

在信息爆炸的今天,高效的信息检索已成为至关重要的能力。每当使用搜索引擎查询或向ChatGPT提问时,都是在进行信息检索任务。检索范围既可以是封闭的文档数据集,也可以是整个互联网。
本文将深入探讨智能体信息检索技术,分析大语言模型(LLM)如何改变信息检索范式,特别是AI代理在此领域展现出的卓越能力。首先将介绍检索增强生成(RAG)这一基础技术,随后详细解析如何利用AI代理进行高效信息发现。
本信息图展示了文章核心内容。将探讨传统信息检索方法如TF-IDF(关键词搜索),深入分析RAG技术,并比较两种实现方式:使用嵌入模型和向量数据库的自建方案,以及托管式RAG服务。最后将阐述如何将关键词搜索和RAG作为工具集成到AI代理中。
智能体信息检索的必要性
信息检索作为一项相对成熟的技术,TF-IDF是最早用于大规模文档检索的算法。该算法通过分析特定文档中词汇的出现频率及其在整个文档集中的分布情况来建立索引。
当用户搜索某个词汇时,如果该词汇在少数文档中频繁出现,但在整个文档集中较为罕见,则表明这些文档具有高度相关性。
信息检索之所以关键,是因为人类在解决问题时极度依赖快速获取信息的能力。典型应用场景包括:
- 特定菜谱查询
- 算法实现方法
- 路径规划导航
尽管TF-IDF仍然表现优异,但如今已涌现出更强大的信息检索技术。检索增强生成(RAG)就是其中一种重要方法,它基于语义相似性来定位相关文档。
智能体信息检索综合运用关键词搜索(如TF-IDF的现代版本BM25)和RAG等技术,通过多维度检索相关文档并最终向用户返回精准结果。
自建RAG系统实战
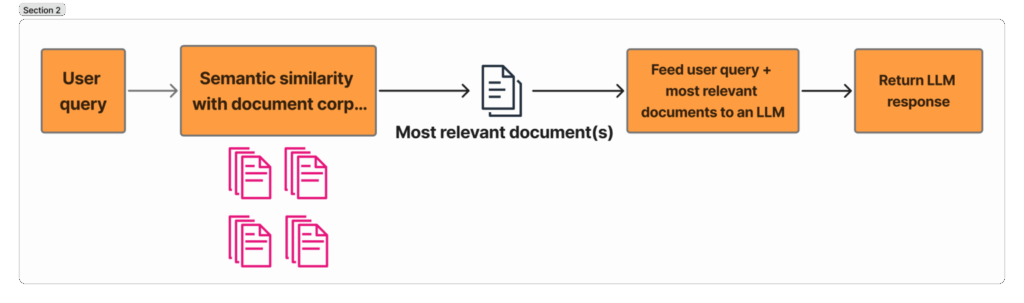
该图展示了RAG的工作机制:将文档查询进行嵌入处理,基于语义相似度从文档库中找出最相关的文档,然后将这些文档输入LLM,使其基于相关文档生成用户问题的答案。
借助现有技术工具,自建RAG系统出人意料地简单。虽然市场上有众多辅助实现RAG的软件包,但它们都基于相同的基础技术架构:
- 对文档库进行嵌入处理(通常需要先进行文档分块)
- 将嵌入向量存储至向量数据库
- 接收用户搜索查询
- 对搜索查询进行嵌入处理
- 计算文档库与用户查询的嵌入相似度,返回最相关文档
对于有经验的开发者,可在数小时内完成实现。常用的嵌入服务包括:
-
托管服务:
- OpenAI的text-embedding-large-3
- Google的gemini-embedding-001
-
开源选项:
- 阿里的qwen-embedding-8B
- Mistral的Linq-Embed-Mistral
完成文档嵌入后,可将其存储至以下向量数据库:
- Pinecone
- Weaviate
- Milvus
至此,RAG系统已基本就绪。下一节将介绍全托管RAG解决方案,用户只需上传文档,系统即可自动完成分块、嵌入和搜索全过程。
托管RAG服务详解
若追求更简化的方案,可选择全托管RAG服务。主流选项包括:
- Ragie.ai
- Gemini文件搜索工具
- OpenAI文件搜索工具
这些服务极大简化了RAG流程。用户只需上传原始文档并提供搜索查询,服务即可自动处理分块、嵌入和推理全过程,最终返回相关文档供LLM生成答案。
尽管托管RAG显著简化了流程,但也存在一些局限性:
虽然支持直接上传PDF文件,但某些文件类型(如PNG/JPG)可能不受支持。解决方案是对图像进行OCR处理,生成支持的文本格式文件,但这会增加应用复杂度,违背使用托管服务的初衷。
另一个挑战是数据合规性。上传原始文档时需要确保符合相关法规(如欧盟GDPR)。虽然部分服务(如OpenAI)支持欧盟数据驻留,但这仍是选择托管服务时的重要考量因素。
以下以OpenAI文件搜索工具为例演示具体使用方法:
首先创建向量存储并上传文档:
from openai import OpenAI
client = OpenAI()
# 创建向量存储
vector_store = client.vector_stores.create(
name="<你的向量存储名称>",
)
# 上传文件并添加到向量存储
client.vector_stores.files.upload_and_poll(
vector_store_id=vector_store.id,
file=open("文件名.txt", "rb")
)
完成文档上传和处理后,即可进行查询:
用户查询 = "生命的意義是什麼?"
结果 = client.vector_stores.search(
vector_store_id=vector_store.id,
query=用户查询,
)
可见,此代码比自建嵌入模型和向量数据库的方案简洁得多。
信息检索工具集成策略
在准备好信息检索工具后,即可开始实施智能体信息检索。首先介绍LLM信息检索的初始方法,随后探讨更优的升级方案。
先检索后回答模式
第一种方法是先检索相关文档,然后将这些信息输入LLM生成答案。可通过同时运行关键词搜索和RAG搜索,获取前X个相关文档,并将其输入LLM。
首先通过RAG查找文档:
用户查询 = "生命的意義是什麼?"
RAG结果 = client.vector_stores.search(
vector_store_id=vector_store.id,
query=用户查询,
)
然后进行关键词搜索:
def 关键词搜索(查询):
# 关键词搜索逻辑...
return 结果
关键词搜索结果 = 关键词搜索(查询)
合并搜索结果,去除重复文档,将文档内容输入LLM生成回答:
def LLM补全(提示词):
# LLM补全逻辑
return 响应
提示词 = f"""
根据以下上下文:{文档上下文}
回答用户查询:{用户查询}
"""
响应 = LLM补全(提示词)
这种方法在多数情况下效果良好,能提供高质量回答。但存在更先进的智能体信息检索方案。
工具化信息检索函数
新一代LLM均以智能体行为为目标进行训练,具备出色的工具使用能力。通过向LLM提供工具列表,它能自主决定何时使用这些工具来回答用户查询。
因此,更优方案是将RAG和关键词搜索作为工具提供给LLM。以GPT-5为例:
# 定义自定义关键词搜索函数,向GPT-5提供关键词搜索和RAG工具
def 关键词搜索(关键词):
# 执行关键词搜索
return 结果
用户输入 = "生命的意義是什麼?"
工具列表 = [
{
"type": "function",
"function": {
"name": "关键词搜索",
"description": "搜索关键词并返回相关结果",
"parameters": {
"type": "object",
"properties": {
"keywords": {
"type": "array",
"items": {"type": "string"},
"description": "要搜索的关键词"
}
},
"required": ["keywords"]
}
}
},
{
"type": "file_search",
"vector_store_ids": ["<向量存储ID>"],
}
]
响应 = client.responses.create(
model="gpt-5",
input=用户输入,
tools=工具列表,
)
这种方法的优势在于:
- 智能体自主决定工具使用时机,某些查询可能不需要向量搜索
- OpenAI自动进行查询重写,基于用户查询生成不同版本并行执行RAG查询
- 当智能体认为信息不足时,可决定执行更多RAG查询或关键词搜索
最后一点对智能体信息检索最为关键。当初始查询未能找到所需信息时,智能体(如GPT-5)能够判断这种情况,并决定发起更多RAG或关键词搜索。这显著提升了检索效果,使智能体更有可能找到目标信息。
总结
本文系统介绍了智能体信息检索的基础知识。首先阐述了智能体信息检索的重要性,强调了人类对快速获取信息的依赖性。随后详细分析了关键词搜索和RAG等检索工具的使用方法。最后比较了两种实现方式:静态运行工具后输入LLM的方案,以及将工具赋予LLM使其成为智能信息检索体的更优方案。可以预见,智能体信息检索将在未来发挥越来越重要的作用,掌握AI代理的使用技巧将成为构建强大AI应用的关键能力。





