的队列中。
接着,定义了另一个专门用于监听SSE消息的组件。
<!-- Messages will be added to this list-->
<div class="mb-auto max-h-[80%] overflow-auto">
<ul id="chat" class="rounded-2xl p-4 mb-16 justify-start">
</ul>
</div>
<!-- SSE listened (message buffer)-->
<div
hx-ext="sse"
sse-connect="/stream/{{ session_id }}"
sse-swap="message"
hx-swap="outerHTML scroll:bottom"
hx-target="#chat>li:last-child"
style="display: none;"
></div>
该组件将监听/stream接口,并传递其会话ID,以仅监听此会话的消息。hx-target属性指示浏览器将数据添加到聊天列表的最后一个li元素中。hx-swap属性则指定数据实际上是为了替换整个当前的li元素。这就是流式传输效果的工作原理:用最新的消息片段替换当前显示的消息。
注意:也可以使用其他方法来替换DOM中的特定元素,例如带外(OOB)交换。它们的工作方式略有不同,因为需要一个特定的ID来在DOM中查找。在此案例中,特意没有为每个写入的列表元素分配ID。
集成Google Agent Development Kit,打造真正的聊天机器人
现在,是时候用一个真正的大型语言模型(LLM)替换之前模拟的流式传输接口了。为此,将利用Google ADK(Agent Development Kit)构建一个智能体,使其具备工具调用能力和记忆功能,从而能够获取实时信息并记住对话细节。
智能体(Agents)简介
读者可能已经了解大型语言模型(LLM)的概念。当前LLM的主要局限在于,它们本身无法获取实时信息:其知识储备仅限于训练时的数据。另一个局限是它们无法访问训练范围之外的信息(例如,公司内部数据)。
智能体(Agents)是一种能够进行推理、行动和观察的人工智能应用。推理部分由LLM(即“大脑”)负责,而智能体的“手”则被称为“工具”,可以有多种形式:
- Python函数,例如用于调用API。
- MCP服务器,这是一个允许智能体通过标准化接口连接到API的标准(例如,无需自行编写API连接器即可访问所有Gsuite工具)。
- 其他智能体(在这种情况下,这种模式被称为智能体委派,由一个路由或主智能体控制不同的子智能体)。
在本次演示中,为了简化实现,将使用一个非常简单的智能体,它只具备一个工具:Google搜索。这将使其能够获取最新信息,并确保信息的可靠性(至少希望Google搜索结果是可靠的)。
在Google ADK的生态中,智能体需要以下基本信息:
- 名称和描述,主要用于文档说明。
- 指令:定义智能体行为的提示词(工具使用、输出格式、遵循步骤等)。
- 工具:智能体为实现其目标可以使用的函数/MCP服务器/其他智能体。
此外,还有围绕记忆和会话管理的其他概念,但它们超出了本文的讨论范围。
接下来,定义智能体!
流式Google搜索智能体
from google.adk.agents import Agent
from google.adk.agents.run_config import RunConfig, StreamingMode
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.genai import types
from google.adk.tools import google_search
# Define constants for the agent
APP_NAME = "default" # Application
USER_ID = "default" # User
SESSION = "default" # Session
MODEL_NAME = "gemini-2.5-flash-lite"
# Step 1: Create the LLM Agent
root_agent = Agent(
model=MODEL_NAME,
name="text_chat_bot",
description="A text chatbot",
instruction="You are a helpful assistant. Your goal is to answer questions based on your knowledge. Use your Google Search tool to provide the latest and most accurate information",
tools=[google_search]
)
# Step 2: Set up Session Management
# InMemorySessionService stores conversations in RAM (temporary)
session_service = InMemorySessionService()
# Step 3: Create the Runner
runner = Runner(agent=root_agent, app_name=APP_NAME, session_service=session_service)
Runner对象充当用户与智能体之间的协调器。
接下来,重新定义/stream接口。首先检查智能体的会话是否存在,如果不存在则创建它:
# Attempt to create a new session or retrieve an existing one
try:
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
except:
session = await session_service.get_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
然后,获取用户查询,并以异步方式将其传递给智能体,以获取流式响应:
# Convert the query string to the ADK Content format
query = types.Content(role="user", parts=[types.Part(text=query)])
# Stream the agent's response asynchronously
async for event in runner.run_async(
user_id=USER_ID, session_id=session.id, new_message=query, run_config=RunConfig(streaming_mode=StreamingMode.SSE)
):
接下来有一个微妙之处。当智能体生成响应时,它可能会输出双换行符“
”。这会带来问题,因为SSE事件以这个符号作为结束标记。因此,字符串中出现双换行符意味着:
- 当前消息将被截断。
- 下一条消息格式将不正确,并可能导致SSE流停止。
读者可以自行尝试。为了解决这个问题,将使用一个小技巧,同时结合另一个小技巧来格式化列表元素(因为使用了Tailwind CSS,它会覆盖某些CSS规则)。这个技巧是:
if event.partial:
message += event.content.parts[0].text
# Hack here
html_content = markdown.markdown(message, extensions=['fenced_code']).replace("
", "<br/>").replace("<li>", "<li class='ml-4'>").replace("<ul>", "<ul class='list-disc'>")
full_html = f"""data: <li class='mb-6 ml-[20%]'> <div class='font-bold text-right'>AI</div><div>{html_content}</div></li>
"""
yield full_html
通过这种方式,可以确保双换行符不会中断SSE流。
以下是该路由的完整代码:
@app.get("/stream/{session_id}")
async def stream(session_id: str):
async def response_stream():
if session_id not in sessions:
print(f"Session {session_id} not found!")
return
# Attempt to create a new session or retrieve an existing one
try:
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
except:
session = await session_service.get_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
queue = sessions[session_id]
# This BLOCKS until data arrives
print(f"Waiting for message in session {session_id}")
query = await queue.get()
print(f"Got message: {query}")
message = ""
# Convert the query string to the ADK Content format
query = types.Content(role="user", parts=[types.Part(text=query)])
# Stream the agent's response asynchronously
async for event in runner.run_async(
user_id=USER_ID, session_id=session.id, new_message=query, run_config=RunConfig(streaming_mode=StreamingMode.SSE)
):
if event.partial:
message += event.content.parts[0].text
html_content = markdown.markdown(message, extensions=['fenced_code']).replace("
", "<br/>").replace("<li>", "<li class='ml-4'>").replace("<ul>", "<ul class='list-disc'>")
full_html = f"""data: <li class='mb-6 ml-[20%]'> <div class='font-bold text-right'>AI</div><div>{html_content}</div></li>
"""
yield full_html
queue.task_done()
return StreamingResponse(response_stream(), media_type="text/event-stream")
至此,读者将能够与自己的聊天机器人进行对话!
下面添加了一个小段CSS代码,用于格式化代码块。如果让聊天机器人生成代码片段,会希望它们能正确显示。这是CSS代码:
pre, code {
background-color: black;
color: lightgrey;
padding: 1%;
border-radius: 10px;
white-space: pre-wrap;
font-size: 0.8rem;
letter-spacing: -1px;
}
现在也可以生成代码片段了:
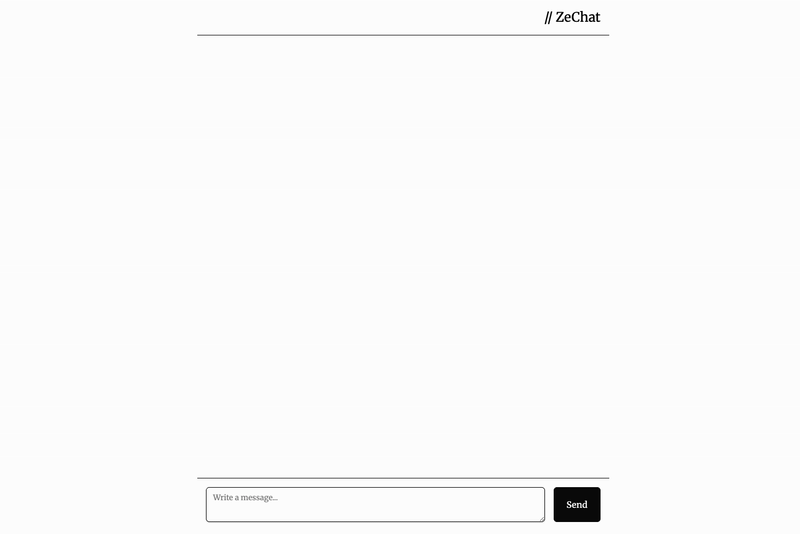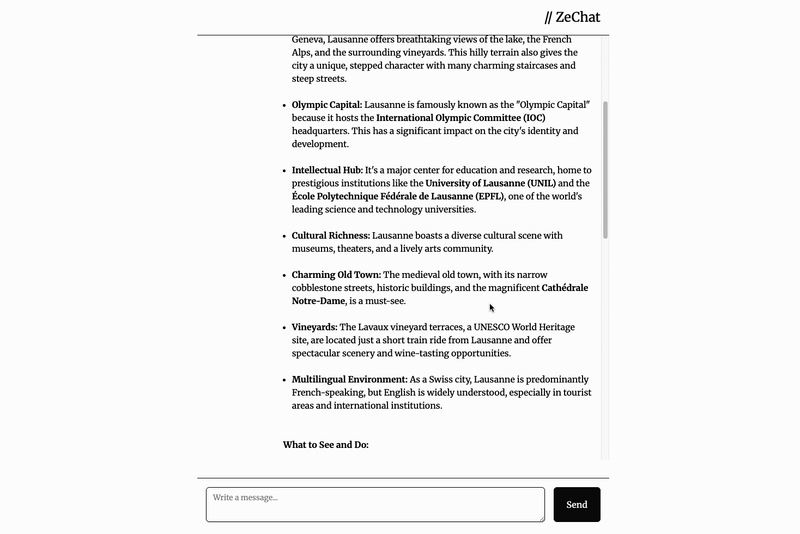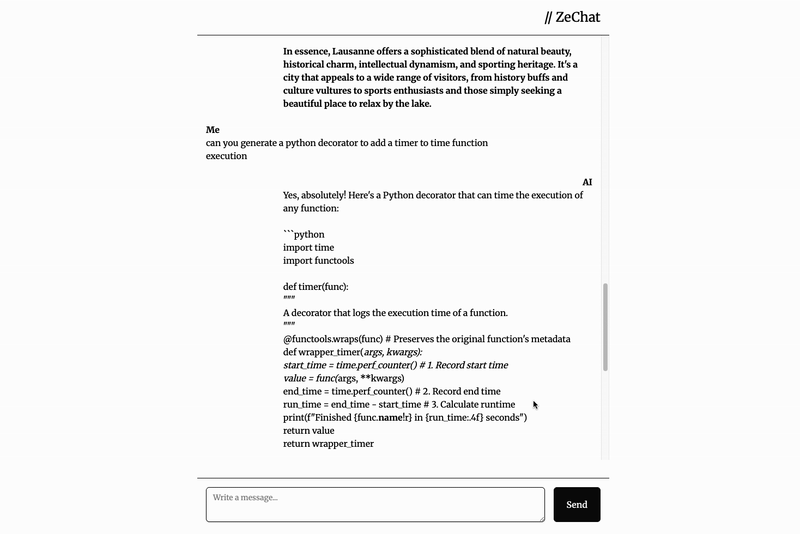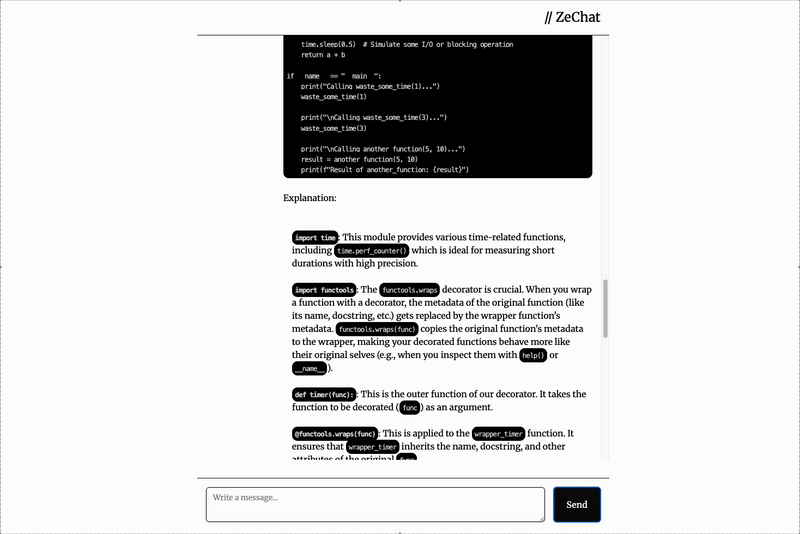
效果令人惊叹!
工作流程回顾
通过不到200行代码,就能够构建一个具有以下工作流程的聊天应用,实现服务器流式响应并利用SSE和HTMX进行优雅显示。
User types "Hello World" → Submit
├── 1. Add "Me: Hello World" to chat
├── 2. Add "AI: Thinking..." to chat
├── 3. POST /chat with message
├── 4. Server queues message
├── 5. SSE stream produces a LLM response based on the query
├── 6. Stream "AI: This" (replaces "Thinking...")
├── 7. Stream "AI: This is the answer ..."
└── 8. Complete
总结
在本系列文章中,展示了如何仅使用Python和HTML,在几乎不依赖JavaScript及重型JS框架的情况下,轻松开发一个聊天机器人应用。在神奇的HTMX库的帮助下,本文涵盖了服务器端渲染、服务器发送事件(SSE)、异步流式传输以及智能体等主题。
这些文章的主要目的是表明,Web应用程序开发对于非JavaScript开发者而言并非遥不可及。实际上,在Web开发中并非总是需要使用JavaScript,并且有充分的理由在某些情况下选择不使用它。尽管JavaScript是一种功能强大的语言,但有时它可能被过度使用,而忽略了更简单却同样健壮的方法。服务器端与客户端应用之间的争论由来已久且尚未平息,但希望这些文章能为一些读者带来启发,并最终有所收获。